
A Comprehensive Guide to Convolutional Neural Networks
CNN is a supervised deep neural network that is used in deep learning. In this article we will learn the architecture of CNN, hyperparameters used in CNN and the applications of CNN.

CNN also known as Convolutional Neural Network or ConvNet, is a supervised deep neural network used in deep learning. Humans can see the environment, and they can identify and distinguish objects using their eyes but for computers to identify the pattern in the image and to distinguish them, we use CNN.
Also, read: Different types of neural networks in deep learning
All images have many square-sized boxes called pixels. Pixels are the smallest unit of an image. Greyscale images are 2D-array, and the color images are 3D-array. In 2D, the height and width of an image. In 3D, the third dimension corresponds to RGB colors in each pixel. Now, all these pixel values will be given as the input if the size of an image is 2242243, i.e., 224 pixels on 224 pixels with 3 colors as RGB. Then this input will be convolved with the feature to give a feature map.
CNN got its name from the mathematical operation called convolution. It merges two functions to give the third function. ie., Input image ⊗ convolution kernel = Feature map/Convolved feature.
1. Architecture:
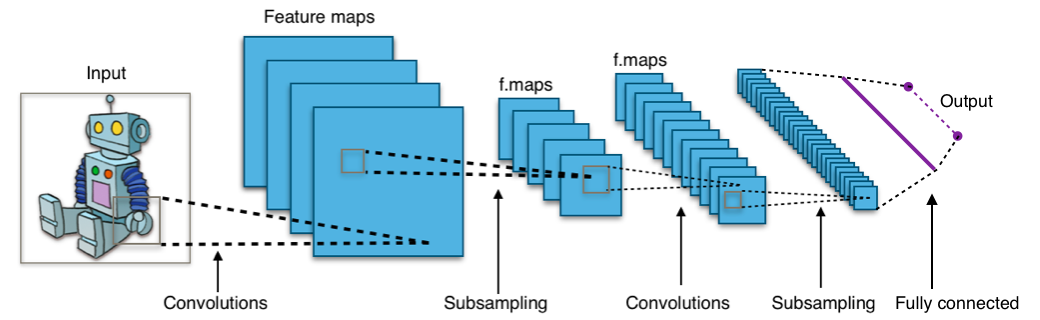
Basically, the convolution neural network has an input layer, a hidden layer, and the output layer. The above-said convolution will happen in the middle layer and produces the convolved feature. The images will have three dimensions: width, height, and depth.
CNN has three layers: the convolutional layer, the pooling layer, and the fully connected layer.
We also have two other layers which are used to build CNN: the ReLU layer and the loss layer.
1.1 Convolutional layer:
The convolution layer is the core building block of CNN. The above-said convolution will happen in this layer and produces the convolved feature.
First, let us see what a kernel is. The kernel is a small matrix that is used to extract the features from the images. The kernel slides along the input and the dot product of the image, and the kernel will produce the convolved feature.
Let us take an example. Let the input size be 5*5, and the kernel size be 3*3, as given below.

1.2. Pooling layer
The pooling layers are used to reduce the number of parameters when the images are too large. It is also called sub sampling/down sampling, where it reduces the dimensionality of each map but retains important information.
The main purpose of pooling is to reduce overfitting. This also helps us to reduce computation.
There are different types of pooling, such as max pooling, average pooling, and sum pooling.

The above figure shows an example of all the different types of pooling. These examples are done with the stride value of 2.
Max pooling: Max pooling returns the max element in each window of a feature map. Max pooling is better than average pooling as it gives the highest feature in each window. It also acts as a noise suppressant.
Average pooling: Average pooling returns the average of elements in each window of a feature map.
Sum pooling: Sum pooling returns the sum of elements in each window of a feature map.
1.3 ReLU layer:
ReLU is also known as Rectified Linear Unit. This activation function is used to increase the nonlinearity in the output. f(x) = max (0, x) where x is the input value. Here the function returns all negative values to zero, and the positive values remain the same.

1.4 Fully connected layer:
The few final layers are called the fully connected layers. The flattening will happen in the final convolutional layer, and it forms the fully connected layer.

The above shows the process of flattening. After the formation of fully connected layers, classification happens. Then we have probabilities of the image that belongs to different classes.
1.5. Loss layer:
The loss functions are used in the output layer to calculate the deviation between the output that is predicted and the actual output. Depending upon the usage, we use different loss functions.
Softmax Loss Function/Cross-Entropy: It is used for measuring the model performance. It generates independent probability values within the probability distribution of [0,1].
Euclidean Loss: It is used in regression problems to real-valued labels (-∞, ∞)
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses

2. Hyperparameters in each Layer:
Kernel size: The dimension of the kernel is the size of the kernel. ie., 2×2, 3×3
Padding: Padding is adding the null-valued pixels on the borders of the image. This is to maintain the size of the image during convolution.
Stride: Stride is the number of moving steps in convolution. When the stride is 1, we move 1 pixel at a time. When the stride is 2, we move two pixels at a time and when the stride is n, we move n pixels at a time.
3. What can be Achieved by Convolution:
Convolution is used to achieve blurring, sharpening, edge detection, and also line detection.
The blurring of an image can be achieved by the mean filter. The properties of the mean filter are:
- The number should be an odd number.
- The sum of the elements of the filter should be 1. (If the sum of the elements is not exactly 1, then the resultant image will be brighter or darker)
- All the elements in the kernel should be the same number.

