
Cross Entropy Loss Function in Machine Learning
Cross entropy loss function is a mathematical tool used in machine learning to measure the difference between predicted and actual probability distributions.

In the field of machine learning, the ability to accurately predict outcomes is crucial. One important aspect of machine learning is loss functions, which measure the difference between the predicted output and the true output. Cross Entropy Loss Function is one such loss function that is widely present in machine learning. It has gained popularity due to its ability to handle complex datasets and improve model accuracy.
Check machine learning courses now!
Theoretical Background
To understand the Cross Entropy Loss Function, we need to first understand the concepts of entropy and cross entropy. Entropy is a measure of uncertainty or randomness in a system. In machine learning, entropy measures the amount of information required to describe the output of a system. The formula for entropy is:
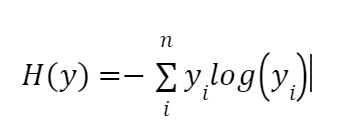
Here, yi represents the probability of the i-th output class.
Cross entropy is a similar concept that is used to compare the output of a machine learning model with the actual output. The formula for cross entropy is:

Here, yi represents the true output and yi represents the predicted output. Cross entropy measures the difference between the predicted and true output. The goal of machine learning is to minimize this difference.
The Cross Entropy Loss Function is derived from cross entropy. It is a common loss function in machine learning, especially in classification tasks. It calculates the difference between the predicted and true output. Its formula is:

Here, N is the number of samples, C is the number of classes,yij is the true output for the i-th sample and j-th class, and yij is the predicted output for the i-th sample and j-th class.
 Read Later
Read Later
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses

Types of Cross Entropy Loss Function
There are four main types.
Binary Cross Entropy Loss Function: This is used when there are only two classes in the dataset. It is commonly used in binary classification problems. The formula for Binary Cross Entropy Loss Function is:

Here, yi is the true output for the i-th sample and yi is the predicted output for the i-th sample.
Categorical Cross Entropy Loss Function: This is used when there are more than two classes in the dataset. It is commonly used in multi-class classification problems. The formula is:

Here, C is the number of classes, yij is the true output for the i-th sample and j-th class, and yij is the predicted output for the i-th sample and j-th class.
Sparse Categorical Cross Entropy Loss Function: Sparse Categorical Cross Entropy Loss Function is similar to Categorical Cross Entropy Loss Function. However, it is used when the true output is a single integer representing the class label. It is commonly used in problems where the number of classes is large. The formula for Sparse Categorical Cross Entropy Loss Function is:

Here, ji is the true class label for the i-th sample and yi,ji is the predicted output for the i-th sample and true class label.
Softmax Cross Entropy Loss Function: Softmax Cross Entropy Loss Function is similar to Categorical one. It is commonly used when there are more than two classes in the dataset. The formula is:

Here, C is the number of classes, yij is the true output for the i-th sample and j-th class, and yij is the predicted output for the i-th sample and j-th class.
Binary Cross Entropy Loss Function
You use Binary Cross Entropy Loss Function when only two classes are in the dataset. It has its common use in binary classification problems, where the goal is to classify data into one of two categories, such as spam or not spam, or positive or negative.
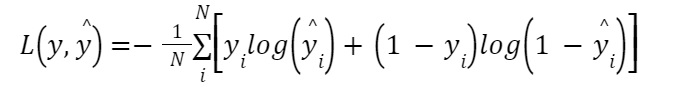
Here, $y_i$ is the true output for the i-th sample, which can be either 0 or 1, and $hat{y_i}$ is the predicted output for the i-th sample, which is a probability value between 0 and 1.
The Binary Cross Entropy Loss Function works by calculating the difference between the true output and the predicted output for each sample in the dataset, and then taking the average of these differences. The logarithmic function is used to calculate the difference, which penalises the model more for incorrect predictions that are further from the true output.
The loss value will be low when the predicted output is close to the true output. However, the loss value will be high when the predicted output is far from the true output. The goal of training a machine learning model is to minimize the loss value, which can be achieved by adjusting the model’s parameters through backpropagation.
Here’s an example Python code that calculates the Binary Cross Entropy Loss for a set of true and predicted values:
import numpy as np
# true values for binary classification samplestrue_values = [0, 1, 1, 0, 0, 1, 1]
# predicted values for binary classification samplespredicted_values = [0.07, 0.91, 0.74, 0.23, 0.85, 0.17, 0.94]
def binary_cross_entropy(true_values, predicted_values): true_values = np.float_(true_values) predicted_values = np.float_(predicted_values) # binary cross-entropy loss return -np.sum(true_values * np.log(predicted_values) + (1 - true_values) * np.log(1 - predicted_values))
# calculate the Binary Cross Entropy Loss for the given valuesbinary_cross_entropy_loss = binary_cross_entropy(true_values, predicted_values)
print("Binary Cross Entropy Loss:", binary_cross_entropy_loss)
In the example, we have provided two arrays true_values and predicted_values with seven values each, representing the true and predicted values for seven binary classification samples. We then call the binary_cross_entropy() function with these values to calculate the Binary Cross Entropy Loss, which is 4.460303459760249.
Categorical Cross Entropy Loss Function
It is for multi-class classification problems where the output of the model is a probability distribution over multiple classes. In this case, the target variable can take on multiple categories, and the predicted values are a set of probabilities that represent the likelihood of the input belonging to each category. The formula for Categorical Cross Entropy Loss is

