
Data Science Interview Questions and Answers for 2024
Data has become the raw material for businesses, and vast amounts of structured and unstructured information are increasingly used to create a new form of economic value for businesses of every size. In this sense, Data Science is the field of study where collective processes, theories, and technologies are combined to allow the review, analysis, and extraction of valuable knowledge and information from hard data. With the market growing leaps and bounds, there is a significant dearth of skilled data scientists who can help businesses sift through an overabundance of data and come up with meaningful insights.
So, if you are planning to become a data scientist, you need to prepare well and create a fabulous impression on your prospective employers with your knowledge. This write-up provides some important data science interview questions and answers to help you crack your data science interview.

To learn more about data science, read our blog on – What is data science?
The article is segmented on different data science topics–
- Data Science Interview Questions
- Statistical Interview Questions
- Programming Language Interview Questions
- Machine Learning Interview Questions
Data Science Interview Questions
Q. How to deal with an unbalanced credit card fraud dataset in a binary classification problem?
A bank issues credit cards to its customers. Now when they checked their data, they found that some fraudulent transactions were going on. They found that for every 1000 transactions, there are at least 20 frauds. So, the number of frauds per 100 transactions is less than 2%, or we can say more than 98% of transactions is “No Fraud” in nature. If you look at the dataset here, the class “No Fraud” is called the majority class, and the smaller “Fraud” class is called the minority class. If you use this dataset as it is it will overfit your model with majority class and will not be able to detect the fraud class. The trained model will always predict no fraud for any given data.
So, how will you deal with this case?
- Delete random rows of data from the majority class to keep it in a relevant proportion to the minority class data. This is under-sampling. However, this will drastically reduce the size of the training dataset. And your model won’t be trained on a lot of important data.
- Increase the number of data points for the minority class. Here, you can use KNN to generate more data points synthetically. This technique of oversampling the minority class is known as the Synthetic Minority Oversampling Technique (SMOTE).
- Create multiple subsets of majority class data for the same minority class or oversampled class and use the ensemble method of bagging to train and combine each model’s vote.
- We can use ROC and precision-recall curves to find the optimal threshold for the classifier. We can also use a grid search method or search within a set of values.
- When dealing with imbalanced data, use the harmonic mean of precision and recall, which is nothing but—f1-score—as the metric.
Q. Explain the data preprocessing techniques you will apply before using the data to train your model.
Data Processing is an important step while training or building your model. Without quality data, the model's predictions will always be rubbish. What can you preprocess and clean your data before training your model?
- Remove duplicate entries from your data.
- Check and remove the outlier from the dataset. Having an outlier in the data might result in poor model training.
- Remove null values from the data.
- Split the dataset column into an independent set of variables (X)and a dependent variable.
- Randomly split the dataset rows into training and testing data using sklearn train-test-split
- Check the number of classes in the dataset. Check if the data is imbalanced.
- Normalize the numerical data points in your dataset
Q. Why is data normalization necessary for Machine Learning models?
Normalization is often applied to numeric columns during the data preprocessing step of machine learning. It keeps the values of numeric columns on a common scale without distorting the difference in the range of values. Not every dataset will require normalization. It is used only when features have different ranges.
For example, consider a dataset having two features: age(x1) and experience (x2). Age lies in the range of 0-100, while income is completely different, 0-50000 and higher. Income is 1000x greater than age. These two features have different ranges. If you use multiple linear regression, in this case, the influence of income will be greater because of its larger value. This doesn’t imply that it is the more important independent variable.
This question is among the basic data science interview questions and you must prepare for such questions.
Q. How will you validate a multiple regression model?
Adjusted R Square metrics helps in validating a multiple regression model. R square tells about how the fitness of data around the regression line. Whenever you add an extra independent variable, the R-squared value will always increase. Therefore, a model with multiple independent variables may seem to fit better even if it isn’t, and this is where R2 won’t be of help, and this is where adjusted R square comes into the picture. The value of the adjusted R square increases only if the additional variable has a higher correlation with the dependent variable and improves the model's accuracy.
Q. Are 20 small better than 1 large decision tree – Explain.
You can rephrase this question as, “Is a random forest model better than a decision tree?” And yes, since a random forest uses an ensemble method to collect the votes of multiple weak decision trees to make a strong learner. Random forests are more accurate and help avoid overfitting, as they combine multiple decision trees.
You may also be interested in exploring:
Q. What is the significance of a box plot?
A box and whisker plot – also known as a box plot, is used to show the spread and centres (mean) of a data set. It is also used to detect outliers dataset. It shows the dispersion of data across the mean. It summarizes the result as the minimum, first quartile, median, third quartile, and maximum. In a box plot, we draw a box from the first quartile to the third quartile. A vertical line goes through the box at the median. The whiskers go from each quartile to the minimum or maximum.
- Minimum – Minimum value in the dataset excluding the outliers
- First Quartile (Q1) – 25% of the data lies below the First (lower) Quartile.
- Median (Q2) – Mid-point of the dataset. Half of the values lie below it and half above.
- Third Quartile (Q3) – 75% of the data lies below the Third (Upper) Quartile.
- Maximum – Maximum value in the dataset excluding the outliers.
