
Powerful Python Libraries for Data Science and Machine Learning
Python is among the most popular programming languages used in data science, machine learning as well as deep learning. The credit for such popularity goes to its ease of applicability and collection of Python libraries for data science. Python libraries are extensive and consist of modules that allow access to system functionalities such as file input and output, standardized solutions to programming problems, etc.

A plus for Python libraries for data science is that it has a collection of thousands of components such as individual programs, modules, packages, frameworks, applications, and much more that you find in the Python Package Index. So explore the article and learn about the top Python libraries available for data scientists. The best part is, they are free!
You may also be interested in exploring:
To learn more about Python, read our blog on – What is Python?
Best Python Libraries
1. Matplotlib
2. NumPy
3. Pandas
4. Scikit-Learn
5. TensorFlow
6. Keras
7. PyTorch
8. Theano
9. Scrapy
10. Seaborn
Best-suited Python for data science courses for you
Learn Python for data science with these high-rated online courses

Matplotlib
Matplotlib is among the most talked-about Python libraries. It is a cross-platform library that facilitates data visualization and graphical plotting while ensuring fast processing and high-quality graphics generation. Its usability is in creating different types of Python scripts, web application servers, and GUI manuals.
You can publish this data physically in print as well as digitally. It uses 2D paths and different types of graphics created with fewer codes. Sample plots in Matplotlib include – Line Plot, Histograms, Contouring and Pseudocolor, Images, Three-Dimensional Plotting, Paths, and Multiple Subplots in one figure.

Image – Sample plots in Matplotlib
Features of Matplotlib
- Functions with various operating systems and graphics backends
- Offers two types of interfaces – MATLAB-style state-based interface, and an object-oriented interface, which is more powerful
- Supports numerous back ends and output types, which means you can work seamlessly with any operating system
- It is cross-platform and has an everything-to-everyone approach
- Saves images in a variety of formats; the use command is savefig()
NumPy
NumPy allows you to create a universal data structure to facilitate its analysis and exchange of various algorithms. Like many Python libraries, it implements multidimensional vectors and matrices that store a large amount of data. In turn, it has high-level mathematical functions and uses data structures. NumPy is very good for data analysis. It can replace MATLAB, OCTAVE, etc. as it offers similar functionality and support with faster development and less mental overhead.

Features of Numpy
- It is written in C, offering it a very high speed and facilitating working with large data sets
- It uses many types of operational functions, logic, ordering, statistics, input, and output to read and write files, and so on
- Numpy is a fairly large library and together with Pandas, is very effective
- NumPy facilitates advanced mathematical operations on huge data sets
- Has the ability to create subsets
- Numpy supports specific scientific functions like linear algebra
- Numpy supports vectorized operations, such as addition and multiplication by elements, the computation of the Kronecker product, and so on
Popular Python Course Providers:
| Top Python Courses by Udemy | Popular Python Courses by Coursera |
| Top Python Courses by Udacity | Popular Python Courses by PluralSight |
Pandas
Pandas is a software library written as an extension of Numpy. Its application is in data manipulation and data analysis for Python. It offers data structures for manipulating number tables and time series. Pandas has tools to read and write data between data structures in memory and various file formats. It is used more in fields such as finance, social sciences, statistics, and engineering. It is easy to use.
Features of Pandas
- Enables data alignment
- Allows easy handling of missing data
- Allows data set restructuring and segmentation, tag-based vertical segmentation, elegant indexing, and horizontal segmentation of large data sets
- Enables insertion and removal of columns in data structures
- You can perform chains of operations, divide, apply and combine data sets, mixing and joining of data.
- Allows performing hierarchical indexing of axes to work with high-dimensional data in less-dimensional data structures
- Enables functionality of time series – generation of date ranges and frequency conversion, displacement of statistical windows and linear regressions, date displacement, and delays
Read – Statistical Methods Every Data Scientist Should Know
Scikit-Learn
Scikit-Learn is an open-source library written in python and is extensively used in data analysis, data mining, and statistical modeling. It is a very easy-to-use tool thanks to its multiple machine learning algorithms. Scikit-Learn has applicability in solving classification and regression problems, including SVMs, decision trees, linear regression, polynomial regression, clustering, etc. Its interface is simple and consistent and can be modeled only with one line of code. It can handle both supervised and unsupervised learning.

Features of Scikit-Learn
- Easily accessible to all
- Built on the basis of NumPy, SciPy, and Matplotlib
- Open source, commercially usable
- Preprocessing, including Min-Max Normalization
- Linear and Logistic Regression
Check out the best Python Courses online
TensorFlow
TensorFlow is an end-to-end and open source software library. This open-source development by Google uses data flow graphs and goes beyond data science and artificial intelligence. Its wide applicability has made it a popular Deep Learning tool. TensorFlow is an excellent platform to build and train neural networks, ensuring the detection of different types of patterns. It is effectively used for numerical computing.

The TensorFlow API is built on –
- Linear Regression: tf.estimator.linearRegresor
- Classification: tf.estimator.linearClassifier
- Deep Learning Classification : TF.Estimator.DNNClassifier
- Reinforcement Tree Regression: TF.Estimator.BoostedTreesRegressor
- Boosted Tree Classification: TF.Estimator.BoostedTreesClassifier
Features of TensorFlow
- Enables building and training machine learning models using high-level APIs like Keras
- Computational deployment to multiple CPUs or GPUs on different devices and platforms with a single API
- Easily train and deploy models both locally and on cloud
- Provides powerful experimentation for research
Also Read – What is Data Science?
Keras
Keras is an open-source deep-learning library. It is written in Python and it scales up the speed of neural network creation. Keras uses an intuitive user interface (API) that allows access to different machine learning frameworks and also develops them. Keras works on the model level and provides building blocks upon which complex deep learning models can be built. It shares similar functions to other Python libraries like TensorFlow and CNTK. Keras relies especially on the TensorFlow, Theano, and Microsoft Cognitive Toolkit tools, for which there are ready-to-use interfaces that allow quick and intuitive access to the corresponding backend.

