
Differences Between Supervised and Unsupervised Learning
While taking a deep dive into AI (Artificial Intelligence) and ML (Machine Learning), you will come across two main ways machines learn from the data fed into them – Supervised and Unsupervised. What is the fundamental difference between the two types, you ask? This article will help you understand everything you need to know about them and which learning type fits the nature of the machine learning problem. Based on this, you can choose a suitable learning algorithm.

The below article goes through Supervised vs Unsupervised Machine Learning. It aims to explain Supervised and Unsupervised Machine Learning along with differences between them.

We will be covering the following sections:
- What is Supervised Learning?
- Supervised Learning Techniques
- Supervised Learning Algorithms
- Demo: Supervised Learning
- What is Unsupervised Learning?
- Unsupervised Learning Algorithms
- Demo: Unsupervised Learning
- Difference between Supervised vs. Unsupervised Learning
- Endnotes
What is Supervised Learning?
In supervised learning, we have prior knowledge of how the predicted output values should be. Supervised learning algorithms use the features of a dataset to learn the relationship between a given input and the observable output. This is known as training the model. We aim to use the algorithm to predict the output labels when new data is fed into the model.
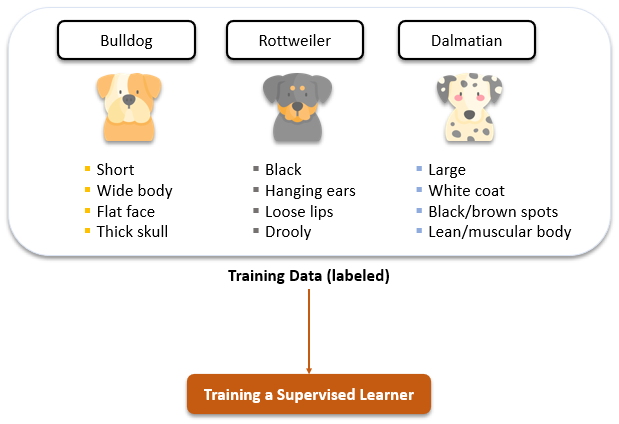
In the above example, we are using labeled data (aka training dataset) to train our supervised learner.

Once our learner is trained and ready, we will apply the algorithm to predict the label of the new (testing) data as accurately as possible.
The performance of the algorithm is determined by its accuracy in the prediction of the new data. Accuracy refers to how often the algorithm’s predictions are correct.
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses

Supervised Learning Techniques
Classification
It’s a supervised learning technique that predicts a discrete class label output to which the data element belongs.

Classification techniques can be applied to a wide range of problems, such as:
- Spam e-mails/texts detection
- Waste segregation
- Disease detection
- Image classification
- Speech recognition
Regression
It is a supervised learning technique that predicts a continuous outcome variable based on the independent variable(s).
Regression techniques can be applied to problems such as:
- Fuel price prediction
- Stock price prediction
- Sales revenue prediction
Supervised Learning Algorithms
Examples of supervised learning algorithms include:
- Linear Regression (Regression)
- Logistic Regression (Classification)
- K-Nearest Neighbours (Classification)
- Support Vector Machines (Classification)
- Naïve Bayes (Classification)
- Decision Tree (Classification/Regression)
- Random Forest (Classification/Regression)
Demo: Building a Supervised Learning Model – Naïve Bayes Classifier
Let’s build a Gaussian Naïve Bayes Classifier model using the scikit-learn library in Python. We will use the wine dataset already present in the library.
Step 1 – Load the data and get its shape (number of rows and columns)
from sklearn import datasets
# Load the wine datasetwine = datasets.load_wine()
# Get the shape of the datasetprint(wine.data.shape)

So, there are 13 features and 178 records in the data.
Step 2 – Print the feature and the target variables
from sklearn import datasets
# Load the wine datasetwine = datasets.load_wine()
# Print the features of the dataprint("Features:", wine.feature_names)
# Print the label types of wine (class_0, class_1, class_2)print("Labels:", wine.target_names)

