
Introduction to Hashing
Hash Table is the most important data structure in computer programming which uses a special function known as a hash function. A Hash table is an associative data structure and uses an array format to store the data.
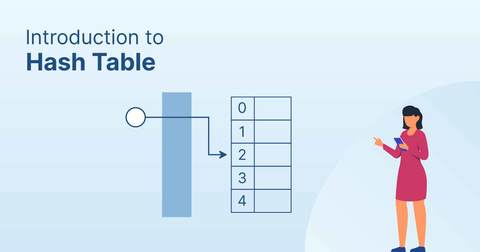
In the hash table, each data value has its own unique value similar to an array. Hash table provides quick access to data elements if you know the index value of the data element. In this article, we will discuss the hash table, hash function, the drawback of the hash function, Hashing, Collision, and Applications of Hash table.
You can also explore: Data Structures and Algorithms in Python – All You Need to Know
Hash Table
A Hash table uses a function known as a hash function, to map the data value into the hash table. The hash function uses a key to map the data values into the table, to make the data access faster. The hash table is a data structure stores some information, the information contains two components, a key, and a value.
Key: Key is a unique integer that is used to store the values.
Values: Value means the data associated with the key.
The hash table can be implemented using an associative array. The efficiency of data mapping in a hash table completely depends upon the Hash function used to map the data.
You can also explore: Understanding Data Structures and Algorithms in Java
Best-suited Data Structures and Algorithms courses for you
Learn Data Structures and Algorithms with these high-rated online courses

Hash Function
A hash function is the most important part of hashing and hash table, as the hash function maps the data values into the table, and the efficiency of data retrieval completely depends upon the Hash function.
The hash function can be given as:
Hash (key) = index
The above function passes the key value in the Hash function and inserts the value at the index.
The drawback of the Hash Function:
The hash table assigns each value with a unique key, sometimes collision takes place when the same key is assigned to two different values. So, an imperfect hash function can lead to a collision while data storage.
Hashing
Hashing is a process, in which a new index value is assigned to a key, and data associated with that key is stored at that index.

In the above diagram k1, k2, k3….. are key values whereas h(k1), h(k2), h(k3)….. are index variables where the data associated with keys will be stored and accessed whenever required. Hashing in simple words is the process of storing data values in the array structured hash table after the mapping of key using hash function is being done.
Ways to calculate Hash Function:
Hash function is calculated using three methods:
- Division method
- Folding method
- Mid square method
Division method:
In division method a hash function is calculate using following function:
h (ki) = ki % m;
where, m is the size of the hash table, and i is the value of key value.
Example:
If the value to be stored is 15 and the hash table is of size 10. Then the key value will be stored at
h (15) = 15 % 10
h (15) = 5
So, key value 15 will be stored at index value 5.
Collision:
Earlier, we have seen that there is a issue with hash function, which is it can assign same index value to multiple keys, and it can cause collison in the data items, If two data items got similar key values than the data will tend to get stored at same location which can cause collison in data items.
So when hash function produces same index value for different keys, such situation is known as hash collison.
Hash collision can be resolved using two techniques:
- Chaining
- Open Addressing
Example:
Consider we, need to store the following data using the divison hash function:
4, 3, 6, 14, 12, 15 where size of hash table is 10.
Solution:
For 4,
h (4) = 4 % 10
h (4) =4
For 3,
h (3) = 3 % 10
h (3) =3
For 6,
h (6) = 6 % 10
h (6) =6
For 14,
h (14) = 14 % 10
h (14) =4…………Collison will happen because same index number was assigned to 4
For 12,
h (12) = 12 % 10
h (12) = 2
For 15,
h (15) = 15 % 10
h (15) =5
For resolving this situation, collison resolving techniques can be used.
Chaining: Chaining makes use of a linked list and helps in storing multiple key values at the same index using a doubly linked list.
Open addressing: Open addressing is different from chaning, in open addressing each slot either have one element or left unfilled. Open addressing is of three types:
- Linear probing
- Quardatic probing
- Double Hashing
Linear Probing
In linear probing if, collision is occured in the slot, then we will check it;s next slot, whether it is empty or filled if it is empty then store the value in that slot.
Hash Function used for linear probing is
h(k, i) = (h′(k) + i) mod m
where
- i = {0, 1, ….}
- h'(k) is a new hash function
The main issue with linear probing is a cluster of adjacent nodes are filled, so in order to insert a new element using linear probing requires a lot of traversing.
Quadratic Probing
Quadratic probing is similar to linear probing, it just resolevs the issue of contiguos filling of slot. If collison occurs while using quadratic probing, it will insert collided data into next slot, and the next slot will use the follwoing hash function:
h(k, i) = (h′(k) + c1i + c2i2) mod m
where,
- i = {0, 1, ….}
- c1 and c2 are positive auxiliary constants,
Double Hashing
If collison is still persitiing after applying hash function, then double hashing is used, in double hashing another hash function is applied to find the next slot for the data.
Also Read: Understanding Data Structures in C: Types And Operations
Applications of Hash table
- Hash table is implemented in cryptographic applications.
- It is used wherever index is required.
- It is implemented where constant time lookup and insertion are required.
Author: Kanika Joshi

This is a collection of insightful articles from domain experts in the fields of Cloud Computing, DevOps, AWS, Data Science, Machine Learning, AI, and Natural Language Processing. The range of topics caters to upski... Read Full Bio