
Pandas Interview Questions for Data Scientists
For an aspiring data scientist, the most important data analytics libraries you need to be well-versed with are – NumPy and Pandas. We have already covered NumPy Interview Questions for Data Scientists. This article will help you brush up on your foundations of the Pandas library and prepare you for the most common Pandas Interview Questions that come up during Data Science interviews.

We will be covering the following sections today:
Quick Intro to Pandas

Pandas is an open-source Python library and the most popular package for data pre-processing in Data Science. It offers extensive features and powerful built-in functions that help with tasks such as data cleaning, data manipulation, data modeling, and analysis.
Let’s discuss the common Pandas-related questions you might come across during your interviews.
Pandas Interview Questions
What is meant by the mutability of objects?
Mutability refers to the ability to modify a portion of a data structure without needing to recreate it. Examples of mutable objects are lists, sets, and values in a dictionary.
Similarly, objects are said to be immutable if they cannot be modified once created. Examples of immutable objects are integers, floats, strings, tuples, and keys of a dictionary.
1. Discuss Pandas Data Structures.
Data Structures are basically a specialized way of organizing, processing, and storing data in a manner that one can operations on it.
Pandas offer two main data structures –
Pandas Series:
- 1D labeled array.
- Homogeneous i.e, the data types of series elements are the same.
- Size-immutable i.e., the size of series objects cannot be changed once created.
#pandas.DataFrame df = pd.DataFrame(data=None, index=None, columns=None, dtype=None)
| Index | Data |
| 0 | element 1 |
| 1 | element 2 |
| 2 | element 3 |
| 3 | element 4 |
Pandas DataFrames:
- 2D labeled tabular structure.
- Heterogeneous i.e, the data frame elements can have different data types.
- Size-mutable i.e., elements can be added or dropped from an existing data frame.
| Index | COlumn 1 | COLUMN 2 |
| 0 | element 1 | element a |
| 1 | element 2 | element b |
| 2 | element 3 | element c |
| 3 | element 4 | element d |
import pandas as pd #Creating a sample DataFrame df = pd.DataFrame({ 'id': [ 101, 129, 120, 126, 136, 125], 'age': [ 30, 32, 43, 45, 29, 46], 'gender': ['F', 'M', 'M', 'M', 'F', 'F'] }) df
2. How do you get the column names of your DataFrame?
import pandas as pd #Creating a sample DataFrame df = pd.DataFrame({ 'id': [ 101, 129, 120, 126, 136, 125], 'age': [ 30, 32, 43, 45, 29, 46], 'gender': ['F', 'M', 'M', 'M', 'F', 'F'] }) df Now, to get the column names of the DataFrame, we can try multiple ways –
- Iterating over columns and printing them:
for col in df.columns: print(col)

- Using columns() method that returns the column labels of the DataFrame:
list(df.columns)
- Using column.values() method that returns an array of indices:
list(df.columns.values)
- Using a sorted() method that returns the list of columns sorted in alphabetical order:
sorted(df)
3. How do you get the number of rows and columns of a Pandas DataFrame?
You can find this simply through the shape attribute which gives you the shape of the DataFrame:
df.shape
Thus, there are 6 rows and 3 columns in the DataFrame df.
4. How can you slice a Pandas DataFrame?
Slicing simply means extracting a subset of the DataFrame. To do this, you can just pass the relevant columns into the slicer as shown:
df[['age','id']]

5. How do you convert a Pandas Series to a DataFrame?
You can use the Series.to_frame() method to convert the series object to a DataFrame:
series = pd.Series(['butter','dynamite','daydream', 'friends']) col = 'bts' series.to_frame(name=col)

6. How do you convert a String to DateTime?
from datetime import datetime #Define dates in string format str1 = 'Wednesday, April 20, 2022' str2 = '4/20/22' str3 = '04-20-2022' #Define dates as datetime objects date1 = datetime.strptime(str1, '%A, %B %d, %Y') date2 = datetime.strptime(str2, '%m/%d/%y') date3 = datetime.strptime(str3, '%m-%d-%Y') #Print the converted dates print(date1) print(date2) print(date3)