- Interquartile Range: 50% of the data lies in this range
Q. What is the difference between data science and big data?
Ans. The common differences between data science and big data are –
| Big Data |
Data Science |
| Large collection of data sets that cannot be stored in a traditional system | An interdisciplinary field that includes analytical aspects, statistics, data mining, machine learning, etc. |
| Popular in the field of communication, purchase and sale of goods, financial services, and educational sector | Common applications are digital advertising, web research, recommendation systems (Netflix, Amazon, Facebook), and speech and handwriting recognition applications. |
| Big Data solves problems related to data management and handling and analyze insights, resulting in informed decision-making | Data Science uses machine learning algorithms and statistical methods to obtain accurate predictions from raw data. |
| Popular tools are Hadoop, Spark, Flink, NoSQL, Hive, etc. | Popular tools are Python, R, SAS, SQL, etc. |
Q. Suppose you are given survey data and some data is missing. How would you deal with missing values from that survey?
Ans. This is among the important data science interview questions. There are two main techniques for dealing with missing values –
Debugging Techniques – It is a Data Cleaning process consisting of evaluating the quality of the information collected and increasing its quality in order to avoid lax analysis. The most popular debugging techniques are –
Searching the list of values: It is about searching the data matrix for values outside the response range. These values can be considered as missing, or the correct value can be estimated from other variables.
Filtering questions: They compare the number of responses from one filtered category to another. If any anomaly is observed that cannot be solved, it will be considered a lost value.
Checking for Logical Consistencies: The answers that may be considered contradictory are checked.
Counting the Level of Representativeness: A count is the number of responses obtained in each variable. If the number of unanswered questions is very high, it is possible to assume equality between the answers and the non-answers or to make an imputation of the non-answer.
- Imputation Technique
This technique replaces the missing values with valid values or answers by estimating them. There are three types of imputation:
- Random imputation
- Hot Deck imputation
- Imputation of the mean of subclasses
Q7. Which is better – good data or good models?
Ans. Good data is definitely more important than good models. The quality of data helps build a good model. The model’s accuracy will improve if the quality of data fed to it is better. This is why data preprocessing is an important step before training the model.
Q8. What are Recommender Systems?
Ans. Recommender systems are a subclass of information filtering systems that predict how users rate or score particular objects (movies, music, merchandise, etc.). They filter large volumes of information based on the data provided by a user and other factors and consider the user’s preferences and interests.
Recommender systems utilize algorithms that optimize the analysis of the data to build the recommendations. They ensure high efficiency as they can associate elements of our consumption profiles, such as purchase history, content selection, and even our hours of activity, to make accurate recommendations.
To learn more about the job profile and responsibilities of a Data Scientist, refer to this article: What is a Data Scientist?
Q9. What are the different types of Recommender Systems?
Ans. There are three main types of Recommender systems.
Collaborative filtering – Collaborative filtering is a method of making automatic predictions by using the recommendations of other people. There are two types of collaborative filtering techniques –
- User-User collaborative filtering
- Item-Item collaborative filtering
Content-Based Filtering– Content-based filtering is based on the description of an item and a user’s choices. As the name suggests, it uses content (keywords) to describe the items, and the user profile is built to state the type of item this user likes.

Image – Collaborative filtering & Content-based filtering
Hybrid Recommendation Systems - Hybrid Recommendation engines combine diverse rating and sorting algorithms. They can precisely recommend a wide range of products to consumers based on their history and preferences.
Click Here: How tech giants like Google, Facebook, Instagram are using your data.
Q10. Differentiate between wide and long data formats.
Ans. In a wide format, categorical data are always grouped.
The long data format has a number of instances with many variables and subject variables.
Q11. What are Interpolation and Extrapolation?
Ans. Interpolation – This is the method to guess data points between data sets. It is a prediction between the given data points.
Extrapolation – This is the method to guess data point beyond data sets. It is a prediction beyond given data points.
Also Read>>Skills That Employers Look For In a Data Scientist
Q12. How much data is enough to get a valid outcome?
Ans. All the businesses are different and measured in different ways. Thus, you never have enough data and there will be no right answer. The amount of data required depends on the methods you use to have an excellent chance of obtaining vital results.
Q13. What is the difference between ‘expected value’ and ‘average value’?
Ans. When it comes to functionality, there is no difference between the two. However, they are used in different situations.
An expected value usually reflects random variables, while the average value reflects the population sample.
Click Here: Measures of Central Tendency: Mean, Median and Mode
Q14. What happens if two users access the same HDFS file simultaneously?
Ans. This is a bit of a tricky question. The answer is not complicated, but it is easy to be confused by the similarity of programs’ reactions.
When the first user accesses the file, the second user’s inputs will be rejected because HDFS NameNode supports exclusive write.
Q15. What is power analysis?
Ans. Power analysis allows the determination of the sample size required to detect an effect of a given size with a given degree of confidence.
Q16. Is it better to have too many false negatives or false positives?
Ans. This is among the most popular data science interview questions and will depend on how you present your viewpoint. Give examples
These are some of the popular data science interview questions. Always be prepared to answer all types of data science interview questions, whether they relate to technical skills, interpersonal relationships, leadership, or methodologies. If you have recently started your career in Data Science, you can always get certified to improve your skills and boost your career opportunities.
Click Here: Confusion Matrix in Machine Learning.
Best-suited Data Science courses for you
Learn Data Science with these high-rated online courses

Statistics Interview Questions
Q17. What is the importance of statistics in data science?
Ans. Statistics help data scientists to get a better idea of a customer’s expectations. Using statistical methods, data Scientists can learn about consumer interest, behaviour, engagement, retention, etc. It also helps to build robust data models to validate certain inferences and predictions.
Click Here: Basics of Statistics for Data Science
Q18. What are the different statistical techniques used in data science?
Ans. There are many statistical techniques used in data science, including –
The arithmetic mean – It is a measure of the average of a set of data
Graphic display – Includes charts and graphs to visually display, analyze, clarify, and interpret numerical data through histograms, pie charts, bars, etc.
Correlation – Establishes and measures relationships between different variables.
Regression – Allows identifying if the evolution of one variable affects others.