Let’s check out the values of our target column:
from sklearn import datasets
# Load the wine datasetwine = datasets.load_wine()
# Print the target (labels) of the wine datasetprint(wine.target)
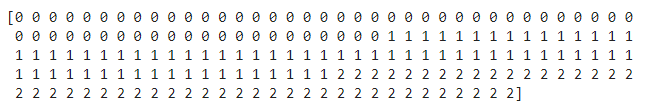
Step 3 – Split the data into training and testing sets
from sklearn import datasetsfrom sklearn.model_selection import train_test_split
# Load the wine datasetwine = datasets.load_wine()
# Split the dataset into 70% training and 30% testingX_train, X_test, y_train, y_test = train_test_split(wine.data, wine.target, test_size=0.3, random_state=109)
# Optionally, print the shapes of the splits to verifyprint("X_train shape:", X_train.shape)print("X_test shape:", X_test.shape)print("y_train shape:", y_train.shape)print("y_test shape:", y_test.shape)
Step 4.1 – Create a Gaussian Naïve Bayes Classifier
from sklearn import datasetsfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNBfrom sklearn.metrics import accuracy_score
# Assuming you've already loaded the wine dataset and split it into training and testing sets
# Create a Gaussian Classifiergnb = GaussianNB()
# Train the model using the training setsgn
Step 4.2 – Train the GaussianNB Classifier
# Train the model using the training setsgnb.fit(X_train, y_train)
# Now, you can use the trained model to make predictions on the test sety_pred = gnb.predict(X_test)
# Optionally, print the first few predictionsprint("First few predictions:", y_pred[:5])
Step 4.3 – Predict the outcome
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# Predict the response for the testing sety_pred = gnb.predict(X_test)
# Evaluate the modelaccuracy = accuracy_score(y_test, y_pred)conf_matrix = confusion_matrix(y_test, y_pred)class_report = classification_report(y_test, y_pred)
# Print the evaluation resultsprint("Accuracy:", accuracy)print("Confusion Matrix:\n", conf_matrix)print("Classification Report:\n", class_report)
Step 5 – Get the accuracy of the GaussianNB Classifier
from sklearn import metrics #Model Accuracyprint ( "Accuracy:" ,metrics. accuracy_score (y_test , y_pred ) )
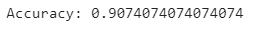
Hence, our classifier predicts accurate outcomes over 90% of the time. This is great!
Must Read – How to Become a Machine Learning Engineer
What is Unsupervised Learning?
In unsupervised learning, we work with data that isn’t explicitly labelled. It is suitable for ML problems requiring an algorithm to identify some underlying structure in the data. Unlike supervised learning, we do not need to train the machine and can directly apply the algorithm to the data.
Unsupervised learning is commonly used during text mining and dimensionality reduction. A very common unsupervised learning method is Clustering, which identifies similar inputs and categorizes them into clusters.

In the example above, the fruits are clustered together without using any labels to train the machine. Clustering, in this case, is done based on similar physical characteristics (colour). The output is dynamic to the input values, i.e., it will change with a change in input.
Unsupervised learning can be applied to a wide range of problems, such as:
- Fraud detection
- Movie recommendation
- Product promotion
Unsupervised Learning Algorithms
Examples of unsupervised learning algorithms include:
- Clustering
- K-means clustering
- KNN (k-nearest neighbours)
- Hierarchal clustering
- Association
- Apriori algorithm
- Dimensionality Reduction
- Principle Component Analysis (PCA)
- Linear Discriminant Analysis (LDA)
- Neural Networks
Types of Unsupervised Learning
Clustering
It involves grouping the unlabeled data based on their similarities or differences, such as shape, size, colour, price, etc. Clustering algorithms are helpful for market segmentation, image compression, etc. Different types of clustering algorithms are –
- K-Means Clustering
- Mean-Shift Clustering
- Hierarchical Clustering
- Expectation–Maximization (EM) Clustering using Gaussian Mixture Models (GMM)
Association Rule Mining
Association Rule Mining spots repeating items or finds associations between elements. A good example is Amazon, which offers recommendations based on your shopping behaviour. Look for “ Customers Who Bought This Item Also Bought” or “Products related to this item.”

Association Rule Mining algorithms are –
- Apriori algorithms
- Eclat
- F-P Growth algorithms
Dimensionality Reduction
Dimensionality reduction involves transforming data from a high-dimensional space into a low-dimensional space. It is used when the given data set has a very high number of features, and data integrity may be compromised. Some popular dimensionality reduction methods are –
- Principal Components Analysis
- Singular Value Decomposition
- Non-Negative Matrix Factorization
- Locally Linear Embedding
- Multidimensional Scaling
- Spectral Embedding
Demo: Unsupervised Learning – Implementing PCA
Principal Component Analysis (PCA) is used to speed up the fitting of an ML algorithm. If your learning model is too slow because of high input dimensions, we perform dimensionality reduction using PCA.
Let’s see how we implement PCA in Python. We are going to make use of the iris dataset for this.
Step 1 – Load the data
import pandas as pd
# Loading the dataset from 'Iris.csv'data = pd.read_csv('Iris.csv')
# Displaying the first few rows of the datasetprint(data.head())
Output:

