
What is MapReduce in Hadoop?
With the help of the MapReduce framework, we can create applications that reliably process massive volumes of data in parallel on vast clusters of commodity hardware. In this article, we will discuss MapReduce in detail along with its algorithm, terminology, and architecture.
Big data has garnered immense interest among many organisations across industries who are looking to get the most out of the information they have. A sub-project of Hadoop, MapReduce is one of the important big data processing tools and have increased in popularity in the recent years.
What is MapReduce?
Java-based MapReduce is basically a processing method and a model for a distributed computing program. Map and Reduce are two crucial jobs that make up the MapReduce algorithm. A data set is transformed into another set through a map, where each element is separated into tuples key or value pairs. The second work is a reduced task, that takes a map’s output as input and concatenates the data objects in a smaller collection of tuples. The reduction work is always carried out following the map job, as the name MapReduce implies.
The main benefit of MapReduce would be that data processing can be scaled easily over several computing nodes. The primitives of data processing used in the MapReduce model are referred to as mappers and reducers. Sometimes it is difficult to divide a data application into reducers and mappers. However, scaling an application running over thousands, or even more servers in a cluster is just a configuration modification after it has been written in the MapReduce manner. The MapReduce approach has gained popularity among programmers due to its straightforward scalability.
A MapReduce program usually executes in three stages — map stage, shuffle stage and reduce stage.
- Map stage – In this stage, the input data is split into fixed sized pieces known as input splits. Each input split is passed through a mapping function to produce output values.
- Shuffle stage – The output values from the map stage is consolidated in the next stage, which is the shuffle stage.
- Reduce stage – The output from the shuffle stage is are combined to return a single value and is stored in the HDFS.
Best-suited Apache Hadoop courses for you
Learn Apache Hadoop with these high-rated online courses

What are the strengths of MapReduce?
Apache Hadoop usually has two parts, the storage part and the processing part. MapReduce falls under the processing part. Some of the various advantages of Hadoop MapReduce are:
- Scalability – The biggest advantage of MapReduce is its level of scalability, which is very high and can scale across thousands of nodes.
- Parallel nature – One of the other major strengths of MapReduce is that it is parallel in nature. It is best to work with both structured and unstructured data at the same time.
- Memory requirements – MapReduce does not require large memory as compared to other Hadoop ecosystems. It can work with minimal amount of memory and still produce results quickly.
- Cost reduction – As MapReduce is highly scalable, it reduces the cost of storage and processing in order to meet the growing data requirements.
Also read>> Top MapReduce Interview Questions
Architecture of MapReduce
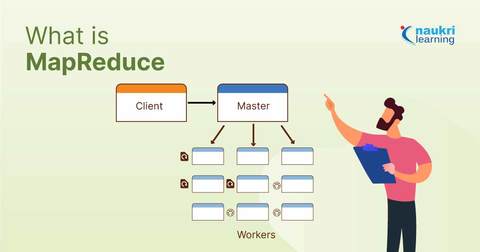
Let us see the components of MapReduce architecture below:
- Client: The Job is brought to the MapReduce for processing by the MapReduce client. There may be a number of clients accessible that continuously send jobs to the Hadoop MapReduce Manager for processing.
- The client wished to complete a MapReduce job, which is made up of numerous smaller tasks that the client wishes to process or carry out.
- MapReduce in Hadoop: It separates the specific job into succeeding job parts.
- Work-Parts: The duties or sub-jobs that result from splitting the primary job. the end product is produced when all the job parts are integrated.
- Input Data: The data set provided to MapReduce for processing is known as the input data.
- Output Information: After processing, the ultimate outcome is discovered.