The above kernels can be used for blurring the image. If the above given 3*3 matrix is used, the image will be blurred and If the above given 4*4 matrix is used, the image will be more blurred.
If the matrix is n*n, if the n increases in the above kernel, then blurriness also increases.
Edge detection can also be done using convolution.

The above image can be used to detect the lines that are horizontal & vertical lines respectively.
Laplacian Gaussian Operator:
The Laplacian Gaussian is used to detect inward edges and outward edges in an image. The Laplacian alone has the advantage of being extremely sensitive to noise. So, smoothening the image before a Laplacian improves the results.

The above image shows the positive and negative Laplacian operators. The Positive Laplacian operator is used to obtain outward edges in an image. Similarly, the Negative Laplacian operator is used to obtain inward edges in an image.
4. Regularization to CNN:
Regularization happens to prevent overfitting. This happens when the model performs well on the training set but not on the testing set.
Dropout: At every iteration, it randomly selects some nodes and removes them along with their incoming and outgoing nodes. The probability of choosing how many nodes should be dropped is the hyperparameter of the dropout functions.
Data augmentation: One of the simplest ways to reduce overfitting is to increase the size of the training set. Some of the common data augmentation techniques are:
1. Position Augmentation:
- Scaling
- Cropping
- Flipping
- Padding
- Rotation
- Translation
2. Color Augmentation
- Brightness
- Contrast
- Saturation
5. Size of convolution image:
Let the size of an image be W*W, the size of the filter be F*F, the padding be P and let stride be S. Then the formula to find the size of the convolution image is (W-F+2P)/S+1
Let us take an example. Let the size of an image be 28*28,
the size of the filter be 5*5,
and let the padding be 0
and stride is 1.
The resulting size of the convolution will be (28-5+2(0)/1+1 = 24*24.
6. Applications:
CNN is used in many real-life applications, such as:
Image classification: The image classification application of CNN is widely used in many healthcare sectors for classifying, detecting, and segmenting CT scans and MRI scans.
Object detection: Object detection applications are such as facial recognition by identifying unique features. This application is used in image captioning, surveillance systems, biometric systems, and autonomous cars too.
Analyzing documents: CNN can also be used for document analysis. It is also used in recognizing handwritten characters.
Audio/Speech recognition: CNN can not only work with the image but also has shown promise for audio classification. Even Facebook speech recognition technology is developed using CNN.
7. Conclusion:
The Convolutional neural network is the type of neural network in deep learning which is widely used to process and make use of images and also real-time images. It has achieved great steps in various domains. We also have different types of CNN architectures, such as LeNet, AlexNet, VGGNet, ResNet, and so on. Researchers and developers are continuously exploring CNN to use it in many domains.
Also explore: Neural networks in deep learning
Contributed By: Snega
Top Trending Article
Top Online Python Compiler | How to Check if a Python String is Palindrome | Feature Selection Technique | Conditional Statement in Python | How to Find Armstrong Number in Python | Data Types in Python | How to Find Second Occurrence of Sub-String in Python String | For Loop in Python |Prime Number | Inheritance in Python | Validating Password using Python Regex | Python List |Market Basket Analysis in Python | Python Dictionary | Python While Loop | Python Split Function | Rock Paper Scissor Game in Python | Python String | How to Generate Random Number in Python | Python Program to Check Leap Year | Slicing in Python
Interview Questions
Data Science Interview Questions | Machine Learning Interview Questions | Statistics Interview Question | Coding Interview Questions | SQL Interview Questions | SQL Query Interview Questions | Data Engineering Interview Questions | Data Structure Interview Questions | Database Interview Questions | Data Modeling Interview Questions | Deep Learning Interview Questions |
FAQs
What is convolution in CNN?
Convolution is a mathematical operation that is used to merge two function to produce the third function.
What are the layers of CNN?
The three layers of CNN are convolutional layer, pooling layer and fully connected layer.
What is flattening layer?
Flattening in CNN converts 2-dimensional array to single linear vector to classify images based on their probabilities.
Can CNN detect objects without images?
No, CNN works extensively on images.
What is the common kernel size in CNN?
The common kernel size in CNN is 3*3 or 5*5

This is a collection of insightful articles from domain experts in the fields of Cloud Computing, DevOps, AWS, Data Science, Machine Learning, AI, and Natural Language Processing. The range of topics caters to upski... Read Full Bio