Time series – It predicts future values by analyzing sequences of past values.
Data mining and other Big Data techniques to process large volumes of data
Sentiment analysis – It determines the attitude of specific agents or people towards an issue, often using data from social networks
Semantic analysis – It helps to extract knowledge from large amounts of texts
A / B testing – To determine which of two variables works best with randomized experiments
Machine learning using automatic learning algorithms to ensure excellent performance in the presence of big data
Check Out Our Data Science Courses
Q19. What is an RDBMS? Name some examples for RDBMS?
Ans. This is among the most frequently asked data science interview questions.
A relational database management system (RDBMS) is a database management system that is based on a relational model.
Some examples of RDBMS are MS SQL Server, IBM DB2, Oracle, MySQL, and Microsoft Access.
Interviewers often ask such data science interview questions and you must prepare for such abbreviations.
Click Here: What is the difference between DBMS and RDBMS?
Q20. What are a Z test, Chi-Square test, F test, and T-test?
Ans. Z test is applied for large samples. Z test = (Estimated Mean – Real Mean)/ (square root real variance / n).
Chi-Square test is a statistical method assessing the goodness of fit between a set of observed values and those expected theoretically.
F-test is used to compare 2 populations’ variances. F = explained variance/unexplained variance.
T-test is applied for small samples. T-test = (Estimated Mean – Real Mean)/ (square root Estimated variance / n).
Q21. What does P-value signify about the statistical data?
Ans. The p-value is the probability for a given statistical model that, when the null hypothesis is true, the statistical summary would be the same or more extreme than the actual observed results.
When,
P-value>0.05 denotes weak evidence against the null hypothesis, which means the null hypothesis cannot be rejected.
P-value <= 0.05 denotes strong evidence against the null hypothesis, which means the null hypothesis can be rejected.
P-value=0.05is the marginal value indicating it is possible to go either way
Q22. Differentiate between univariate, bivariate, and multivariate analysis.
Ans. Univariate analysis is the simplest form of statistical analysis where only one variable is involved.
Bivariate analysis is where two variables are analyzed and in multivariate analysis, multiple variables are examined.
Q23. What is association analysis? Where is it used?
Ans. Association analysis is the task of uncovering relationships among data. It is used to understand how the data items are associated with each other.

 Read Later
Read Later
Q24. What is the difference between squared error and absolute error?
Ans. Squared error measures the average of the squares of the errors or deviations—that is, the difference between the estimator and the estimated value.
Absolute error is the difference between the measured or inferred value of a quantity and its actual value.
Q25. What is an API? What are APIs used for?
Ans. API stands for Application Program Interface and is a set of routines, protocols, and tools for building software applications.
With API, it is easier to develop software applications.
Q26. What is Collaborative filtering?
Ans. Collaborative filtering is a method of making automatic predictions by using the recommendations of other people.
Q27. Why do data scientists use combinatorics or discrete probability?
Ans. It is used because it is useful in studying any predictive model.
Q28. What do you understand by Recall and Precision?
Ans. Precision is the fraction of relevant instances retrieved, while Recall is the fraction of retrieved instances.
Become Machine Learning Expert Now>>
Q29. What is market basket analysis?
Ans. Market Basket Analysis is a modeling technique based upon the theory that if you buy a certain group of items, you are more (or less) likely to buy another group of items.
Q30. What is the central limit theorem?
Ans. The central limit theorem states that the distribution of an average will tend to be Normal as the sample size increases, regardless of the distribution from which the average is taken except when the moments of the parent distribution do not exist.
Q31. Explain the difference between type I and type II errors.
Ans. Type I error is the rejection of a true null hypothesis or false-positive finding, while Type II error is the non-rejection of a false null hypothesis or false-negative finding.
Q32. What is Linear Regression?
Ans. It is one of the most commonly asked networking interview questions.
Linear regression is the most popular type of predictive analysis. It is used to model the relationship between a scalar response and explanatory variables.
Q33. What are the limitations of a Linear Model/Regression?
Ans.
- Linear models are limited to linear relationships, such as dependent and independent variables.
- Linear regression looks at a relationship between the mean of the dependent variable and the independent variables, and not the extremes of the dependent variable.
- Linear regression is sensitive to univariate or multivariate outliers.
- Linear regression tends to assume that the data are independent.
Q34. What is the goal of A/B Testing?
Ans. A/B testing is a comparative study in which two or more page variants are presented to random users, and their feedback is statistically analyzed to determine which variation performs better.
Q35. What is the main difference between overfitting and underfitting?
Ans. Overfitting – A statistical model describes any random error or noise that occurs when a model is super complex. An overfit model has poor predictive performance as it overreacts to minor fluctuations in training data.
Underfitting – In underfitting, a statistical model cannot capture the underlying data trend. This type of model also shows poor predictive performance.
Q36. What is a Gaussian distribution, and how is it used in data science?
Ans. A Gaussian distribution, commonly known as a bell curve, is a common probability distribution curve.


Q37. Explain the purpose of group functions in SQL. Cite certain examples of group functions.
Ans. Group functions provide summary statistics of a data set. Some examples of group functions are –
a) COUNT
b) MAX
c) MIN
d) AVG
e) SUM
f) DISTINCT
Q38. What is Root Cause Analysis?
Ans. A Root Cause is defined as a fundamental failure of a process. A systematic approach, known as Root Cause Analysis (RCA), has been devised to analyze such issues. This method addresses a problem or an accident and gets to its “root cause.”
Q39. What is the difference between a Validation Set and a Test Set?
Ans. The validation set is used to minimize overfitting. This is used in parameter selection, which means that it helps to
verify any accuracy improvement over the training data set. Test Set is used to test and evaluate the performance of a trained Machine Learning model.
