
Handling missing values: Beginners Tutorial
We take data from sometimes sources like kaggle.com, sometimes we collect from different sources by doing web scrapping containing missing values in it. But do you think

- We can collect data and start doing our work?
- Can we implement machine learning algorithms using that data?
The answer is no. Because the data collected is unprocessed. Unprocessed data must be containing some
- Missing values
- Outliers
- Unstructured manner
- Categorical data(which needs to be converted to numerical variables)
For understanding different techniques for handling categorical data and their implementation you can read my series of blogs.

 Read Later
Read Later

So the first step is to do data preprocessing, before looking for any insights from the data, then only we can train our machine learning model.
Note: Uncleaned data can’t be processed by most of the machine learning algorithms.
Missing value in a dataset is a very common phenomenon in the reality, yet a big problem in real-life scenarios. Missing Data can also refer to as NA(Not Available) values in pandas. In DataFrame sometimes many datasets simply arrive with missing data, either because it exists and was not collected or it never existed. For example, Suppose during a survey
- Different users may choose not to share their addresses
- There might be a failure in recording the values due to human error.
- Due to improper maintenance past data might get corrupted.
In this way, many datasets went missing. Let’s have a look at the missing data in the dataset below.

In this blog, you will see how to handle missing values. Missing value correction is required to reduce bias and to produce powerful suitable models.
So, let’s begin with the methods to solve the problem. Since it is a beginners level blog so I will be covering three techniques in this blog
- Fillna
- Interpolate
- Dropna
“Data is the food for Machine Learning algorithms”
1. Delete Rows with Missing Values
One way of handling missing values is the deletion of the rows or columns having null values. If any columns have more than half of the values as null then you can drop the entire column. In the same way, rows can also be dropped if having one or more columns values as null. Before using this method one thing we have to keep in mind is that we should not be losing information. Because if the information we are deleting is contributing to the output value then we should not use this method because this will affect our output.
When to delete the rows/column in a dataset?
- If a certain column has many missing values then you can choose to drop the entire column.
- When you have a huge dataset. Deleting for e.g. 2-3 rows/columns will not make much difference.
- Output results do not depend on the Deleted data.
Note: No doubt it is one of the quick techniques one can use to deal with missing values. But this approach is not recommended.
Best-suited Python for data science courses for you
Learn Python for data science with these high-rated online courses

2. Replacing With Arbitrary Value
If you can replace the missing value with some arbitrary value using fillna().
Ex. In the below code, we are replacing the missing values with ‘0’.As well you can replace any particular column missing values with some arbitrary value also.
- Replacing with previous value – Forward fill
We can impute the values with the previous value by using forward fill. It is mostly used in time series data.
Syntax: df.fillna(method=’ffill’)
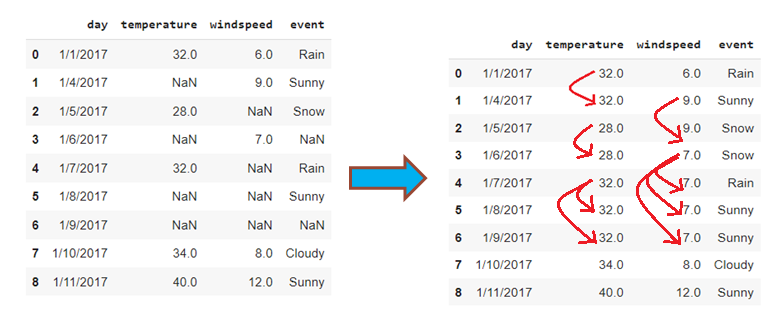
- Replacing with next value – Backward fill
In backward fill, the missing value is imputed using the next value. It is mostly used in time series data.

3. Interpolation
Missing values can also be imputed using ‘interpolation’. Pandas interpolate method can be used to replace the missing values with different interpolation methods like ‘polynomial’, ‘linear’, ‘quadratic’. The default method is ‘linear’.
Syntax: df.interpolate(method=’linear’)
For the time-series dataset variable, it makes sense to use the interpolation of the variable before and after a timestamp for a missing value. Interpolation in most cases supposed to be the best technique to fill missing values.
Handling missing values: python code:
We have taken dataset titanic.csv which is freely available at kaggle.com.This dataset was taken as it has missing values.
1.Reading the data
import pandas as pd df = pd.read_csv("train.csv", usecols=['Age','Fare','Survived']) df
The dataset is read and used three columns ‘Age’, ’Fare’, ’Survived’.

2. Checking if there are missing values
df.isnull().sum() Output: Survived 4 Age 179 Fare 2 dtype: int64
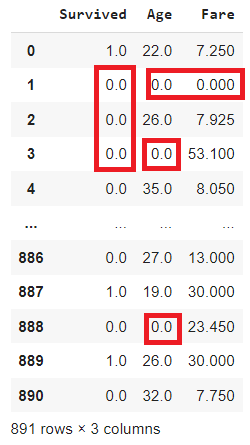
3.Filling missing values with 0
new_df = df.fillna(0) new_df
4. Filling NaN values with forward fill value
new_df = df.fillna(method="ffill") new_df

If we use forward fill that simply means we are forwarding the previous value where ever we have NaN values.
5. Setting forward fill limit to 1
new_df = df.fillna(method="ffill",limit=1) new_df

Now we have set the limit of forward fill to 1 which means that only once, the value will be copied below. Like in this case we had three NaN values consecutively in column Survived. But one NaN value was filled only as the limit is set to 1.
6. Filling NaN values in Backward Direction
new_df = df.fillna(method="bfill")new_df

7. Interpolate of missing values
new_df = df.interpolate() df

In this, we were having two values 22 and 26. And in between value was a NaN value. So that NaN value is computed by getting the mean of 22 and 26 i.e. 24. In the same way, other NaN values were also computed.
8. Dropna()
new_df = df.dropna() new_df

Previously we were having 891 rows and after running this code we are left with 710 rows because some of the rows were continuing NaN values were dropped.
9. Deleting the rows having all NaN values
new_df = df.dropna(how='all') new_df
Those rows in which all the values are NaN values will be deleted. If the row even has one value even then it will not be dropped.
Assignment
It’s my suggestion to download any other dataset(having missing values) and try this simple code. And check where it is needed to drop the row or column and when to fill the values or when to impute the values.
Endnotes
Every dataset has some missing values that need to be handled. The first step is to explore the data and check out which variable has missing data, what is the percentage. Then you have to decide what methods you could try. There is no hard and fast rule to handle missing values in a particular manner. You have to try different methods for it, depending on how and what the data is about. This blog offers a beginner’s level way of handling missing data. In the next blog will try replacing values and predicting the missing values. Stay tuned!!!
If you like my blog please share it with others also.
