
Adam Optimizer for Stochastic Gradient Descent
In this blog, We will look at the working of the optimization methods in Neural Networks. Adam Optimizer is one of the advanced optimizers. Mathematical reasoning and the majority of the other important aspects of the Adam optimizer will be covered in this article.
You will understand the following after reading this blog:
- What the Adam algorithm is and why you should use it to optimize your models.
- How the Adam algorithm works differs from the related SGD and RMSProp methods.
Table of Contents
- Overview of Deep Learning Optimization Techniques
- What is An Optimizer?
- Drawbacks of Base Optimizers (GD, SGD, and Mini-Batch GD)
- What is Adam Optimizer?
- Implementation of Adam Optimizer
- Advantages of Adam Optimizer
- Limitations of Adam Optimizer
Best-suited Deep Learning and Neural Networks courses for you
Learn Deep Learning and Neural Networks with these high-rated online courses

Overview of Deep Learning Optimization Techniques
Deep learning is a branch of machine learning that is used to perform complex tasks like speech recognition and text classification. A deep learning model includes an activation function, input, output, hidden layers, a loss function, and other components. Any deep learning model uses an algorithm to generalize the data and make predictions on previously unseen data. We require an algorithm that maps input examples to output examples and an optimization algorithm. When mapping inputs to outputs, an optimization algorithm determines the value of the parameters (weights) that minimize the error. These optimization algorithms or optimizers have a significant impact on the deep learning model’smodel’s accuracy. They also have an impact on the model’smodel’s speed training.
Also read: Free Deep Learning Courses from Top e-learning Platforms
What is an Optimizer?

An optimizer is a function or algorithm that modifies the neural network’snetwork’s attributes, such as weights and learning rate. As a result, it helps to reduce overall loss and improve accuracy. Choosing the right weights for the model is difficult because a deep-learning model typically has millions of parameters. It emphasizes the importance of selecting an appropriate optimization algorithm for your application.
Understanding the Optimization algorithms is crucial to diving deep into deep learning.
Before you continue, there are a few terms you should be familiar with.
Epoch: The number of times the algorithm runs through the entire training dataset.
Sample: A sample is one row from a dataset.
Batch: This is the number of samples that will be used to update the model parameters.
Learning Rate: The learning rate is a parameter that tells the model how frequently the model weights should be updated.
Cost Function/Loss Function: It is used to calculate the cost, which is the difference between the predicted and actual value.
Weights/Bias: A model’smodel’s learnable parameters that control the signal between two neurons.
Momentum: A very popular technique that is used along with SGD. Instead of relying solely on the Gradient of the current step to guide the search, momentum considers the gradients of previous steps to determine the best output.
Drawbacks of Base Optimizers (GD, SGD, and Mini-Batch GD)
Gradient Descent updates weight and bias using the entire training data set. If we have millions of records, training will be slow and computationally expensive.
Stochastic Gradient Decent (SGD) solved the Gradient Descent problem by updating parameters using only single records. However, SGD is slow to converge because each record requires forward and backward propagation. And the path to global minima becomes extremely noisy.
Mini-Batch GD overcomes the SDG drawbacks by updating the parameter with a batch of records. The path to global minima is not as smooth as Gradient Descent because it uses only some records to update parameters.
What is Adam Optimizer?
Adam derives its name from adaptive moment estimation. This optimization algorithm is a stochastic gradient descent extension that updates network weights during training. It is a hybrid of the “gradient descent with momentum” and the “RMSP” algorithms.
It is an adaptive learning rate method that calculates individual learning rates for various parameters.
Adam can be used instead of the classical stochastic gradient descent procedure to update network weights iterative based on training data.
The Adam optimizer employs a hybrid of two gradient descent methods:
Momentum: This algorithm is used to speed up the gradient descent algorithm by considering the ”exponentially weighted average” of the gradients. Using averages causes the algorithm to converge to the minima more quickly.

- mt = Aggregate of gradients at time t [Current] (Initially, mt = 0)
- mt-1 = Aggregate of gradients at time t-1 [Previous]
- Wt = Weights at time t
- Wt+1 = Weights at time t+1
- αt = Learning rate at time t
- ∂L = Derivative of Loss Function
- ∂Wt = Derivative of weights at time t
- β = Moving average parameter (Constant, 0.9)
Root Mean Square Propagation (RMSP):
RMSprop, or root mean square prop, is an adaptive learning algorithm that attempts to improve AdaGrad. It uses the ”exponential moving average” rather than the cumulative Sum of squared gradients as AdaGrad does.

