
Introduction to Sampling and Resampling

Table of Content:
Best-suited Statistics for Data Science courses for you
Learn Statistics for Data Science with these high-rated online courses

Sampling:
Sampling is a process of selecting group of observations from the population, to study the characteristics of the data to make conclusion about the population.
Example: Covaxin (a covid-19 vaccine) is tested over thousand of males and females before giving to all the people of country.
Types of Sampling:
Whethe the data set for sampling is randomized or not, sampling is classified into two major groups:
- Probability Sampling
- Non-Probability Sampling
Probability Sampling (Random Sampling):
In this type, data is randomly selected so that every observations of population gets the equal chance to be selected for sampling.
Probability sampling is of 4 types:
- Simple Random Sampling
- Cluster Sampling
- Stratified Sampling
- Systematic Sampling
Non-Probability Sampling:
In this type, data is not randomly selected. It mainly depends upon how the statistician wants to select the data.
The results may or maynot be biased with the population.
Unlike probability sampling, each observations of population doesn’t get the equal chance to be selected for sampling.
Non-probability sampling is of 4 types:
- Convenience Sampling
- Judgmental/Purposive Sampling
- Snowball/Referral Sampling
- Quota Sampling
Sampling Error:
Errors which occur during sampling process are known as Sampling Errors.
Or
Difference between observed value of a sample statistics and the actual value of a population parameters.
Mathematical Formula for Sampling Error:

Sampling error can be reduced by:
- Increasing the sample size
- Classifying population into different groups
Advantage of Sampling:
- Reduce cost and Time
- Accuracy of Data
- Inferences can be applied to a larger population
- Less resource needed
Resampling:
Resampling is the method that consist of drawing repeatedly drawing samples from the population.
It involves the selection of randomized cases with replacement from sample.
Note: In machine learning resampling is used to improve the performance of the model.
Types of Resampling:
Two common method of Resampling are:
- K-fold Cross-validation
- Bootstrapping
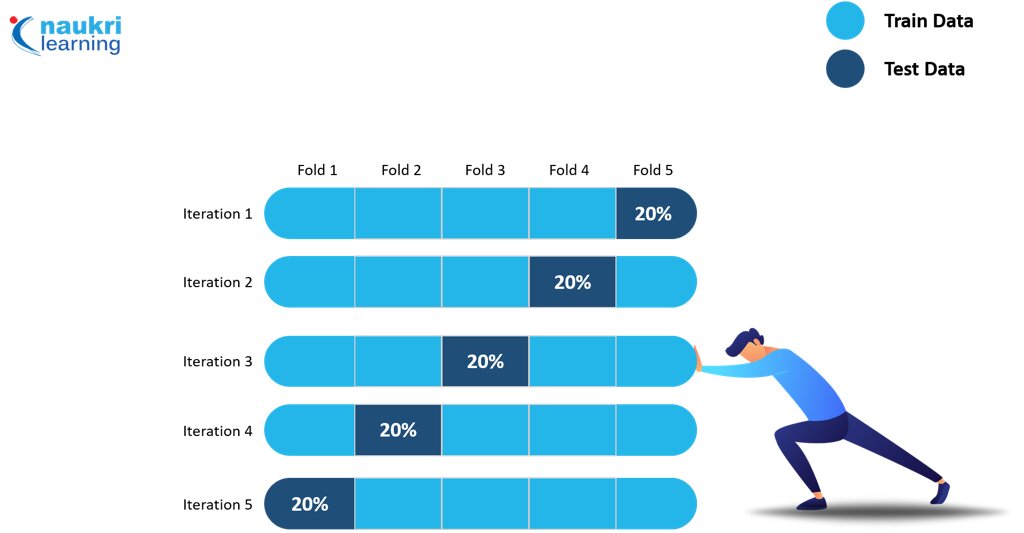
K-fold cross-validation:
In this method population data is divided into k equal sets in which one set is considered as the test set for the experiment while all other set will be used to train the model.
In first experiment, first set is considered as the test set and all other as trained set.
Process will be repeated k-time by choosing different sets as a test set.
Bootstrapping:
In bootstrapping, samples are drawn with replacement (i.e. one observation can be repeated in more than one group) and
the remaining data which are not used in samples are used to test the model.

Conclusion:
In this article, we briefly discuss different sampling and resampling methods. I hope this article helps you clarify the meaning of sampling and resampling.
Hope you will like the article.
Keep Learning!!
Keep Sharing!!
Top Trending Articles:
Data Analyst Interview Questions | Data Science Interview Questions | Machine Learning Applications | Big Data vs Machine Learning | Data Scientist vs Data Analyst | How to Become a Data Analyst | Data Science vs. Big Data vs. Data Analytics | What is Data Science | What is a Data Scientist | What is Data Analyst
Frequently Ask Question (FAQ)
Ques 1. What is Sampling?
Ans 1: Sampling is a process of selecting group of observations from the population, to study the characteristics of the data to make conclusion about the population.
Ques 2. What is Resampling?
Ans 2. Resampling is the method that consist of drawing repeatedly drawing samples from the population.
It involves the selection of randomized cases with replacement from sample.
FAQs
What is Sampling?
Sampling is a process of selecting group of observations from the population, to study the characteristics of the data to make conclusion about the population.
What is Resampling?
Resampling is the method that consist of drawing repeatedly drawing samples from the population. It involves the selection of randomized cases with replacement from sample.
