
68-95-99.7 Rule: Definition and Implementation
68-95-99.7 Rule or the empirical rule is based on mean and standard deviation. It is a shorthand for remembering percentage of values lying within interval estimate in the normal distribution.

68-95-99.7 rule is an Empirical Rule followed by all the data following a normal distribution. Through this article, you will learn about the rule in detail.
Table of Contents
In order to understand the 68-95-99.7 rule let’s first understand the normal distribution with the below scenario:

- This is Jimmy
- Jimmy is an average 40-year Software Engineer
- He works 40hrs per week
- Jimmy earns 1.5lakh rupee per month
Now here’s the question:
Q: How often do you think that you are going to meet someone who earns 5x that of Jimmy?
Q: How often do you think you are going to meet a person who works 5x more per week?
Well, the answer will definitely differ from the kind of data you are looking at. It might be possible that 5x greater than average is common.
What is Normal Distribution?
Normal Distribution or Gaussian Distribution is defined as a symmetrical bell-shaped curve. The peak of the curve denotes the average of the data points. When compiled and graphed, many continuous large datasets in nature exhibit this bell-shaped curve.
Let’s check out some of the common examples of simple data following Normal Distribution:
Height of Person
The population’s height is an example of normal distribution. The majority of persons in a given population are of average height. The number of persons who are taller and shorter than the average height is almost equal, and only a few people are either extraordinarily tall or extremely short. As a result, when we plot the height of all the people in the world, the graph will follow a bell-shaped curve denoting the normal distribution.
Explore normal distribution certifications
Rolling a Dice
A fair dice (more than 1 dice) roll also creates a bell-shaped curve denoting normal distribution. The normal distribution graph will become increasingly sophisticated as the number of dice increases.
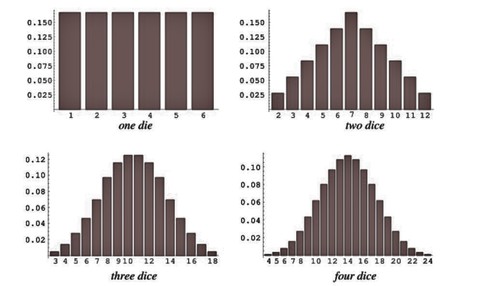
Similarly, there are many more things in the world that follow this distribution:
- IQ of a population sample
- Income Distribution In Econom
- Performance of employees in the company
- Shoe size of a person
- Birth weight of a population, and many more
Learn more about normal distribution
Best-suited Statistics for Data Science courses for you
Learn Statistics for Data Science with these high-rated online courses

Understanding 68-95-99.7 Rule
After the observation of multiple normal distribution curves, statisticians found a common pattern in the data. They observed that all the data showed some pattern at 68%, 95%, and 99.5%. Since this was a common observation in all the normal distribution graphs, it became a rule and we call it the Empirical Rule of Normal Distribution (also known as the 68-95-99 rule).
In other words, the Empirical Rule is a rule based on experience and observation. It gives how much of the data lies within one, two, or three standard deviations of the mean.
The 68–95–99.7 was first discovered and named by Abraham de Moivre in 1733 during his experimentation of flipping 100 fair coins. This term was coined 75 years before the normal distribution model even was introduced.
Let’s understand this 68-95-99.7 rule more clearly,
As per Empirical Rule:
- 68% of observed data points lie within one standard deviation of the mean
- 95% fall within two standard deviations, and
- 99.7% occurs within three standard deviations.
The empirical rule is also known as three-sigma because practically all data fall within the three standard deviations. This rule establishes both upper and lower bounds of a statistical chart at +/- three standard deviations. Since 99.7 percent of all numbers fall inside it, this limit is also used to identify the outliers. All the data points which lie beyond +/- 3 standard deviations are considered an outlier.
Learn What is an outlier?
Implementing the 68-95-99.7 Rule using Python
Let us now understand the implementation of this empirical rule using Python:
import matplotlib.pyplot as pltimport numpy as npfrom scipy.stats import norm # setting the values of# mean and Standard Deviationmean = 0SD = 1 # value of Cumulative distribution function (cdf) # between one, two and three S.D. around the mean one_sd = norm.cdf(SD, mean, SD) - norm.cdf(-SD, mean, SD)two_sd = norm.cdf(2 * SD, mean, SD) - norm.cdf(-2 * SD, mean, SD)three_sd = norm.cdf(3 * SD, mean, SD) - norm.cdf(-3 * SD, mean, SD) # printing the value of fractions print("Values within 1 SD =", one_sd)print("Values within 2 SD =", two_sd)print("Values within 3 SD =", three_sd)
Output:
Values within 1 SD = 0.6826894921370859Values within 2 SD = 0.9544997361036416Values within 3 SD = 0.9973002039367398
The above output clearly verifies the empirical rule by denoting the fraction of values within 1, 2, and 3 Standard Deviation.
Conclusion
This observation of 68-95-99.7 is a rule because it is universally accepted for all the data following a normal distribution curve. The important part is to figure out whether or not your data follow a normal distribution or not.

This is a collection of insightful articles from domain experts in the fields of Cloud Computing, DevOps, AWS, Data Science, Machine Learning, AI, and Natural Language Processing. The range of topics caters to upski... Read Full Bio