
HIVE Tutorial: Everything You Need to Know to Get Started with Hive
Hive is an open-source data warehousing framework built atop Hadoop. It provides a powerful SQL-like interface to query and analyze large-scale data. Through this article, we will what does HIVE do, features of HIVE, its architecture, how to install HIVE in your system, and many more things related to HIVE.

In the era of big data, efficient processing and analysis of massive datasets are essential for organizations to make informed decisions. Hive, an open-source data warehousing framework built on Hadoop, provides a powerful SQL-like interface to query and analyze large-scale data.
In this Hive tutorial, we will cover everything you need to know to get started with Hive, including installation, data ingestion, data exploration, data transformation, and data analysis. Discover the key concepts and techniques of data warehousing with our in-depth Hive tutorial.
Overview of HIVE
Hive is an open-source data warehousing framework built atop Hadoop. It provides a powerful SQL-like interface to query and analyze large-scale data. Hive’s popularity has grown recently, making it one of the most widely used data processing tools in significant data ecosystems.
Hive is designed to process and analyze massive datasets in a distributed storage system like the Hadoop Distributed File System (HDFS). It uses a high-level language called Hive Query Language (HiveQL) that translates SQL-like queries into MapReduce jobs distributed across a Hadoop cluster. Hive provides a familiar SQL-like syntax that is easy to learn for users familiar with SQL.
Best-suited Apache Hadoop courses for you
Learn Apache Hadoop with these high-rated online courses

What Does Hive Do?
Hive provides a data warehouse infrastructure that allows users to create tables, load data into those tables, and perform queries on the data using HiveQL. It/ also supports partitioning, bucketing, and indexing for efficient data processing and analysis. Hive also supports user-defined functions (UDFs) that enable users to extend Hive’s functionality to perform custom data processing and analysis tasks.
Hive can handle petabytes of data and is highly optimized for parallel processing across a Hadoop cluster. It also supports fault tolerance, handling data loss, or node failure. Hive also provides a web-based interface called Hive Web Interface (HWI), which enables users to monitor and manage Hive jobs and resources.
Features of Hive

The major features of Hive for big data processing include:
- Open Source: Hive is an open-source software, making it easily accessible to users worldwide for big data use cases and implementations.
- SQL-like Interface: Hive provides a SQL-like interface with a similar query language called HiveQL, allowing users to interact with data using SQL-like syntax and commands.
- Data Warehousing: Hive is designed for data warehousing tasks, enabling effective analysis of datasets stored in the Hadoop Distributed File System (HDFS).
- Scalability: Hive is highly scalable as it can work on datasets spread across multiple computer clusters.
- Integration with Hadoop Ecosystem: Hive seamlessly integrates with the components of the Hadoop Ecosystem, like HDFS and MapReduce, making it a helpful tool for big data processing.
- Data Management: Hive maintains meta-data like tables, columns, and more in a meta-store, making it easier for the user to manage data.
Hive Architecture

- Hive Services: Hive Services refer to the various components and processes that make up the Hive data warehouse system. These services work together to enable the storage, processing, and querying of large datasets.
- Hive Client: The Hive Client is a software component that allows users to interact with the Hive data warehouse. It provides a command-line interface (CLI) or graphical user interface (GUI).
- Hive Driver: The Hive Driver is a software component that acts as an interface between the Hive client and the Hive services.
- Metastore: The Metastore service stores and manages metadata about tables, partitions, columns, and other objects in Hive.
- MapReduce: MapReduce is a programming model and framework for processing large datasets in parallel across a distributed cluster.
- Hadoop Distributed File System (HDFS): Hadoop Distributed File System (HDFS) is a distributed file system that provides reliable and scalable storage for big data processing. It is one of the core components of the Apache Hadoop ecosystem.
HIVE Installation
To install Hive, you need to have Hadoop installed on your system. You can download Hadoop from the Apache Hadoop website. Once you have Hadoop installed, follow these steps to install Hive:
- First, download the latest version of Hive from the Apache Hive website.

- Next, extract the downloaded file to a directory on your system.
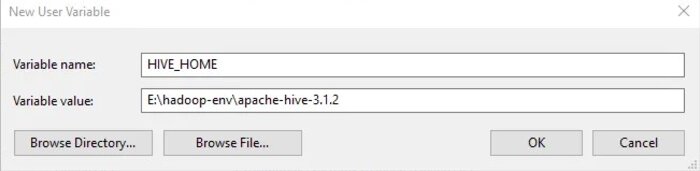
- Next, set the environment variable HIVE_HOME to the directory where Hive is extracted.