- Wt = Weights at time t
- Wt+1 = Weights at time t+1
- αt = Learning rate at time t
- ∂L = Derivative of Loss Function
- ∂Wt = Derivative of weights at time t
- Vt = Sum of the square of past gradients. [i.e sum(∂L/∂Wt-1)] (initially, Vt = 0)
- β = Moving average parameter (const, 0.9)
- ϵ = A small positive constant (10-8)
Adam Optimizer takes the strengths or positive characteristics of the previous two methods and builds on them to provide a more optimized gradient descent.
In this case, we control the gradient descent rate so that there is minimal oscillation when it reaches the global minimum while taking large enough steps (step size) to avoid the local minima hurdles along the way—as a result, combining the features of the above methods to reach the global minimum efficiently.
Mathematical Aspect of Adam Optimizer:
Using the formulas used in the previous two methods, we get the following:
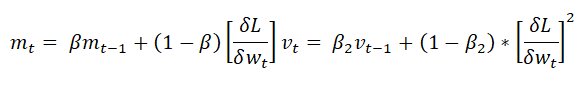
Implementation of Adam Optimizer
Now it it’s time to put it into practice and compare the results using different optimizers on a simple neural network. Let’sLet’s use the MNIST dataset, and We will train a simple model with some basic layers, using the same batch size and epochs but different optimizers. We will use the default values with each optimizer.
Importing the Libraries:
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2D
from keras import backend as K
(x_train, y_train), (x_test, y_test) = mnist.load_data()
print(x_train.shape, y_train.shape)
Loading The Dataset:
x_train= x_train.reshape(x_train.shape[0],28,28,1)
x_test= x_test.reshape(x_test.shape[0],28,28,1)
input_shape=(28,28,1)
y_train=keras.utils.to_categorical(y_train)#,num_classes=)
y_test=keras.utils.to_categorical(y_test)#, num_classes)
x_train= x_train.astype('float32')
x_test= x_test.astype('float32')
x_train /= 255
x_test /=255
Building The Model:
batch_size=64
num_classes=10
epochs=10
def build_model(optimizer):
model=Sequential()
model.add(Conv2D(32,kernel_size=(3,3),activation='relu',
input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy
, optimizer= optimizer, metrics=['accuracy'])
return model
Training The Model:
optimizers = ['Adadelta', 'Adagrad', 'Adam', 'RMSprop', 'SGD']
for i in optimizers:
model = build_model(i)
hist=model.fit(x_train, y_train,
batch_size=batch_size, epochs=epochs, verbose=1,
validation_data=(x_test,y_test))
Insights:
We have run our model with a batch size of 64 for ten epochs. After trying the different optimizers, the results we get are interesting. Before analyzing the results, what will be the best optimizer for this dataset?
| Optimizer | Epoch 10 Val accuracy | Val loss | Total Time |
| Adam | 0.9893 | 0.0351 | 625 sec |
| RMSprop | 0.9887 | 0.0348 | 609 sec |
| SGD | 0.9679| 0.1050 | 528 sec |
The table above displays the validation accuracy and loss at various epochs. It also includes the total time the model took to run on ten epochs for each optimizer. We can draw the following conclusions from the above table.
- The Adam optimizer achieves the highest accuracy in a reasonable amount of time.
- RMSprop achieves similar accuracy to Adam but with a much longer computation time.
- Surprisingly, the SGD algorithm required the least training time and produced the best results. However, to achieve the Adam optimizer’s accuracy, SGD will need more iterations, increasing the computation time.
- SGD with momentum performs similarly to SGD with an unexpectedly longer computation time. This implies that the value of momentum taken must be optimized.
Advantages of Adam Optimizer
- Simple to put into action
- Effective in terms of computation
- Memory requirements are minimal.
- Appropriate for gradients that are very noisy or sparse.
- Ideal for problems with a large amount of data or parameters.
- Appropriate for non-stationary goals.
- Appropriate for gradients that are very noisy or sparse.
- Hyper-parameters have an intuitive interpretation and usually require some tuning.
Limitations of Adam Optimizer

Source: Adam Official Paper
Building on the strengths of previous models, the Adam optimizer provides significantly better performance than previous models. It outperforms them by a wide margin in terms of providing an optimized gradient descent. The plot below clearly shows how Adam Optimizer outperforms the rest of the optimizers in training cost (low) and performance by a significant margin (high).
Conclusion
This article demonstrated how an optimization algorithm could improve a deep learning model’s accuracy, speed, and efficiency. We learned about the Adam algorithm by comparing it with other optimization algorithms. We learned how Using the Adam optimizer for your application may give you the best chance of achieving the best results. We also discovered that the Adam optimizer has some drawbacks.
Contributed by Nagarjun Kalyankari

This is a collection of insightful articles from domain experts in the fields of Cloud Computing, DevOps, AWS, Data Science, Machine Learning, AI, and Natural Language Processing. The range of topics caters to upski... Read Full Bio