Features of Keras
- Wide cross-platform compatibility for developed models including iOS (Apple CoreML), Android (Keras TensorFlow Android Runtime), Google Cloud, and Raspberry Pi
- Multiple backend engine support. It also enables transferring the developed models to another backend
- Excellent support for multiple GPUs
PyTorch
PyTorch is an open-source library for Python. It is closely related to the lua-based Torch framework that is actively used on Facebook. This is one of the popular Python libraries for machine learning and deep learning applications such as natural language processing. PyTorch provides a Python package for high-level functions like tensor calculus (like NumPy) with strong GPU and TorchScript acceleration for a smooth transition between eager and graphics modes.

Features of Pytorch
- Hybrid front end to ensure ease of use and flexibility
- Deeply integrated into Python
- Integrates with Python data science stack
- Offers dynamic computer graphics, helpful in building neural network models
- Includes implementation for mobile and embedded frameworks
Check out the most commonly asked Python Interview Questions and Answers
Theano
Theano is one of the most popular Python libraries these days as it helps to define mathematical expressions used in machine learning. Users can optimize the expressions and evaluate them through the decisive use of GPUs in critical areas seamlessly. Various machine learning and artificial intelligence applications are the repetitive calculation of a complicated mathematical expression, Theano allows you to perform data-intensive calculations up to a hundred times faster.
Features of Theano
- Deep integration with NumPy – Use numpy.ndarray in Theano-compiled functions
- Transparent GPU usage – Perform data-intensive calculations much faster than on a CPU
- Efficient symbolic differentiation – Theano derives its derivatives for functions with one or more inputs
- Speed and stability optimization
- Dynamic C code generation: Evaluate expressions faster
- Extensive unit testing and self-testing – Detect and diagnose multiple types of errors
Scrapy
Scrapy is a Python framework that is widely used for scraping websites. Scrapy is widely used to extract, store and process humongous web data. Scrapy allows us to manage a large amount of data with ease. Some of the main applications of Scrapy include web-scraping, data mining, and other information, which can be used in decision-making. Scrapy has found its way to data science and machine learning applications as it helps in data collection, data storage, and data analysis to draw meaningful conclusions.
Seaborn
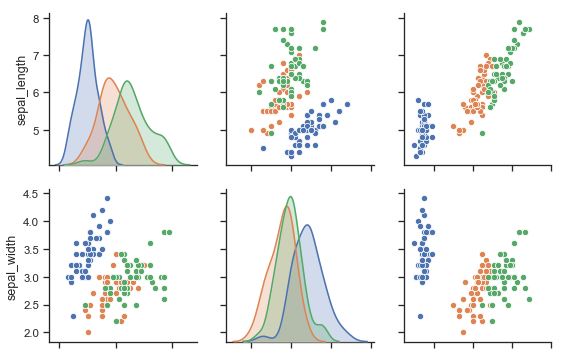
Seaborn is a data visualization library built on Matplotlib. This library gives you the ability to create informative images and statistics, questions, as well as illustrative graphics. Seaborn combines the essentials of aesthetics with technical insights, making it a crucial Python for data science library. The library is perfect to analyze relationships between different variables. Seaborn does all the important statistical and semantic map aggregation in-house to produce informative graphics.
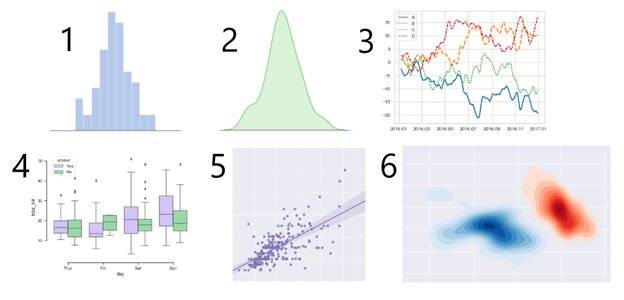
Image – Data visualization in Seaborn
Features of Seaborn
- It has several built-in themes to improve Matplotlib layout
- It has tools for choosing color palettes
- Functions to visualize data matrices and compare subsets of data
- Tools to adapt and visualize linear regression models
- It can help in establishing statistical time series with the data
Conclusion
I hope this article has guided you in deciding which libraries you should pick as per your personal interest and professional requirements. If you are someone who is working on Python then it is always a good idea to have information about which library does what! This list of libraries is not complete; I will keep on updating this article with Python libraries useful in data science and machine learning.
Keep Learning!
FAQs
What is the use of libraries in Python?
Python Libraries eliminate the use of writing codes from scratch and are very helpful in developing machine learning, data science, and data visualization applications.
How many Python Libraries are available?
Pythonu2019s standard library is very extensive. There are over 137,000 Python libraries that offer a wide range of applications and provide standardized solutions for many problems in day-to-day programming.
Are all Python Libraries open source?
Python holds an OSI-approved open source license, thus it is freely usable and distributable, irrespective of its use. So yes, all Python Libraries are open source.
Where are the Python Libraries stored?
Python Libraries are usually located /lib/site-packages in your Python folder. sys. path can be used to find out the Python Libraries.
How can I create a Python library?
Below are the steps to create a Python library - 1: Create a directory where the library should be located 2: Create a virtual environment for your folder 3: Create a folder structure 4: Create content for your library 5: Build your library

Rashmi is a postgraduate in Biotechnology with a flair for research-oriented work and has an experience of over 13 years in content creation and social media handling. She has a diversified writing portfolio and aim... Read Full Bio