- Finally, add $HIVE_HOME/bin to your PATH variable.
Data Pipeline in Hive
Collectively, data ingestion, analysis, exploration, and transformation in Hive are referred to as the data processing pipeline or data pipeline in Hive. The data pipeline encompasses the entire lifecycle of data within Hive, from ingesting and loading the data into Hive tables to performing analysis, exploration, and transformation operations on the data.
Now, we will discuss each step involved in the pipeline through this Hive tutorial:
Data Ingestion
Hive supports various data sources, including HDFS, HBase, and Amazon S3. To ingest data into Hive, you can use the following methods:
- Using the LOAD DATA command: The LOAD DATA command loads data from a file or directory into a Hive table. The syntax of the LOAD DATA command is as follows:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
- Using the INSERT command: The INSERT command inserts data into a Hive table. The syntax of the INSERT command is as follows:
INSERT INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement
- Using Sqoop: Sqoop is a tool that transfers data between Hadoop and relational databases. For example, you can use Sqoop to import data from a relational database into a Hive table.
Data Exploration
Once you have ingested the data into Hive, you can explore the data using Hive queries. Hive queries are similar to SQL queries. Here are some examples of Hive queries:
- SELECT: The SELECT statement retrieves data from a Hive table. The syntax of the SELECT statement is as follows:
SELECT [ALL | DISTINCT] select_list FROM tablename [WHERE where_condition] [GROUP BY col_list] [HAVING having_condition] [ORDER BY col_list] [LIMIT number];
- COUNT: The COUNT function counts the number of rows in a Hive table. The syntax of the COUNT function is as follows:
SELECT COUNT(*) FROM tablename;
- JOIN: The JOIN operation combines data from two or more tables. The syntax of the JOIN operation is as follows:
SELECT t1.col1, t2.col2 FROM table1 t1 JOIN table2 t2 ON t1.key = t2.key;
Data Transformation
Hive provides various functions and operators to transform data. Here are some examples of Hive functions and operators:
- CONCAT: The CONCAT function is used to concatenate two or more strings. The syntax of the CONCAT function is as follows:
SELECT CONCAT(col1, col2) FROM tablename;
- SUBSTR: The SUBSTR function extracts a substring from a string. The syntax of the SUBSTR function is as follows:
SELECT SUBSTR(col1, start, length) FROM tablename;
- CASE: The CASE operator is used to perform conditional operations. Here’s an example of the CASE operator:
SELECT CASE WHEN col1 > 0 THEN 'Positive' ELSE 'Negative' END FROM tablename;
Data Analysis
Once you have transformed the data, you can perform various data analysis tasks using Hive. Here are some examples of data analysis tasks:
- Aggregation: The GROUP BY and AGGREGATE functions perform aggregation operations on data. Here’s an example of the GROUP BY and COUNT functions:
SELECT col1, COUNT(*) FROM tablename GROUP BY col1;
- Window functions: Hive supports window functions, which perform calculations across a set of rows. Here’s an example of the ROW_NUMBER function:
SELECT ROW_NUMBER() OVER (PARTITION BY col1 ORDER BY col2) as row_num, col1, col2 FROM tablename;
- User-defined functions: Hive allows you to create user-defined functions (UDFs) to perform custom data analysis tasks. Here’s an example of a UDF that calculates the cosine similarity between two vectors:
SELECT ROW_NUMBER() OVER (PARTITION BY col1 ORDER BY col2) as row_num, col1, col2 FROM tablename;
Now, let’s take a dataset and perform what we have discussed above.
Best Practices for Using Hive
Hive is a powerful tool for data processing and analysis in significant data ecosystems. However, to maximize Hive’s capabilities, it’s essential to follow best practices to ensure efficient and effective tool use. Here are some best practices for using Hive:
- Optimise table design: Proper table design is crucial for efficient data processing and analysis in Hive. Use partitioning, bucketing, and indexing to optimize query performance. Partitioning and bucketing can help distribute data evenly across a cluster, while indexing can speed up query execution by reducing the number of rows that need to be scanned.
- Use compression: Hive supports data compression, which can reduce storage and processing costs by reducing the amount of data that needs to be read and written. Use compression algorithms like Snappy, LZO, or Gzip to compress data based on your storage and processing requirements.
- Optimise query performance: Hive’s query performance can be optimized by minimizing the amount of data that needs to be read and processed. Use WHERE clauses and GROUP BY clauses to filter and aggregate data to minimize data scanning. Avoid using JOIN operations on large tables, as they can be resource-intensive.