Here, C is the number of classes, yij is the true output for the i-th sample and j-th class, and yij is the predicted output for the i-th sample and j-th class.
Let’s take an example to understand how to calculate the Categorical Cross Entropy Loss. Suppose we have three samples with four classes, and the true labels and predicted probabilities for each sample are given as follows:
import numpy as np
# true labels for multi-class classification samplestrue_labels = np.array([[1, 0, 0, 0], [0, 0, 1, 0], [0, 1, 0, 0]])
# predicted probabilities for multi-class classification samplespredicted_probs = np.array([[0.5, 0.3, 0.1, 0.1], [0.2, 0.1, 0.6, 0.1], [0.1, 0.8, 0.05, 0.05]])
def categorical_cross_entropy(true_labels, predicted_probs): true_labels = np.float_(true_labels) predicted_probs = np.float_(predicted_probs) # categorical cross-entropy loss return -np.sum(true_labels * np.log(predicted_probs), axis=1)
# calculate the Categorical Cross Entropy Loss for the given valuescategorical_cross_entropy_loss = categorical_cross_entropy(true_labels, predicted_probs)
print("Categorical Cross Entropy Loss:", categorical_cross_entropy_loss)
In this code, we have defined a function categorical_cross_entropy that takes in the true labels and predicted probabilities as inputs and returns the Categorical Cross Entropy Loss. We have used the numpy library to perform the calculations efficiently. The axis=1 argument in the np.sum function indicates that we want to sum the values along the rows, as we have multiple samples. The output of the code is the Categorical Cross Entropy Loss for each sample.
Sparse Categorical Cross Entropy Loss Function
It is for multi-class classification problems where the true labels are integers representing the class indices rather than one-hot encoded vectors. This is useful when we have a large number of classes and it is impractical to represent each class as a one-hot encoded vector. In this case, the target variable can take on multiple categories, and the predicted values are a set of probabilities that represent the likelihood of the input belonging to each category.
The formula for Sparse Categorical Cross Entropy Loss is

Here, ji is the true class label for the i-th sample and yi,ji is the predicted output for the i-th sample and true class label.
Let’s take an example to understand how to calculate the Sparse Categorical Cross Entropy Loss. Suppose we have three samples with four classes, and the true labels and predicted probabilities for each sample are given as follows:
import numpy as np
# true labels for multi-class classification samplestrue_labels = np.array([0, 2, 1])
# predicted probabilities for multi-class classification samplespredicted_probs = np.array([[0.5, 0.3, 0.1, 0.1], [0.2, 0.1, 0.6, 0.1], [0.1, 0.8, 0.05, 0.05]])
def sparse_categorical_cross_entropy(true_labels, predicted_probs): # sparse categorical cross-entropy loss return -np.sum(np.log(predicted_probs[np.arange(len(predicted_probs)), true_labels]))
# calculate the Sparse Categorical Cross Entropy Loss for the given valuessparse_categorical_cross_entropy_loss = sparse_categorical_cross_entropy(true_labels, predicted_probs)
print("Sparse Categorical Cross Entropy Loss:", sparse_categorical_cross_entropy_loss)
In this code, we have defined a function sparse_categorical_cross_entropy that takes in the true labels and predicted probabilities as inputs and returns the Sparse Categorical Cross Entropy Loss. We have used the numpy library to perform the calculations efficiently.
The np.arange(len(predicted_probs)) creates an array of indices corresponding to each sample, and the true_labels array contains the integer class labels. We then use advanced indexing to select the corresponding predicted probabilities for each sample and calculate the loss using the formula. The output of the code is the Sparse Categorical Cross Entropy Loss for the given values.
Softmax Cross Entropy Loss Function
For multi-class classification problems, the true labels are one-hot encoded vectors representing the class indices. The Softmax function converts the output of the last layer of the neural network into a probability distribution, and the Cross Entropy Loss compares the predicted probabilities with the true labels. The formula for Softmax Cross Entropy Loss is:

Here, C is the number of classes, yij is the true output for the i-th sample and j-th class, and yij is the predicted output for the i-th sample and j-th class.
Suppose we have three samples with four classes, and the true labels and predicted probabilities for each sample are given as follows:
import numpy as np
# true labels for multi-class classification samplestrue_labels = np.array([[1, 0, 0, 0], [0, 0, 1, 0], [0, 1, 0, 0]])
# predicted probabilities for multi-class classification samplespredicted_probs = np.array([[0.5, 0.3, 0.1, 0.1], [0.2, 0.1, 0.6, 0.1], [0.1, 0.8, 0.05, 0.05]])
def softmax_cross_entropy(true_labels, predicted_probs): # softmax cross-entropy loss return -np.sum(true_labels * np.log(predicted_probs / np.sum(predicted_probs, axis=1, keepdims=True)))
# calculate the Softmax Cross Entropy Loss for the given valuessoftmax_cross_entropy_loss = softmax_cross_entropy(true_labels, predicted_probs)
print("Softmax Cross Entropy Loss:", softmax_cross_entropy_loss)
In this code, we have defined a function softmax_cross_entropy that takes in the true labels. Also, the predicted probabilities as inputs and returns the Softmax Cross Entropy Loss. We have used the numpy library to perform the calculations efficiently. The true_labels array contains the one-hot encoded vectors for the true labels. And the predicted_probs array contains the predicted probabilities for each sample. We then use the formula to calculate the loss, where we multiply the true labels with the logarithm of predicted probabilities element-wise and sum over all the classes. The output of the code is the Softmax Cross Entropy Loss for the given values.
Examples and Applications
It is a fundamental concept in machine learning, and it has various applications across different domains. One of the significant applications of this function is in classification problems, where the goal is to classify the input into one of the predefined categories. In such problems, this function calculates the error between the predicted and actual outputs, and the gradient of the loss function updates the model parameters during training.
It is for binary, multi-class, and other classification tasks. Additionally, it is for neural networks, reinforcement learning, generative models, object detection, and natural language processing. It has revolutionized machine learning and enabled the development of various advanced techniques and algorithms.
Hence, it has several examples and applications in machine learning.
- Binary Classification: In binary classification, the binary cross-entropy loss function calculates the error between the predicted and actual binary values. It is for spam filtering, sentiment analysis, and other classification tasks.
- Multi-class Classification: The categorical cross-entropy loss function calculates the error between the predicted and actual probability distributions. It is for image classification, natural language processing, and other classification tasks.
- Neural Networks: Cross entropy loss function can train neural networks. In backpropagation, it calculates the error in the output layer, and the gradient updates the weights.
- Reinforcement Learning: It is for reinforcement learning to calculate the loss function in policy gradients. The policy gradients update the policy parameters to improve the agent’s performance.
- Generative Models: It is for generative models like GANs and VAEs. This is to calculate the error between the generated and actual images or text.
- Object Detection: In object detection, cross-entropy loss measures the similarity between predicted and actual object bounding boxes.
- Natural Language Processing: In natural language processing, cross-entropy loss calculates the error between the predicted and actual language models.
Conclusion
Cross-entropy loss function is an essential concept in machine learning. It helps in measuring the performance of a model during training. It is common in different applications such as classification, reinforcement learning, generative models, and natural language processing. It is a flexible and versatile concept with different types. Each of these types has its specific use cases and formulas. It has enabled the development of various advanced techniques and algorithms, improving the accuracy and efficiency of machine-learning models.
Therefore, understanding this function is crucial for anyone working in the field of machine learning. And it is essential to apply the right type based on the specific problem and data being worked on.
Contributed by Somya Dipayan

This is a collection of insightful articles from domain experts in the fields of Cloud Computing, DevOps, AWS, Data Science, Machine Learning, AI, and Natural Language Processing. The range of topics caters to upski... Read Full Bio