Q40. What is the Confusion Matrix?
Ans. The confusion matrix is a very useful tool for assessing the quality of a machine learning classification model. It is also known as an error matrix and can be presented as a summary table to evaluate the performance of a classification model. The number of correct and incorrect predictions is summarized with the count values and broken down by class.
The confusion matrix serves to show explicitly when one class is confused with another, which allows us to work separately with different types of errors.
Structure of a 2×2 Confusion Matrix

Positive (P): The observation is positive (for example, it is a dog)
Negative (N): The observation is not positive (for example, it is not a dog)
True Positive (TP): Result in which the model correctly predicts the positive class
True Negative (TN): Result where the model correctly predicts the negative class
False Positive (FP): Also called a type 1 error, a result where the model incorrectly predicts the positive class when it is actually negative
False Negative (FN): Also called a type 2 error, a result in which the model incorrectly predicts the negative class when it is actually positive
Q41. What is the p-value?
Ans. A p-value, a number between 0 and 1, helps to determine the strength of results in a hypothesis test.
Q42. What is the difference between Causation and Correlation?
Ans. Causation denotes any causal relationship between two events and represents its cause and effects.
Correlation determines the relationship between two or more variables.
Causation necessarily denotes the presence of correlation, but correlation doesn’t necessarily denote causation.
Q43. What is cross-validation?
Ans. Cross-validation is a technique for assessing a model's performance on a new independent dataset. One example of cross-validation is splitting the data into two groups: training and testing data, where you use the testing data to test the model and training data to build the model.
Q44. What do you mean by logistic regression?
Ans. Also known as the logit model, logistic regression is a technique to predict the binary result from a linear amalgamation of predictor variables.
Q45. What is ‘cluster sampling’?
Ans. Cluster sampling is a probability sampling technique in which the researcher divides the population into separate groups called clusters. Then, a simple cluster sample is selected from the population. The researcher analyzes data from the sample pools.
Q46. What happens if two users access the same HDFS file simultaneously?
Ans. This is a bit of a tricky question. The answer itself is not complicated, but the similarity of programs’ reactions can make it easy to get confused.
When the first user accesses the file, the second user’s inputs will be rejected because HDFS NameNode supports exclusive write.
Q47. What are the Resampling methods?
Ans. Resampling methods are used to estimate the precision of the sample statistics, exchange labels on data points, and validate models.
Q48. What is selection bias, and how can you avoid it?
Ans. Selection bias is an experimental error that occurs when the participant pool or the subsequent data do not represent the target population.
Selection biases cannot be overcome with statistical analysis of existing data alone, though Heckman correction may be used in special cases.
Q49. What is the binomial distribution?
Ans. A binomial distribution is a discrete probability distribution that describes the number of successes when conducting independent experiments on a random variable.
Formula –
Where:
n = Number of experiments
x = Number of successes
p = Probability of success
q = Probability of failure (1-p)
Q50. What is covariance in statistics?
Ans. Covariance is a measure of the joint variability of two random variables. The covariance between two variables x and y, can be calculated as follows:
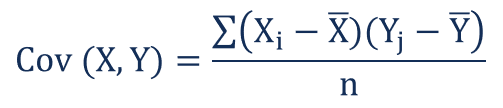
Where:
- Xi – the values of the X-variable
- Yj – the values of the Y-variable
- X̄ – the mean (average) of the X-variable
- Ȳ – the mean (average) of the Y-variable
- n – the number of data points

Q51. What is Root Cause Analysis?
Ans. Root Cause Analysis (RCA) is the process of uncovering the root causes of problems to identify appropriate solutions. The RCA assumes that it is much more useful to systematically prevent and resolve underlying issues than treating symptoms ad hoc and putting out fires.
Q52. What is Correlation Analysis?
Ans. Correlation Analysis is a statistical method for evaluating the strength of the relationship between two quantitative variables. It consists of autocorrelation coefficients estimated and calculated for a different spatial relationship. It is used to correlate data based on distance.
Q53. What is imputation? List the different types of imputation techniques.
Ans. Imputation is the process that allows you to replace missing data with other values. Types of imputation techniques include –
- Single Imputation: Single imputation denotes that the missing value is replaced by a value.
- Hot-deck: The missing value is imputed from a similar register, which is chosen at random based on a punched card.
- Cold deck Imputation: Select donor data from other sets.
- Mean Imputation: Substitute the stored value for the mean of that variable in other cases.
- Mean Imputation: Its purpose is to replace the missing value with predicted values of a variable that is based on others.
- Stochastic Regression: equal to the regression but adds the mean regression variance to the regression imputation.
- Multiple Imputation: It is a general approach to the problem of missing data, available in commonly used statistical packages. Unlike single imputation, Multiple Imputation estimates the values multiple times.
Q54. What is the difference between a bar graph and a histogram?
Ans. Bar charts and histograms can be used to compare the sizes of the different groups. A bar chart is made up of bars plotted on a chart. A histogram is a graph representing a frequency distribution; the heights of the bars represent observed frequencies.
In other words, a histogram is a graphical display of data using bars of different heights. Generally, there is no space between adjacent bars.
Bar Charts
- The columns are placed on a label that represents a categorical variable.
- The height of the column indicates the size of the group defined by the categories.
- The columns are placed on a label that represents a quantitative variable.
- The column label can be a single value or a range of values.
In bar charts, each column represents a group defined by a categorical variable; with histograms, each column represents a group defined by a quantitative variable.
Q55. Name some of the prominent resampling methods in data science.
Ans. The Bootstrap, Permutation Tests, Cross-validation, and Jackknife.
Q56. What is an Eigenvalue and Eigenvector?