You can use the datetime.strptime() method to convert a string to DateTime objects:
7. How do you add a single row to an existing DataFrame?
- Using a Series:
#Appending a single row with Series series = pd.Series([272, 22,'M'], index=['id', 'age', 'gender'] ) df.append(series, ignore_index=True)

- Using a Dictionary:
Please note that in this case, we would match the dictionary keys with the DataFrame columns:
#Appending a single row with a dictionary dict = {'id': 169, 'age': 54, 'gender': 'M'} df.append(dict, ignore_index=True)

8. How do you add multiple rows to an existing DataFrame?
- Using a DataFrame:
#Creating a new DataFrame that we want to append df2 = pd.DataFrame({ 'id': [1221, 1200, 1230], 'age': [36,53,26], 'gender': ['M','F','M'], }) #Appending multiple rows with DataFrame df.append(df2)

- Using a List of Dictionaries:
#Creating a list of lists mylist = [ [1434, 26, 'M'], [1578, 34, 'M'], [1301, 23, 'F'], [1207, 54, 'M'] ] #Converting a list of lists to a DataFrame df2 = pd.DataFrame(mylist, columns=df.columns) #Appending multiple rows with a list of lists df.append(df2, ignore_index=True)

- Using a List of Lists:
#Creating a list of lists mylist = [ [1434, 26, 'M'], [1578, 34, 'M'], [1301, 23, 'F'], [1207, 54, 'M'] ] #Converting a list of lists to a DataFrame df2 = pd.DataFrame(mylist, columns=df.columns) #Appending multiple rows with a list of lists df.append(df2, ignore_index=True)

9. How can you find the sum of values of a DataFrame column?
You can use the sum() function to return the sum of the values. This is done with the help of the following attributes:
- axis: specifies whether to sort for row (0) or columns (1).
- skipna: is set to True to skip all missing values.
df.sum(axis = 0, skipna = True)

Note: If the input is index axis, then all the values in a column are added and the same gets repeated for all the columns. This returns a series containing the sum of all the values in each column.
10. How and why should one create a copy of a DataFrame?
You can simply use the copy() method to copy your existing DataFrame:
df.copy()
During data manipulation, it is generally a safe practice to perform operations on the copy of the DataFrame rather than the original one. Even if you work with a subset of the DataFrame, any changes made to the subset would reflect on the original DataFrame because in Pandas, indexing a DataFrame returns a reference to the initial DataFrame. Thus, changing the subset will change the initial DataFrame.
So, to ensure that the initial DataFrame remains intact, you’d want to use copies and merge them all at the end.

 Read Later
Read Later
11. How do you sort a DataFrame?
You can use the sort.values() method to sort a DataFrame by its rows or columns. This can be done with the help of the following attributes:
- by: specifies the column/row(s) that determine the sorting order.
- axis: specifies whether to sort for row (0) or columns (1).
- ascending: by default, a DataFrame is sorted in ascending order. You can specify ascending=False to sort in descending order.
#Sort by a single column df.sort_values(by=['age'])
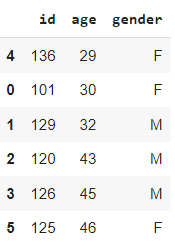
#Sort by multiple columns df.sort_values(by=['age', 'id'])

#Sort in descending order df.sort_values(by='age', ascending=False)

12. How can you merge two DataFrames?
You can use the merge() method to combine you DataFrames with SQL-style join methods. There are 4 types of joins that you can pass to an optional argument how –
- inner (default): output DataFrame consists of records that have the same values in both DataFrames:

#Creating two dataframes data1 = pd.DataFrame({"Roll No.": [101, 103, 104, 107, 106], "Gender": [ 'M', 'F', 'F', 'M', 'M'], "Name": ['Rob', 'Pam', 'Max', 'Tom', 'Ben'] }) data2 = pd.DataFrame({"Roll No.": [101, 102, 103, 104, 105], "Age": [31, 35, 36, 30, 38] }) #Inner merge df_merge = pd.merge(left=data1, right=data2, how='inner') df_merge