Step 2 – Standardize the data
We need to scale the features in your data before applying PCA. We use StandardScaler to standardize the dataset features onto a unit scale (mean = 0 and variance = 1). This ensures the optimal performance of many ML algorithms.
from sklearn.preprocessing import StandardScalerimport pandas as pdfrom sklearn.datasets import load_iris
# Loading the Iris datasetiris = load_iris()data = pd.DataFrame(data=iris.data, columns=iris.feature_names)data['Species'] = iris.targetdata['Species'] = data['Species'].apply(lambda x: iris.target_names[x])
features = ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
# Separating the featuresx = data.loc[:, features].values
# Separating the target variabley = data.loc[:, ['Species']].values
# Standardizing the featuresx = StandardScaler().fit_transform(x)
# Display the first 5 rows of the standardized features to verifyprint(x[:5])
Step 3 – Project PCA to 2D
The original dataset has 4 features: sepal length, sepal width, petal length, and petal width. Now, we will project our data into 2 dimensions – PC1 and PC2. These new components are the two main dimensions of variation.
from sklearn.decomposition import PCAimport pandas as pd
# Assuming x is your standardized features from the previous step# Initialize PCA and specify the number of componentspca = PCA(n_components=2)
# Fit PCA on the standardized features and transformcomponents = pca.fit_transform(x)
# Create a DataFrame with the PCA resultsdf = pd.DataFrame(data=components, columns=['PC1', 'PC2'])
# Display the first few rows to see the transformed dataprint(df.head())
Output:

Step 4 – Concatenate the DataFrame along with columns
Now, we will concatenate the DataFrame along axis = 1.
import pandas as pd
# Assuming 'df' contains the PCA components and 'data' contains the original Iris dataset with a 'Species' columnfinal_df = pd.concat([df, data[['Species']]], axis=1)
# Display the first few rows of the concatenated DataFrameprint(final_df.head())
Output:

So, we have performed dimensionality reduction on our data.
Step 5 – Visualize the 2D Projection
import matplotlib.pyplot as pltimport pandas as pd
# Sample data creation for demonstration, replace this with your actual final_df DataFrame# Assuming final_df structure with PCA results and speciesdata = { 'PC1': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15], 'PC2': [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16], 'Species': ['Iris-setosa'] * 5 + ['Iris-versicolor'] * 5 + ['Iris-virginica'] * 5}final_df = pd.DataFrame(data)
# Plottingfig = plt.figure(figsize=(8, 8))ax = fig.add_subplot(1, 1, 1)ax.set_xlabel('Principal Component 1', fontsize=15)ax.set_ylabel('Principal Component 2', fontsize=15)ax.set_title('2 component PCA', fontsize=20)
targets = ['Iris-setosa', 'Iris-versicolor', 'Iris-virginica']colors = ['red', 'green', 'orange']
for target, color in zip(targets, colors): indicesToKeep = final_df['Species'] == target ax.scatter(final_df.loc[indicesToKeep, 'PC1'], final_df.loc[indicesToKeep, 'PC2'], c=color, s=50)
ax.legend(targets)ax.grid()
plt.show()
Output:

Can you notice on the graph above how the classes seem well-separated?
Difference between Supervised and Unsupervised Learning
Let’s find out the main differences between supervised and unsupervised learning.
Use of Labeled Data Sets
This is the key factor that distinguishes supervised and unsupervised learning. Labeled data means that input data is already tagged with the desired output. To clarify, supervised learning uses labeled data, and unsupervised learning uses unlabeled data.
Applications
Supervised learning has applications in tasks like –
- Spam detection and classification
- User sentiment analysis
- Weather forecasting
- Stock market predictions
- Sales forecasting
- Demand and supply analysis
- Fraud identification
Unsupervised learning has applications in –
- Anomaly detection
- Recommendation engines
- Market segmentation
- Medical imaging
Functions
In supervised learning, algorithms learn functions to predict the output associated with new inputs. On the other hand, unsupervised learning systems focus on finding new patterns in the given unlabeled data.
Challenges
Supervised learning models are simple yet time-consuming to train. Labeling the input and output variables requires a certain level of expertise. Unsupervised learning can produce inaccurate output without human validation of the results.
Now let’s take a quick look at the differences between Supervised and Unsupervised Learning –
| Supervised Learning | Unsupervised Learning |
| The input data is labelled. | The input data is not labeled. |
| The data is classified based on the training dataset. | Assigns properties of the given data to categorize it. |
| Supervised algorithms have a training phase to learn the mapping between input and output. | Unsupervised algorithms have no training phase. |
| Used for prediction problems. | Used for analysis problems. |
| Supervised algorithms include Classification and Regression. | Unsupervised algorithms include Clustering and Association. |
Endnotes
We have discussed how Machine Learning problems can be solved based on two fundamental learning approaches. Supervised algorithms learn from data features and labels, whereas unsupervised algorithms only take the data features without labels. The choice of algorithm depends on the problem and the kind of data we have. Artificial Intelligence and machine Learning are an increasingly growing domain that has hugely impacted big businesses worldwide. Interested in being a part of this frenzy? Explore related articles here.
Top Trending Articles:
Data Analyst Interview Questions | Data Science Interview Questions | Machine Learning Applications | Big Data vs Machine Learning | Data Scientist vs Data Analyst | How to Become a Data Analyst | Data Science vs. Big Data vs. Data Analytics | What is Data Science | What is a Data Scientist | What is Data Analyst

Rashmi is a postgraduate in Biotechnology with a flair for research-oriented work and has an experience of over 13 years in content creation and social media handling. She has a diversified writing portfolio and aim... Read Full Bio