We have a client within MapReduce. A job of a specific size will be submitted by the client to a Hadoop MapReduce Master. This work will now be divided into additional equivalent job parts by the MapReduce master. The Map and Reduce Task will then have access to these job parts. This Map and Reduce task will include the program in accordance with the specifications of the use case that the specific business is resolving. The developer creates their logic to satisfy the specifications set forth by the sector. The map task is then supplied with the input data that we are utilizing, and the map will provide an intermediary key-value pair just like its output.
The Reducer receives the output of the Map, or these key-value pairs, and stores the result on the HDFS. It is possible to create n different Map and Reduce tasks to process the data as needed. The Map and Reduce algorithm has been carefully designed to have the least amount of time or space complexity.
Understanding MapReduce Algorithm
The MapReduce paradigm typically relies on delivering the computer to the location of the data!
The MapReduce program runs in 3 parts: the map phase, the shuffle phase, and the reduction phase.
- Map Stage: The task of the mapper is to analyze the input data at this level. In most cases, the input data is kept in the Hadoop file system as a file or directory (HDFS). The mapper function receives the input file line by line. The mapper processes the data and also produces a number of little data chunks.
- Reduce Stage: The shuffle stage and Reduce stage are combined to create the Reduce stage. Processing the data that arrives from the mapper is the Reducer’s responsibility. Following processing, it generates a fresh set of outputs that will be kept in the HDFS.
- Hadoop assigns both Map and Reduce jobs to the proper cluster computers during a MapReduce job.
- The framework controls every aspect of data-passing, including assigning tasks, confirming their completion, and transferring data across nodes within a cluster.
- The majority of computing is done on nodes having data stored locally on drives, which lowers network traffic.
- After the assigned tasks are finished, the cluster gathers and minimizes the data to create the necessary results, then delivers it directly to the Hadoop servers.

Key Terminologies related to Map Reduce
Payload: The core of the work is represented by the PayLoad applications, which implement the Map and Reduce functions.
Mapper: A mapper converts a series of intermediate key/value pairs from the input key/value pairs.
NamedNode: Node that oversees the Hadoop Distributed File System is namedNode (HDFS).
DataNode: A node where data is first provided before being processed.
Masternode: JobTracker is run on the MasterNode, which also receives job requests from clients.
Slavenode: The Map and Reduce software runs on the SlaveNode.
JobTracker: Jobs are scheduled and tracked in JobTracker before being assigned to Task Tracker.
Task Tracker: Tracks the task and updates JobTracker on its progress.
Job: A job is a program that runs a Reducer and a Mapper on a dataset.
Task: The process of running a Mapper or Reducer on a data slice.
Task Attempt: A specific instance of a task execution attempt on a slave node.
What are the advantages of getting a MapReduce certification?
Big data is a growing field and offers lucrative job opportunities. If you want to start a successful career as a big data developer or a big data architect, you should look at the various advantages a certification in MapReduce offer:
- A certification in MapReduce will showcase your ability and skills in the framework, making it easy for recruiters to understand if you are the right person for the job.
- There can be many candidates vying for the same job or position that you are looking for in an organisation. However, if you are the only one with a certification, it can speak in favour of you.
- Based on a Naukri survey, 67% of the recruiters mentioned that they prefer certified candidates and are also willing to pay higher.
- It strengthens your resume and you can stand out whenever you are applying for a job.
What are the top MapReduce certifications you can go for?
There are a number of Hadoop MapReduce certifications which can help you in becoming a successful big data professional. Some of the mentionable courses in Shiksha Online are:
- Apache Hadoop and MapReduce Essentials Certification – This course has been designed to provide the essential training to candidates on cloud computing with the help of Apache Hadoop and MapReduce. It also offers an understanding of the Hive programming using real-life projects.
- Big Data and Hadoop Spark Developer Certification – Get a comprehensive understanding of big data analysis through Hadoop, using frameworks like MapReduce, Yarn, Spark, Pig, Hive, Impala and HBase.
- Hadoop Analyst Certification – This is an intensive training course that will help candidates to gain valuable practical knowledge on big data analysis using frameworks like MapReduce and HDFS. It will also give you a fundamental understanding of Pig and Impala.
With the above professional online course in MapReduce, you will get to have hands-on experience in working with big data, using Hadoop. Get a Hadoop certification and boost your career.
Also read>> Top Hadoop Interview Questions
Conclusion
In this article, we have discussed MapReduce. We have discussed the components and architecture of MapReduce. Java-based MapReduce is basically a processing method and a model for a distributed computing program. Map and Reduce are two crucial jobs that make up the MapReduce algorithm. Here, we have also talked about the algorithms and terminology that work on MapReduce.
Author: Megha Chadha

This is a collection of insightful articles from domain experts in the fields of Cloud Computing, DevOps, AWS, Data Science, Machine Learning, AI, and Natural Language Processing. The range of topics caters to upski... Read Full Bio