- outer: output DataFrame consists of all records with matching values in either the left or right DataFrame. If rows match, values are shown. Else, NaN is displayed:

#Outer merge
df_merge = pd.merge(left=data1, right=data2, how=’outer’)
df_merge

- left: output DataFrame consists of all records from the left DataFrame and only the matched records from the right DataFrame:

#Left join df_merge = pd.merge(left=data1, right=data2, how='left') df_merge

- right: output DataFrame consists of all records from the right DataFrame and only the matched records from the left DataFrame:

#Right join df_merge = pd.merge(left=data1, right=data2, how='right') df_merge

13. How do you deal with a dataset consisting of missing values?
For larger datasets, the quickest way to deal with missing values is to simply remove the entire rows containing the missing values as this will not affect our predictions in any way.
For smaller datasets, you can substitute the missing values with the average/mean values or zeros by performing operations on the dataframe. For this, you can use methods such as mean(), fillna(0).
df_merge.fillna(0)

14. What is the difference between fillna() and interpolate() methods?
The fillna() method fills the missing or NaN values with a substitute value specified by you. You can fill according to the row indices of a DataFrame or the column names in the form of a Python dictionary.
On the other hand, the interpolate() method allows you to fill your missing or NaN values with many kinds of interpolations between the values like linear, time, etc.
15. How to group DataFrame rows in a list?
You can use the groupby() method to group on the specified column and then use the apply() method to apply a list to every group:
df1 = df.groupby(‘age’)[‘gender’].apply(list).reset_index(name=’new’)
df1

16. How do you delete a column or a row from a Pandas DataFrame?
You can use the drop() method to delete a column from the DataFrame. This can be done with the help of the following attributes:
- axis: specifies whether to sort for row (0) or columns (1).
- inplace: can be set to True to delete a column without reassigning the DataFrame.
- ascending: by default a DataFrame is sorted in ascending order. You can specify ascending=False to sort in descending order.
#Dropping a single column df.drop(['gender'], axis = 1)

#Dropping multiple columns df.drop(['gender', 'id'], axis = 1)

#Dropping multiple columns df.drop(['gender', 'id'], axis = 1)

Note: You can also remove duplicate values from the column by using the drop_duplicates() method.
17. How can you encode a large Pandas DataFrame?
For a DataFrame with a lot of columns (aka features), encoding a label to each feature is not efficient. So, we can use a LabelEncoder to encode a Pandas DataFrame having string or numerical labels. This can be done using Python’s scikit-learn library:
OneHotEncoder().fit_transform(df)
18. How can you split your Pandas DataFrame into training and testing sets?
You can use Python’s scikit-learn library to split both NumPy arrays and Pandas DataFrames into training and testing sets to be used for creating ML models. For this, you can import train_test_split to perform the split:
from sklearn.model_selection import train_test_split train, test = train_test_split(df, test_size=0.2)
The above code splits the DataFrame into 20% testing set and 80% training set.
19. How can you randomly sample rows from a pandas DataFrame?
In pandas, you can use the
sample()
df.sample(n=5)
df
df.sample(frac=0.25)
sample()
replace
True
random_state
20. What are loc and iloc methods in Pandas?
The loc[ ] method
It is a label-based method that is used for selecting data and updating it. You can do so by passing the row or column label you want to select.
Syntax:
loc[row_label, column_label]
The iloc[ ] method
The iloc[ ] is an index-based method that is used for data selection. Here, you can pass the row or column positions that you want to select (0-based integer index).
Syntax: iloc[row_position, column_position]
Learn more about the difference between loc and iloc in Pandas.
Endnotes
Hope this article will be helpful for your Data Science as well as Pandas interview preparations. You can also find a similar article on NumPy Interview Questions. If you seek to learn more about Python and its library, you can explore related articles here.
———————————————————————————-

This is a collection of insightful articles from domain experts in the fields of Cloud Computing, DevOps, AWS, Data Science, Machine Learning, AI, and Natural Language Processing. The range of topics caters to upski... Read Full Bio