Ans. Eigenvectors are used for understanding linear transformations.
Eigenvalue can be referred to as the strength of the transformation in the direction of the eigenvector or the factor by which the compression occurs.
Q57. Which technique is used to predict categorical responses?
Ans. Classification techniques are used to predict categorical responses.
Q58. What is the importance of Sampling?
Ans. Sampling is a crucial statistical technique for analyzing large volumes of datasets. This involves taking out some samples that represent the entire data population. Choosing samples that are the true representatives of the whole data set is imperative. There are two types of sampling methods – Probability Sampling and Non-Probability Sampling.
Q59. Is it possible to stack two series horizontally? If yes, then how will you do it?
Ans. Yes, it is possible to stack two series horizontally. We can use concat() function and setting axis = 1.
df = pd.concat([s1, s2], axis=1)
Q60. Tell me the method to convert date strings to time series in a series.
Ans.
Input:
We will use the to_datetime() function
Q61. How will you explain linear regression to someone who doesn’t know anything about data science?
Ans. In simple terms, linear regression is a statistical methodology to establish and measure the linear relationship between the two variables. If one variable increases, it affects the position of another variable and would lead to an increase in that variable as well. Similarly, if one variable decreases, another variable will also decrease. This relationship helps to establish statistical models that can forecast future outcomes based on an increase in one variable.
Q62. What is Systematic sampling?
Ans. Systematic sampling is a probability sampling method. In this method, the population members are selected at regular intervals.
Programming Language Interview Questions
Explore – Python Online Courses & Certifications
Q63. Why does Python score high over other programming languages?
Ans. This is among the very commonly asked data science interview questions. Python has a wealth of data science libraries; it is incredibly fast and easy to read and learn. The Python suite specializing in deep learning and other machine learning libraries includes popular tools such as sci-kit-learn, Keras, and TensorFlow, which allow data scientists to develop sophisticated data models directly integrated into a production system.
To discover data revelations, you must use Pandas, the data analysis library for Python. It can handle large amounts of data without the lag of Excel. You can do numerical modelling analysis with Numpy, do scientific computation and calculation with SciPy, and access many powerful machine learning algorithms with the Sci-Kit-learn code library. With the Python API and the iPython Notebook that comes with Anaconda, you will have robust options to visualize your data.
Q64. What are the data types used in Python?
Ans. Python has the following built-in data types:
- Number (float, integer)
- String
- Tuple
- List
- Set
- Dictionary
Numbers, strings, and tuples are immutable data types, meaning they cannot be modified at run time. Lists, sets, and dictionaries are mutable, which means they can be modified at run time.
Check out: Detailed blog on Python Data Types
Q65. What is a Python dictionary?
Ans. A dictionary is one of the built-in data types in Python. It defines a messy mapping of unique keys to values. Keys index dictionaries and the values can be any valid Python data type (even a user-defined class). It should be noted that dictionaries are mutable, meaning they can be modified. A dictionary is created with braces and is indexed using bracket notation.
Check out: Understanding Python Dictionary with examples
The interviewers often ask such common data science interview questions.
Q66. What libraries do data scientists use to plot data in Python?
Ans. Matplotlib is the main library used to plot data in Python. However, graphics created with this library need much tweaking to make them look bright and professional. For that reason, many data scientists prefer Seaborn, which allows you to create attractive and meaningful charts with just one line of code.
Q67. What are lambda functions?
Ans. Lambda functions are anonymous functions in Python. They are very useful when defining a very short function with a single expression. So, instead of formally defining the little function with a specific name, body, and return statement, you can write everything in a short line of code using a lambda function.
Q68. What is PyTorch?
Ans. PyTorch is a Python-based scientific computing package that performs numerical calculations using tensor programming. It also allows its execution on GPU to speed up calculations. PyTorch is used to replace NumPy and process calculations on GPUs and for research and development in machine learning, mainly focused on neural networks.
Explore free PyTorch courses
PyTorch is designed to integrate seamlessly with Python and its popular libraries like NumPy and is easier to learn than other Deep Learning frameworks. It has a simple Python interface, provides a simple but powerful API, and allows models to be run in a production environment, making it a popular deep-learning framework.
Explore: Online Pytorch Courses
Q69. What are the alternatives to PyTorch?
Ans. Some of the best-known alternatives to PyTorch are –
Tensorflow – Google Brain Team developed Tensorflow, a free software for numerical computation using graphs.
Caffe – Caffe is a machine learning framework for computer vision or image classification. Caffe is popular for its library of training models that do not require any extra implementation.
Microsoft CNTK - Microsoft CNTK is a free software framework developed by Microsoft. It is very popular in speech recognition, although it can also be used for other fields such as text and images.
Theano – Theano is another python library. It helps to define, optimize and evaluate mathematical expressions that involve calculations with multidimensional arrays.
Keras – Keras is a high-level API for developing neural networks written in Python. It uses other libraries internally such as Tensorflow, CNTK, and Theano. It was developed to facilitate and speed up the development and experimentation with neural networks.

You may consider such data science interview questions to be basic. Still, such questions are the favourite of interviewers as interviewees often leave behind such data science interview questions while preparing.
Q70. What packages are used for data mining in Python and R?
Ans. There are various packages in Python and R:
Python – Orange, Pandas, NLTK, Matplotlib, and Scikit-learn are some of them.
R – Arules, tm, Forecast, and GGPlot are some of the packages.
Q71. Which would you prefer – R or Python?
Ans. One of the most important data science interview questions.
Both R and Python have their own pros and cons. R is mainly used when the data analysis requires standalone computing or analysis on individual servers. Python, when your data analysis tasks need to be integrated with web apps or if statistics code needs to be incorporated into a production database.
