
Hadoop Tutorial: A Beginner’s Guide to Learning Hadoop Online
Hadoop is an open-source software framework used for distributed storage and processing of big data using the MapReduce programming model. Written in Java, the framework was developed by Apache Software Foundation and released in 2011.

This Hadoop tutorial covers:
Let’s begin with the Hadoop tutorial.
What are the Characteristics of Hadoop?
Hadoop is a commonly-used tool in the big data industry. It has a lot of important features and characteristics:
- Open-Source – Hadoop is an open-source project and hence one can modify it according to the requirements.
- Reliability – Due to the replication of data in the cluster, data will be stored reliably even when the machine goes down.
- High Availability – Data is available and accessible even when the machine or a few of the hardware crashes as there are multiple copies of data.
- Scalability – New hardware can be easily added to the nodes without downtime as Hadoop is highly scalable.
- Economic – As Hadoop does not require a specialized machine and can work with a cluster of commodity machines, it provides a huge cost reduction.
- Easy-To-Use – Framework takes care of the distributed computing so clients do not need to worry about it.
- Fault Tolerance – Three replicas of each block are stored across the cluster and hence, data can be recovered from any node when one node goes down.
Best-suited Apache Hadoop courses for you
Learn Apache Hadoop with these high-rated online courses

What are the Prerequisites for Learning Hadoop?
Hadoop is written in Java and hence, a good knowledge of the language is beneficial. Apart from that, you should have prior exposure to database concepts. Plus, you should be proficient in Linux or Windows operating system.
Explore the best Hadoop Courses
How to Install Hadoop?
For Linux:
Linux is the best platform to run Hadoop. In Linux, you can start from scratch by building and configuring from the start, providing you with a better grasp of the concepts.
Explore popular Linux Courses
Pre-requisites
Step 1: Install Java first. You can download it from the Oracle site.
Step 2: Add a dedicated Hadoop system user. Open the Linux terminal and type the following commands
$ su
password:
# useradd hadoop
# passwd hadoop
New passwd:
Retype new passwd
Step 3: SSH setup and key generation. The following commands are used for generating a key value pair using SSH.
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
Step 4: Disable IPv6. Hadoop is not supported on IPv6 networks and some Linux releases default to IPv6 only.
Installing
Step 1: Download Hadoop. Download from the Apache website.
Step 2: Format the HDFS file format. It creates an empty filesystem by creating storage directories and the primary versions requirements of the namenode’s persistent data structures.
The steps are:
Get access permission – % hadoop namenode – format
Starting and stopping daemon using MapReduce algorithm –
% start-mapred.sh
% stop-dfs.sh
% stop-mapred.sh
Starting and stopping daemon using MapReduce 2 –
% start-yarn.sh
% stop-dfs.sh
% stop-yarn.sh
Step 3: Hadoop configuration – It is required to make changes in those configuration files according to your Hadoop infrastructure.
$ cd $HADOOP_HOME/etc/hadoop
Also Read: Top Hadoop Interview Questions & Answers
Windows
This tutorial is for running Hadoop on Windows using Hortonworks Data Platform (HDP).
Prerequisites
Step 1: Install Java as mentioned in the Linux steps.
Step 2: Install Python. You can download it from the Python site.
Step 3: Ensure HDP finds Python by updating the PATH System Environment variable.
Go to Computer > Properties > Advanced System Settings > Environment variables.
Step 4: Install HDP. Download from the HDP site.
Step 5: Validate install by running smoke tests. In command prompt switch to using the ‘Hadoop’ user
> cd C:hdp
> Run-SmokeTests Hadoop
This will fire up a MapReduce job.
Now Hadoop is ready to use on your Windows.
Also Read: Career Advantages of Hadoop Certification
What is the Composition of the Hadoop Framework?
In this section of the Hadoop tutorial, we will discuss the composition of the Hadoop framework.
The base architecture of an Apache Hadoop framework consists of the following modules:
- Hadoop Common – It is a collection of the common Java libraries and utilities that support other Hadoop modules. Also known as Hadoop Core, it also contains the necessary Java Archive (JAR) files and scripts required to start Hadoop. It also provides the source code and documentation.
- MapReduce – A framework for easily writing applications that process big amounts of data in parallel on large clusters of hardware in a reliable manner.

