
Series vs. DataFrame in Pandas – Shiksha Online
In this tutorial, we are going to learn the two most common data structures in Pandas – Series and DataFrame.

Pandas is a very popular open-source Python library that offers a diverse set of tools that aid in performing data analysis more efficiently. The Pandas package is mainly used for data pre-processing purposes such as data cleaning, manipulation, and transformation. Hence, it is a very handy tool for data scientists and analysts. In this article, we cover the two most common data structures in Pandas – Series and DataFrame, and also Series vs DataFrame.
We will cover the following sections:
Installing and Importing Pandas
First, let’s install the pandas library in your working environment. Execute the following command in your terminal:
pip install pandas
Now let’s import the libraries we’re going to need today:
import pandas as pdimport numpy as np
Best-suited Python for data science courses for you
Learn Python for data science with these high-rated online courses

Data Structures in Pandas
Data Structure refers to the specialized way of organizing, processing, and storing data to apply specific types of functionalities to them.
Pandas has two main types of Data Structures based on their dependability –
- Series: 1D labeled array
- DataFrame: 2D labeled tabular structure
Series vs DataFrame
Let’s summarize the difference between the two structures in a table:
| Pandas Series | Pandas DataFrame |
| One-dimensional | Two-dimensional |
| Homogenous – Series elements must be of the same data type. | Heterogenous – DataFrame elements can have different data types. |
| Size-immutable – Once created, the size of a Series object cannot be changed. | Size-mutable – Elements can be dropped or added in an existing DataFrame. |
Now that we have a fair idea about Series and DataFrame, let’s see how we create them in Python, shall we?
Pandas Series
- Creating a Pandas Series Using Dictionary
- Creating a Pandas Series Using ndarray
- Creating a Pandas Series Using Scalar Values
As stated above, Pandas Series is a one-dimensional labeled array whose object size cannot be changed. You can also see it as the primary building block for a DataFrame, making up its rows and columns.
Following is the basic method to create a Series:
#pandas.Seriesseries = pd.Series(data=None, index=None, dtype=None, name=None)
| Index | Data |
| 0 | element 1 |
| 1 | element 2 |
| 2 | element 3 |
| 3 | element 4 |
The data parameter can take any of the following data types:
- Python dictionary (dict)
- ndarray
- A scalar value
The index parameter accepts list data type that allows you to label your index axis.
The dtype parameter sets the data type of the Series.
The name parameter allows you to name your Series.
Creating a Pandas Series Using Dictionary
If data is of dict type and index is not specified, the dict keys will be the index labels.
#Creating a Series from dictdata = {'Mon': 22, 'Tues': 23, 'Wed': 23, 'Thurs': 24, 'Fri': 23, 'Sat': 22, 'Sun': 21}series = pd.Series(data=data, name='series_from_dict')print(series)

Creating a Pandas Series Using ndarray
If data is a ndarray, the index must be of the same length as the array. If index is not specified, it will be created automatically with values: [0, …, len(data) – 1].
NumPy library has a function random.randint() that produces a ndarray populated with random integers, let’s use that here:
#Creating a Series from ndarraydata = np.random.randn(5)series = pd.Series(data=data, index=['one', 'two', 'three', 'four', 'five'], name='series_from_ndarray')print(series)
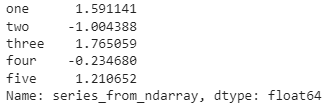
Creating a Pandas Series Using Scalar Values
The data can be assigned a single value. The index has to be provided in this case. The given value will be repeated up to the length of the index.
#Creating a Series from a scalar valueseries = pd.Series(data=7.3, index=['a', 'b', 'c', 'd'], name='series_from_scalar')print(series)

