
Tutorial – VLOOKUP in Pandas
VLOOKUP is a common Excel function that stands for ‘Vertical Lookup’. The article discusses the use of VLOOKUP in Pandas.

We already know that Pandas DataFrames are tabular data structures that store data similar to an Excel or CSV file – in rows and columns. VLOOKUP is a common Excel function that is essentially used for vertically arranged data and allows you to map data from one table to another. In Pandas, VLOOKUP merges two DataFrames if both have a common attribute (column). You can perform VLOOKUP in Pandas using map() and merge() methods as discussed in this article:
For our purpose today, let’s create a sample DataFrame as shown below:
#Importing Pandas Libraryimport pandas as pd #Creating a Sample DataFramedf = pd.DataFrame({ 'name': [ 'Bob', 'Tom', 'Rob', 'Ben', 'Pam'], 'age': [ 10, 12, 13, 11, 12], 'gender': [ 'M', 'M', 'M', 'M', 'F'], 'birthmonth': [ 'Jan', 'Aug', 'Oct', 'Dec', 'Dec']}) df

Our dummy dataset comprises of 4 columns – ‘name’, ‘age’, ‘gender’, and ‘birthmonth’. As you can observe, it contains both numerical and categorical variables.
Now, let’s see how we can emulate using the VLOOKUP function in Pandas through this dataset.
The map() method
The pandas .map() method allows us to map values to a Pandas Series, or a column in a Pandas DataFrame. This can be done using a dictionary, where the key is the corresponding value in our Pandas column and the value is the value that we want to map into it.
To understand this better, let’s create a dictionary that contains our mapping values:
birthmonth_map = { 'Jan': 'January', 'Aug': 'August', 'Oct': 'October', 'Dec': 'December'}
Now, we will apply the map() method to the column that we want to map into:
df[‘birthmonth’] = df[‘birthmonth’].map(birthmonth_map)
df

Thus, we have performed VLOOKUP using a dictionary.
But what if the data is stored in another DataFrame, as is when working with relational databases like SQL? In such cases, instead of working with Python dictionaries, we use the merge() method.

 Read Later
Read Later
Best-suited Python for data science courses for you
Learn Python for data science with these high-rated online courses

The merge() method
The pandas .merge() method allows us to merge two DataFrames together.
In the DataFrame we created above, we have a column ‘age’ that corresponds to the year a child was born in. Let’s create another DataFrame that contains the mapping values (birth year) for the age:
#Creating another DataFramedf2 = pd.DataFrame({ 'age': [10, 11, 12, 13, 14, 15], 'birthyear': [2012, 2011, 2010, 2009, 2008, 2007]}) df2

Now, let’s see how we can merge the two different DataFrames using the merge() method:
df = pd.merge(left=df, right=df2, how='left')df

Note that VLOOKUP is essentially a left join between two tables, that is, the output consists of all the rows in the left table and only the matched rows from the right table.
- The arguments left and right are positional parameters that choose which DataFrames to use as your left and right tables in the join.
- The how parameter sets how the tables have to be joined: left, right, inner, or outer.

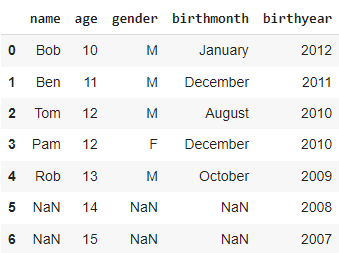
Performing VLOOKUP on right join
In the right join, the output DataFrame consists of all the rows in the right DataFrame and only the matched rows from the left DataFrame. The unmatched rows will be replaced by NaN values.
df = pd.merge(left=df, right=df2, how='right')df
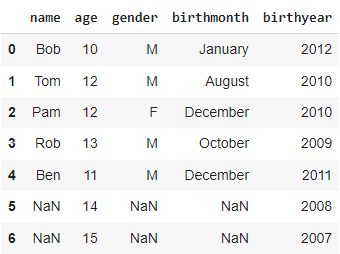
Performing VLOOKUP on inner join
By setting the how parameter to inner, the final DataFrame will contain only the rows for which the condition is satisfied in both the DataFrames.
inner_join = pd.merge(df, df2, on ='age', how ='inner')inner_join


Performing VLOOKUP on outer join
By setting the how parameter to the outer, the final DataFrame will contain rows from both the DataFrames. If rows are matched, values will be shown. If rows do not match, NaN will be displayed.
outer_join = pd.merge(df, df2, on ='age', how ='outer')outer_join
Thus, we have performed VLOOKUP on four types of joins.
Endnotes
The Pandas library makes it incredibly easy to emulate VLOOKUP functions. Mapping and merging data are essential steps during your data preparation, especially if you’re working with normalized datasets from databases. Pandas is a very powerful data processing tool and provides a rich set of functions to process and manipulate data for analysis.
Top Trending Articles:
Data Analyst Interview Questions | Data Science Interview Questions | Machine Learning Applications | Big Data vs Machine Learning | Data Scientist vs Data Analyst | How to Become a Data Analyst | Data Science vs. Big Data vs. Data Analytics | What is Data Science | What is a Data Scientist | What is Data Analyst

This is a collection of insightful articles from domain experts in the fields of Cloud Computing, DevOps, AWS, Data Science, Machine Learning, AI, and Natural Language Processing. The range of topics caters to upski... Read Full Bio