Read More – What is Python?
Q72. Which package is used to import data in R and Python? How do you import data in SAS?
Ans. In R, RODBC is used for RDBMS data and data.table for fast-import.
In SAS, data and sas7bdat are used to import data.
In Python, Pandas package and the commands read_csv, read_sql are used for reading data.
Q73. Write a program in Python that takes input as the weight of the coins and produces output as their money value.
Ans. Here is an example of the code. You can change the values.

Q74. Explain the difference between lists and tuples.
Ans. Both lists and tuples are made up of elements, which are values of any Python data type. However, these data types have a number of differences:
Lists are mutable, while tuples are immutable.
Lists are created in brackets (for example, my_list = [a, b, c]), while tuples are in parentheses (for example, my_tuple = (a, b, c)).
Lists are slower than tuples.
Machine Learning Interview Questions
Must Read – What is Machine Learning?
Q75. What is Regularization and what kind of problems does regularization solve?
Ans. Regularization is a technique used in an attempt to solve the overfitting problem in statistical models.
It helps solve the problem of overfitting in machine learning.
Q76. What is a Boltzmann Machine?
Ans. Boltzmann Machines have a simple learning algorithm that helps them discover interesting features in training data. These machines represent complex regularities and are used to optimize the weights and quantities for the problems.
This is one of the important data science interview questions that you must prepare for your interview.
Q77. What is hypothesis testing?
Ans. Hypothesis testing is an important aspect of any testing procedure in Machine Learning or Data Science to analyze various factors that may impact the experiment's outcome.
Q78. What is Pattern Recognition?
Ans. Pattern recognition is the data classification process that includes pattern recognition and identification of data regularities. This methodology involves the extensive use of machine learning algorithms.
Q79. Where can you use Pattern Recognition?
Ans. Pattern Recognition has multiple usabilities across-
- Bio-Informatics
- Computer Vision
- Data Mining
- Informal Retrieval
- Statistics
- Speech Recognition
Q80. What is an Autoencoder?
Ans. These are feedforward learning networks where the input is the same as the output. Autoencoders reduce the number of dimensions in the data to encode it while ensuring minimal error and then reconstruct the output from this representation.
Also Explore – Deep Learning Online Courses & Certifications
Q81. What is the bias-variance trade-off?
Ans. Bias—Bias is the difference between a model's average prediction and the correct value we are trying to predict.
Variance – Variance is the variability of model prediction for a given data point or a value that tells us the spread of our data.
Models with high variance focus on training data, and such models perform very well on training data. On the other hand, a model with high bias doesn’t focus on training data and oversimplifies the model, leading to increased training and test data error.
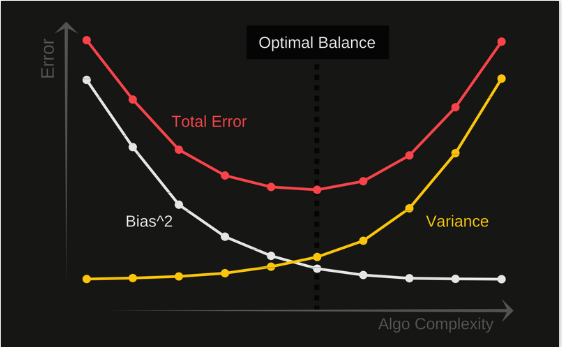
Fig – Optimal balance – Bias vs. Variance (Source – towardsdatascience.com)
Q82. When do you need to update the algorithm in Data science?
Ans. You need to update an algorithm in the following situation:
- You want your data model to evolve as data streams using infrastructure
- The underlying data source is changing
- If it is non-stationarity
Q83. Why should you perform dimensionality reduction before fitting an SVM?
Ans. These SVMs tend to perform better in reduced space. If the number of features is large as compared to the number of observations, then we should perform dimensionality reduction before fitting an SVM.
Q84. Name the different kernels of SVM.
Ans. There are nine types of kernels in SVM.
- Polynomial kernel
- Gaussian kernel
- Gaussian radial basis function (RBF)
- Laplace RBF kernel
- Hyperbolic tangent kernel
- Sigmoid kernel
- Bessel function of the first kind of Kernel
- ANOVA radial basis kernel
- Linear splines kernel in one-dimension
Q85. What is the Hierarchical Clustering Algorithm?
Ans. Hierarchical grouping algorithm combines and divides the groups that already exist, in this way they create a hierarchical structure that presents the order in which the groups are split or merged.
Q86. What is ‘Power Analysis’?
Ans. Power Analysis is a type of analysis used to determine what kind of effect a unit will have based simply on its size. Power Analysis can estimate the minimum sample size required for an experiment and is directly related to hypothesis testing. The primary purpose underlying power analysis is to help the investigator determine the smallest sample size adequate to detect the effect of a certain test at the desired level of significance.
Q87. Have you contributed to any open-source projects?
Ans. This question seeks a continuous learning mindset. It also tells the interviewer that a candidate is curious and how well they work as a team. Good data scientists are collaborative people who share new ideas, knowledge, and information to keep up with rapidly changing data science.
You must specify which projects you have worked on and their objectives. A good answer would include what you learned from participating in open-source projects.
Q88. How to deal with unbalanced data?
Ans. Machine learning algorithms don’t work well with imbalanced data. We can handle this data in a number of ways –
- Using appropriate evaluation metrics for model generated using imbalanced data
- Resampling the training set through undersampling and oversampling
- Properly applying cross-validation while using the over-sampling method to address imbalance problems
- Using more data, primarily by ensembling different resampled datasets
- Resampling with different ratios, where the best ratio majorly depends on data and models used
- Clustering the abundant class
- Designing your own models and being creative in using different techniques and approaches to get the best outcome
Q89. How will you recover the information from a given data set? What are the most common issues in the process of information retrieval?