Pandas DataFrame
Pandas DataFrame, on the other hand, is a two-dimensional structure with columns and rows whose size can be changed. You can also think of it as a dictionary of Series objects.
- Creating a Pandas DataFrame Using a Dictionary of Pandas Series
- Creating a Pandas DataFrame Using a Dictionary of Lists or ndarrays
- Creating a Pandas DataFrame Using a List of Dictionaries
- Creating a Pandas DataFrame Using a Series
Following is the basic method to create a DataFrame:
\n \n \n <pre class="python" style="font-family:monospace">\n \n \n <span style="color: #808080;font-style: italic">\n \n \n #pandas.DataFrame\n \n \n \n \n \n </span style="color: #808080;font-style: italic">\n \n \n </pre class="python" style="font-family:monospace">
df = pd.DataFrame(data=None, index=None, columns=None, dtype=None)
| Index | COlumn 1 | COLUMN 2 | |
| 0 | element 1 | element a | |
| 1 | element 2 | element b | |
| 2 | element 3 | element c | |
| 3 | element 4 | element d |
The data parameter can take any of the following data types:
- Dictionary (dict) of – 1D ndarray, lists, or Series
- 2D ndarray
- Pandas Series
- Another Pandas DataFrame
The index parameter can be passed optionally, and it accepts row labels.
The columns parameter can also be passed optionally, and it accepts column labels.
The dtype parameter sets the data type of the DataFrame.
Creating a Pandas DataFrame Using a Dictionary of Pandas Series
The index must be the same length as the Series. If index is not specified, it will be created automatically with values: [0, …, len(data) – 1].
#Creating a DataFrame from a dictionary of Seriesdata = pd.DataFrame({ "Class 1": pd.Series([22, 33, 38], index=["math avg", "science avg", "english avg"]), "Class 2": pd.Series([45, 28, 36], index=["math avg", "science avg", "english avg"]), "Class 3": pd.Series([32, 41, 47], index=["math avg", "science avg", "english avg"])}) data
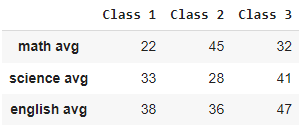
Creating a Pandas DataFrame Using a Dictionary of Lists or ndarrays
The ndarrays must all be of the same length. The index must be the same length as the arrays. If the index is not specified, the result will be range(n), where n is the array length.
Let’s create the same DataFrame, but this time using lists/ndarrays:
#Creating a DataFrame from a dictionary of listsdata = { "Class 1": [22, 33, 38], "Class 2": [45, 28, 36], "Class 3": [32, 41, 47]}df = pd.DataFrame(data=data, index=['math avg', 'science avg', 'english avg']) df
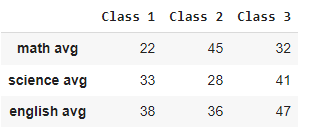
Creating a Pandas DataFrame Using a List of Dictionaries
#Creating a DataFrame from a list of dictionariesdata = [{"col1": 1, "col2": 2}, {"col1": 5, "col2": 10, "col3": 20}] pd.DataFrame(data)
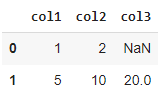
Creating a Pandas DataFrame Using a Series
When you create a DataFrame using a Series, the resulting DataFrame will have one column whose name is the original name of the Series:
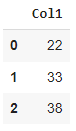
#Creating a DataFrame from a Seriesdata = pd.DataFrame({"Col1": pd.Series([22, 33, 38])})data
After the creation of a DataFrame, you can query it and select, add, or delete columns from it, i.e., perform Data Manipulation.
Pandas DataFrame can be queried in multiple ways – such as loc[] and iloc[] methods – .iloc[] can be used to query using the index/position of the value and .loc[] to query using the user-defined keys.
Endnotes
Pandas is a very powerful data processing tool for Python. It offers a rich set of functions to import and process various types of file formats from multiple data sources. The Pandas library is specifically useful for data scientists working with data cleaning and analysis. Hope this article on Series vs DataFrame helped you understand the concept better.
Top Trending Articles:
Data Analyst Interview Questions | Data Science Interview Questions | Machine Learning Applications | Big Data vs Machine Learning | Data Scientist vs Data Analyst | How to Become a Data Analyst | Data Science vs. Big Data vs. Data Analytics | What is Data Science | What is a Data Scientist | What is Data Analyst

This is a collection of insightful articles from domain experts in the fields of Cloud Computing, DevOps, AWS, Data Science, Machine Learning, AI, and Natural Language Processing. The range of topics caters to upski... Read Full Bio