It refers to the two tasks that Hadoop programs perform:
- The Map Task: In this task, input data is converted into a set of data where individual elements are broken down into tuples (key/value pairs).
- The Reduce Task: It takes input from a Map Task and combines those data tuples into a smaller set of tuples. This always takes place after the Map Task.
Hadoop Yarn – A cluster management technology, this platform is responsible for managing computing resources in clusters and using them for scheduling users’ applications.
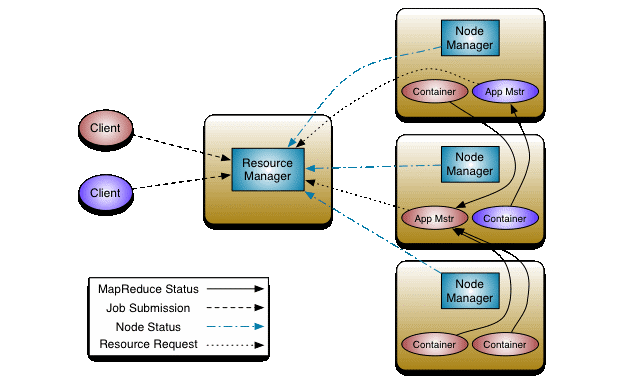
- Resource Manager – Manages and allocates cluster resources.
- Node Manager – Manages and enforces node resources allocations.
- Application Master – Manages application lifecycle and task scheduling.
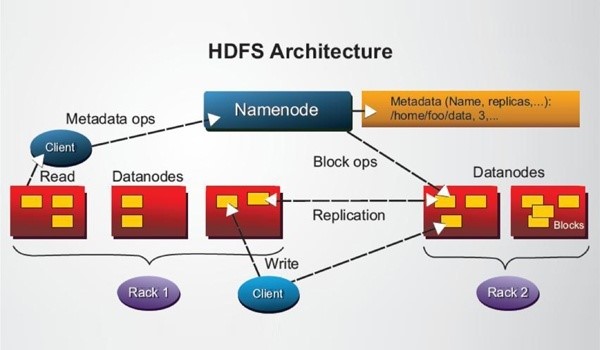
Hadoop Distributed File System (HDFS) – HDFS stores data on commodity machines and is designed to run on large clusters of small computer machines.
HDFS uses a master/slave architecture where the master consists of a single NameNode that manages the file system metadata and one or more slave DataNodes that store the actual data.
How Does Hadoop Work?
We have already seen the architecture of Hadoop and have a basic understanding of the framework. Let us now take a look at how it works internally:
In Hadoop, the data submitted by clients is stored in HDFS and processed in MapReduce.
How is Data Stored in HDFS?
HDFS is the storing element of Hadoop. There are 2 daemons that run on HDFS:
- Namenode – It runs on the master node and stores the metadata.
- Datanode – It runs on slaves and stores the actual data.
The data is broken into chunks called blocks and each block is replicated, then stored in different nodes in the cluster as per the replication factor (the default is 3).
Also Read: Top Reasons to Learn Python and Hadoop
How is Data processed?
MapReduce is the processing layer of Hadoop and has 2 daemons:
- Resource manager – It splits the job submitted by the client into small tasks.
- Node manager – It actually does the tasks in parallel in a distributed manner on data stored in datanodes.
Here are the steps in summary:
Step1: User submits a job to Hadoop and this input data is broken into blocks of size 64 Mb or 128 Mb.
Step 2: These blocks are distributed to different nodes. Processing of data takes place once all the blocks of the data are stored on data-nodes.
Step 3: Resource Manager schedules the program on individual nodes.
Step 4: After the processing of data, the output is written back on HDFS.
Also Read: Spark Vs Hadoop
What are the Popular Tools in Hadoop?
This section of the Hadoop tutorial focuses on different popular tools in Hadoop.
Apache Pig – It is a high-level platform for analyzing large data sets and consists of high-level language called Pig Latin. It is used for the following purposes:
- ETL data pipeline
- Research on raw data
- Iterative processing
It is extremely popular and has different user groups. E.g. 90% of Yahoo’s MapReduce and 80% of Twitter’s MapReduce is done by Pig.
Apache Hive – It is like a data warehouse that uses MapReduce for the purpose of analyzing data stored on HDFS. It provides a query language called HiveQL that is familiar to the Structured Query Language (SQL) standard. It is also as much popular as Pig and is used by CNET and Facebook.
HBase – Based on NoSQL, it is an open-source database platform and is built on topmost of the Hadoop file system. There are two components of HBase – 1) HBase master and 2) RegionServer.
Apache Zookeeper – Zookeeper is a coordinated service that allows the distribution of processes to organize with each other through a shared hierarchical namespace of data registers. It allows developers to focus on core application logic without worrying about the distributed nature of the application.
Also Read: Mastering Hadoop: Pros and Cons of Using Hadoop technologies
Learn In-Depth
To become an expert in Hadoop there are a lot of areas that you need to have hands-on experience in. Also, you need to be proficient in the various tools and techniques associated with it.
We hope this Hadoop Tutorial helped you understand Hadoop in-depth. Explore Hadoop Courses and Big Data courses on Shiksha Online to get the required practical skills to start your career in the field of Hadoop and Big Data.

This is a collection of insightful articles from domain experts in the fields of Cloud Computing, DevOps, AWS, Data Science, Machine Learning, AI, and Natural Language Processing. The range of topics caters to upski... Read Full Bio