
Adding Columns to Pandas DataFrame
Learn how to effortlessly expand your Pandas DataFrame’s functionality by mastering the art of adding new columns. Explore strategies for inserting, transforming, and populating new columns to suit your analysis needs.

Pandas DataFrames are tabular data structures that store data similar to an Excel or CSV file – in rows and columns. The below article covers Adding Columns to Pandas DataFrame.
During analysis, you perform several operations on a DataFrame using the functions provided in Pandas. We have already learned how to append rows to a Pandas DataFrame. In this article, we will learn how to add columns to Pandas DataFrame using four methods – assign(), insert(), concat() and apply().
We are going to cover the following sections:
- Adding a column using List
- Adding a column using Pandas Series
- Adding columns using assign()
- Adding a column using insert()
- Adding a column using concat()
- Adding a column using apply()
- Adding an empty column
- Adding a column with a constant value
- Endnotes
For our purpose today, let’s create a sample DataFrame as shown below:

Our dummy dataset comprises of 5 columns – ‘id’, ‘age’, ‘gender’, ‘group’, and ‘math marks’. As you can observe, it contains both numerical and categorical variables.
Let’s see how we perform the operations to add column(s) to this dataset.
Adding a column using List
The simplest way to add a column to an existing DataFrame is to create a list and assign it to a new column.

Adding a column using Pandas Series
A single column is nothing but a Pandas Series – that is a 1D homogenous array.
You can simply assign the values of your Series into the existing DataFrame to add a new column:

Note that if the new column indices do not match those of the DataFrame, then NaN values are assigned to those indices:

Adding columns using assign()
You can use the assign() function to insert multiple new columns in a DataFrame when:
- Index of the new column can be ignored
- Values of an existing column need to be overwritten
This method returns a new DataFrame object, that is a copy of the DataFrame, containing all the original columns along with the new ones.
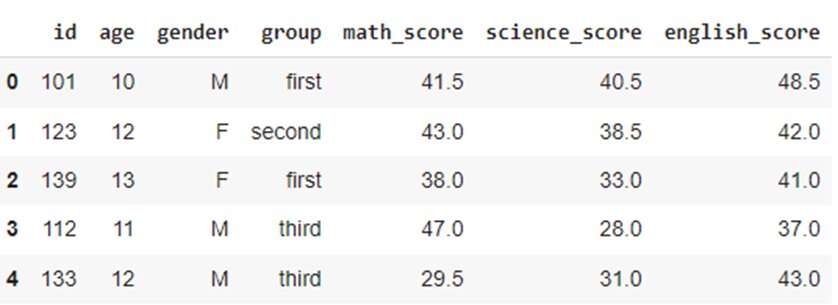
Adding a column using insert()
You can use the insert() function when you need to insert a new column in a specific position or index.

What if you wanted to insert the english_score before the math_score?

Best-suited Python courses for you
Learn Python with these high-rated online courses

Adding duplicate columns using insert()
The allow_duplicates parameter is set to False by default and returns a ValueError if the new column has a duplicate column name.

As you can observe, there are two english_score columns in the above DataFrame.
Adding a column using concat()
You can concatenate a new column to an existing DataFrame by setting axis=1. The output would be a new DataFrame with the concatenated column.

Adding a column using apply()
When performing data manipulation, you might need to add a new column based on the values in the existing column(s). For this, apply() method can be used as shown:
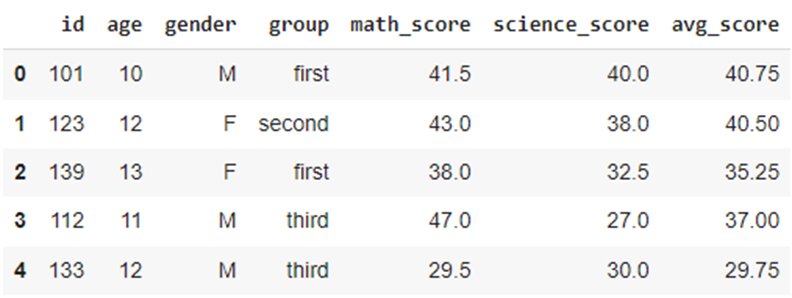
As shown in the above DataFrame, we have calculated the average score based on the math_score and science_score columns using the lambda function.
Setting axis=1 ensures that apply() method works at the column level.
Adding an empty column
You can also add an empty column to the DataFrame by assigning a new column with the pd.NaT. Let’s add an empty column to our original DataFrame:
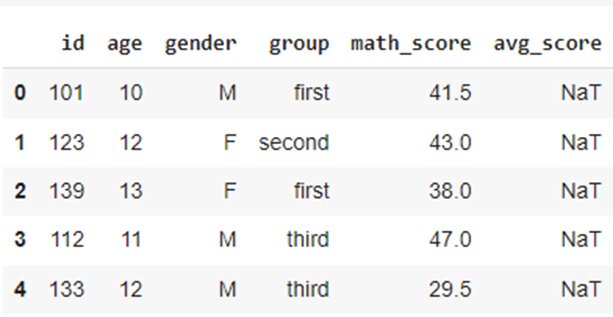
pd.NaT denotes missing or null values in the Pandas DataFrame.
Adding a column with a constant value
You can assign a single value to all elements in a new column, as shown:

Endnotes
When inserting new columns to your Pandas DataFrame, you must pick the most suitable method based on your requirement. Pandas is a very powerful data processing tool and provides a rich set of functions to process and manipulate data for analysis. If you seek to learn the basics and various functions of Pandas, you can explore related articles here.
———————————————————————————————————————
Top Trending Tech Articles:Career Opportunities after BTech Online Python Compiler What is Coding Queue Data Structure Top Programming Language Trending DevOps Tools Highest Paid IT Jobs Most In Demand IT Skills Networking Interview Questions Features of Java Basic Linux Commands Amazon Interview Questions
Contributed by – Prerna Singh

This is a collection of insightful articles from domain experts in the fields of Cloud Computing, DevOps, AWS, Data Science, Machine Learning, AI, and Natural Language Processing. The range of topics caters to upski... Read Full Bio