Ans. The recovery process involves queries to the database where the structured information is stored, using a suitable interrogation language. The key elements that allow the search to be carried out, determining a greater degree of relevance and precision, such as indexes, keywords, thesauri, and the phenomena that can occur in the process, such as noise and documentary silence, must be considered.
One of the most common problems when searching for information is whether what we retrieve is “a lot or a little”; that is, depending on the type of search, a multitude of documents or simply a very small number can be retrieved. This phenomenon is called Silence or Documentary Noise.
Documentary silence - These documents are stored in the database. Still, they are unrecovered because the search strategy was too specific or because the keywords used were inadequate to define the search.
Documentary noise – The system recovers these documents but is irrelevant. This usually happens when the search strategy has been defined as too generic.
Q90. What is Big Data?
Ans. Big Data is a set of massive data, a collection of huge in size and exponentially growing data, that cannot be managed, stored, and processed by traditional data management tools.
To learn more about Big Data, read our blog – What is Big Data?
Q91. What are some of the important tools used in Big Data analytics?
Ans. The important Big Data analytics tools are –
• NodeXL
• KNIME
• Tableau
• Solver
• OpenRefine
• Rattle GUI
• Qlikview
Q92. What is a decision tree method?
Ans. The Decision Tree method is an analytical method that facilitates better decisions making through a schematic representation of the available alternatives. These decision trees are very helpful when risks, costs, benefits, and multiple options are involved. The name is derived from the model’s appearance, similar to a tree, and its use is widespread in decision-making under uncertainty (Decision Theory).
Must Explore – Data Mining Courses
Q93. What is the importance of the decision tree method?
Ans. The decision tree method mitigates the risks of unforeseen consequences and allows you to include smaller details that will lead you to create a step-by-step plan. Once you choose your path, you only need to follow it. Broadly speaking, this is a perfect technique for –
- Analyzing problems from different perspectives
- Evaluating all possible solutions
- Estimating the business costs of each decision
- Making reasoned decisions with real and existing information about any company
- Analyzing alternatives and probabilities that result in the success of a business
Must read: Splitting in Decision Tree
Q94. How to create a good decision tree?
Ans. The following steps are involved in developing a good decision tree –
- Identify the variables of a central problem
- List all the factors causing the identified problem or risk
- Prioritize and limit each decision criterion
- Find and list the factors from highest to lowest importance
- Establish some clear variables to get some factors that include strengths and weaknesses
- Generate assumptions in an objective way, taking out their ramifications
- Select the most relevant alternatives for your business
- Implement the alternatives consistent with your possible problems and risks
- Evaluate the effectiveness of the decision
You can also explore – Decision Tree Algorithm for Classification
Q95. What is Natural Language Processing?
Ans. Natural language processing (NLP) is a branch of artificial intelligence that helps computers understand, interpret, and manipulate human language. It focuses on processing human communications, dividing them into parts, and identifying the most relevant elements of the message. The Comprehension and Generation of Natural Language, it ensures that machines can understand, interpret and manipulate human language.
Must read: Tokenization in NLP
Q96. Why is natural language processing important?
Ans. NLP helps computers communicate with humans in their language and scales other language-related tasks. It contributes towards structuring a highly unstructured data source.
Also read: Understanding Part-of-Speech Tagging in NLP: Techniques and Applications
Q97. What is the usage of natural language processing?
Ans. There are several usages of NLP, including –
Content categorization – Generate a linguistics-based document summary, including search and indexing, content alerts, and duplication detection.
Discovery and modelling of themes – Accurately capture meaning and themes in text collections and apply advanced analytics to text, such as optimization and forecasting.
Contextual extraction – Automatically extract structured information from text-based sources.
Sentiment analysis – Identification of mood or subjective opinions in large amounts of text, including sentiment mining and average opinions.
Speech-to-text and text-to-speech conversion – Transformation of voice commands into written text and vice versa.
Document summarization – Automatic generation of synopses of large bodies of text.
Machine-based translation – Automatic translation of text or speech from one language to another.
Q98. What is Ensemble Learning?
Ans. This is among the most commonly asked data science interview questions.
Ensemble methods is a machine learning method that combines base models to create one efficient predictive model. It boosts the overall development of the process. Ensemble learning includes two common techniques
Bagging – Bagging includes two machine-learning models, Bootstrapping and Aggregation, into a single ensemble model. Here the data set is split for parallel processing of models for accuracy.
Boosting – Boosting is a sequential technique in which one model is passed to another to reduce error and create an efficient model.
Must read: Ensemble learning: Beginners tutorial
Q99. What is the main difference between supervised and unsupervised machine learning?
Ans. Supervised learning includes training labelled data for tasks such as data classification, while unsupervised learning does not require explicitly labelling data.
Check out detailed blog: Differences Between Supervised and Unsupervised Learning
Q100. What is DBSCAN Clustering?
Ans.: DBSCAN, or density-based spatial clustering, is an unsupervised approach that splits vectors into different groups basis minimum distance and the number of points in that range. There are two significant parameters in DBSCAN clustering.
Epsilon – Minimum radius or distance between the two data points
Min – Sample Points – Minimum sample number within a range to identify as one cluster.
Q101. What is data visualization?
Ans. Data visualization presents datasets and other information through visual mediums like charts, graphs, etc. It enables the user to detect patterns, trends, and correlations that might go unnoticed in traditional reports, tables, or spreadsheets.
Must Explore – Data Visualization Courses
Q102. What is Deep Learning?