- Use Tez or LLAP execution engine: Hive supports different execution engines like MapReduce, Tez, and LLAP. Tez and LLAP perform better than MapReduce as they optimize resource usage and reduce query latency. Choose an execution engine based on your data processing requirements.
- Use bucketed and sorted tables: Bucketed and sorted tables can further optimize query performance in Hive. Bucketed tables can help distribute data evenly across a cluster and enable parallel processing. Sorted tables help speed up query execution by allowing Hive to skip unnecessary rows during data scans.
- Use external tables for intermediate data: Intermediate data generated during data processing can be stored in external tables to reduce storage costs and improve performance. External tables store data outside the Hive data warehouse, which can help reduce storage costs and improve processing efficiency.
- Monitor and optimize resource usage: Monitoring resource usage can help identify bottlenecks and optimize query performance. Use Hive’s monitoring and profiling tools like Hive Web Interface (HWI) or Ambari Metrics to monitor resource usage and optimize query performance.
- Use UDFs for custom functionality: Hive supports user-defined functions (UDFs) that enable users to perform custom data processing and analysis tasks. UDFs is used to extend Hive’s functionality and perform custom data analysis tasks not supported by Hive.
Conclusion
In conclusion, Hive is a robust data warehousing framework that simplifies data processing and analysis in significant data ecosystems. By following best practices like optimizing table design, using compression, optimizing query performance, using the right execution engine, using bucketed and sorted tables, using external tables for intermediate data, monitoring and optimizing resource usage, and using UDFs for custom functionality, users can optimize Hive’s performance and achieve efficient and effective data processing and analysis.
Hive’s scalability and flexibility make it popular for data engineers, analysts, and scientists working with large-scale data. Users can achieve efficient and effective data processing and analysis in big data ecosystems by maximizing Hive’s capabilities and following best practices.
With the help of this Hive tutorial, you can quickly learn how to create scalable applications and utilize the potential of big data processing.
Contributed By: Jivan Tandon
FAQs
What is Hive?
Hive is an open-source data warehousing framework that simplifies data processing and analysis in big data ecosystems. It uses Hadoop as its underlying computational engine and provides a SQL-like interface to interact with large-scale datasets. This Hive tutorial will help you learn more about concepts related to Hive.
What are some use cases for Hive?
Hive is commonly used for data warehousing, analysis, and processing in big data ecosystems. In addition, it can be used for various use cases like ad hoc querying, data analysis, data visualization, machine learning, and data transformation.
What are some best practices for using Hive?
Some best practices for using Hive include optimizing table design, using compression, optimizing query performance, using the right execution engine, using bucketed and sorted tables, external tables for intermediate data, monitoring and optimizing resource usage, and UDFs for custom functionality.
What is the difference between MapReduce and Tez execution engines in Hive?
MapReduce is the default execution engine in Hive, whereas Tez is an alternative execution engine that provides better performance by optimizing resource usage and reducing query latency. Therefore, Tez is recommended for complex queries and large-scale data processing tasks.
What are some standard data formats supported by Hive?
Hive supports various data formats like CSV, TSV, ORC, Parquet, and Avro. These formats are optimized for efficient data processing and analysis in Hive.
Can Hive be used with other big data tools and frameworks?
Yes, Hive can be used with other big data tools and frameworks like Hadoop, Spark, Pig, and HBase. In addition, hive provides interoperability with these tools and frameworks, allowing users to perform complex data processing and analysis tasks in significant data ecosystems. For more details, you can refer to the Hive tutorial above.
What is the role of UDFs in Hive?
UDFs (User-Defined Functions) in Hive enable users to perform custom data processing and analysis tasks not supported by Hive. UDFs allow users to extend Hive's functionality and perform custom data analysis tasks.
How can Hive's performance be monitored?
Hive's performance can be monitored using various monitoring and profiling tools like Hive Web Interface (HWI), Ambari Metrics, and YARN resource manager. These tools enable users to monitor resource usage and optimize query performance in Hive.

This is a collection of insightful articles from domain experts in the fields of Cloud Computing, DevOps, AWS, Data Science, Machine Learning, AI, and Natural Language Processing. The range of topics caters to upski... Read Full Bio