Ans. It is among the most frequently asked data science interview questions. Deep Learning is an artificial intelligence function used in decision-making. Deep Learning imitates the human brain’s functioning to process the data and create the patterns used in decision-making. Deep learning is a key technology behind automated driving, automated machine translation, automated game playing, object classification in photographs, and automated handwriting generation.
Must Explore – Deep Learning Courses
Q103. Name different Deep Learning Frameworks.
Ans.
a) Caffe
b) Chainer
c) Pytorch
d) TensorFlow
e) Microsoft Cognitive Toolkit
f) Keras
Also Explore – Machine Learning Online Courses & Certifications
Q104. What are the various types of classification algorithms?
Ans. There are 7 types of classification algorithms, including –
a) Linear Classifiers: Logistic Regression, Naive Bayes Classifier
b) Nearest Neighbor
c) Support Vector Machines
d) Decision Trees
e) Boosted Trees
f) Random Forest
g) Neural Networks
Q105. What is KNN?
Ans. K-Nearest Neighbour or KNN is a simple Machine Learning algorithm based on the Supervised Learning method. It assumes the similarity between the new case/data and available cases and puts the new case closest to the available categories.
Q106. What is Gradient Descent?
Ans. Gradient Descent is a popular algorithm used for training Machine Learning models and finding the values of function (f) parameters, which helps minimize a cost function.
Q106. How to prepare for your data science interview?
Ans. Before you appear for your data science interview, make sure you have –
- Researched the role and the related skills required for the role
- Brushed up your learning, read through the concepts and went through the projects you have worked on
- Participated in a mock interview to prepare yourself better
- Reviewed on your past experience and achievements and made a gist of those
We hope these data science interview questions would help you crack your next interview. Always go well-prepared and be ready to share your experience of working on different projects. All the best!
On a lighter note –

FAQs
What is data science?
Data science is an interdisciplinary field involving scientific methods, processes, and systems to extract knowledge or a better understanding of data in various forms, whether structured or unstructured.
What does a data scientist do?
A data scientist is a professional who develops highly complex data analysis processes, through the design and development of algorithms that allow finding relevant findings in the information, interpreting results, and obtaining relevant conclusions, thus providing very valuable knowledge for the making strategic decisions of any company.
How to become a data scientist?
To become a data scientist, you should - Pursue an internship with any Data Science firm; Take up any online Data Science course, and courses that teach Statistics, Probability, and Linear Algebra; Learn about the basics of Natural Language Processing, Information Extraction, Computer Vision, Bioinformatics, and Speech Processing, etc.; Explore Optimization, Information Theory, and Decision Theory; Obtain any professional certification; Try managing databases, analyzing data, or designing the databases
What technical skills I must have to become a data scientist?
Knowledge of Python Coding, Hadoop, Hive, BigQuery, AWS, Spark, SQL Database/Coding, Apache Spark, among others u2022 Knowledge of Statistical methods and packages u2022 Working experience with Machine Learning, Multivariable Calculus & Linear Algebra u2022 Ability to write codes and manage big data chunks u2022 Hands-on experience with real-time data and cloud computing u2022 Ability to use automated tools and open-source software u2022 Knowledge of Data warehousing and business intelligence platforms
What is the average salary of a data scientist in India?
As per Ambitionbox, the average salary for a Data Scientist in India is Rs. 10.5 LPA.
What are the major job responsibilities of a data scientist?
The common job responsibilities of a data scientist are - Enhancing data collection procedures for building analytic systems; Processing, cleaning, and verifying the integrity of data; Creating automated anomaly detection systems and track their performance; Digging data from primary and secondary sources; Performing data analysis and interpret results using standard statistical methodologies; Ensuring clear data visualizations for management; Designing, creating and maintaining relevant and useful databases and data systems; Creating data dashboards, graphs, and visualizations; etc.
What is the eligibility criteria to become a data scientist?
To work as a data scientist, you must have an undergraduate or a postgraduate degree in a relevant discipline, such as Computer science, Business information systems, Economics, Information Management, Mathematics, or Statistics.
Which job profiles are available for data scientists?
Some of the popular data scientist roles are - Data Scientist - R/Statistical Modelling; Software Engineer - Python/R/Machine Learning; Data Analyst; Lead Python Developer; AI and Machine Learning Expert; Data Science Engineer; Manager - Machine Learning; Senior Data Scientist, Data Scientist - Machine Learning/AI; Senior Data Manager; Senior Manager - Data Scientist; Process Manager - Data Science; Applied Scientist; Principle Data and Applied Scientist, etc.
Which are the top industries hiring data scientists?
Some of the most popular recruiters for data scientists are - BFSI, Public Health, Telecommunications; Energy; Automotive; Media & Entertainment; Retail, etc.
Which are the best data science courses available online?
https://learning.naukri.com/executive-data-science-specialization-course-courl402; https://learning.naukri.com/the-data-scientists-toolbox-course-courl468; https://learning.naukri.com/launching-machine-learning-delivering-operational-success-with-gold-standard-ml-leadership-course-courl509; https://learning.naukri.com/simplilearn-data-scientist-masters-program-course-sl02https://learning.naukri.com/data-science-machine-learning-course-edxl236; https://learning.naukri.com/python-for-data-science-and-machine-learning-bootcamp-course-udeml455
Is data science a good career?
Data Science is the fastest-growing job on LinkedIn and is speculated to create 11.5 million jobs by 2026. Employment opportunities are available across different industries and are among the highest paying jobs across the globe, making it a very lucrative career option.

Rashmi is a postgraduate in Biotechnology with a flair for research-oriented work and has an experience of over 13 years in content creation and social media handling. She has a diversified writing portfolio and aim... Read Full Bio