
Bagging Technique in Ensemble Learning
In this article, we will discuss the concept how to solve machine learning problems using the ensemble learning bagging.

Introduction
In this article, we will discuss about Bagging method in ensemble learning.
Imagine you have been planning to buy a car and have not yet decided which one. To help you choose, you need to collect more information. You need to consider your usage, your budget, etc.
You need to search online for reviews and ask your friends for their recommendations and then eventually, you will be able to make a decision based on multiple sources of information.
Similarly, in the world of machine learning, there’s no one-size-fits-all, or rather a one-model-fits-all, when working on a problem. Different models perform well in different scenarios.
So, instead of relying on the outcome of one specific model, you can choose from different models by aggregating their results and obtaining a best-fit model for your problem.
This is where Ensemble Learning comes into the picture.
In this article, we will discuss a common Ensemble Learning technique in detail – Bagging.
To know more about Machine Learning – Click here
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses

Table of Content
- Quick Intro to Ensemble Learning
- What is Bagging in Ensemble Learning – Bootstrap Aggregation
- Demo: Implementing Bootstrapping
Quick Intro to Ensemble Learning
An Ensemble Learning model is an aggregation of multiple models to improve the overall performance and make a final decision.
The ensemble model combines multiple models (aka weak learner) to make a strong learner. These model solves a given ML problem that would not be resolved as efficiently by any of the standalone learners.
The two popular techniques to create an ensemble model are:
The two popular techniques to create an ensemble model are:
- Bagging
- Boosting
Bias and Variance
Before moving ahead, let’s recall an important concept when estimating model performance. A good ML model must have a minimal error – which means it should theoretically have a low bias and low variance while learning the training data. Why is that? Because both these sources of error will prevent a model from generalizing the training data to perform well on any new data.
However, achieving both low bias and low variance at the same time is not quite possible due to what we call the bias-variance trade-off.
- Bias error comes up when an algorithm makes incorrect assumptions about the relationship between the features and target variable in the training data. High bias causes the underfitting of the model.
- Variance error is caused by over-sensitivity to minute fluctuations in the training data. Due to this, the model learns noise from the data. A high variance would result in the overfitting of the model.

To obtain good results, a model must have a low error rate and enough degrees of freedom to resolve the underlying complexity of the data. But as you can see from the graph above, high degrees of freedom would mean high variance, which would affect the robustness of our model.
So, to obtain an optimal model, we need to find a balance between bias and variance.
This is the idea of ensemble methods – reducing the bias and/or variance of weak learner models by different combining techniques that are chosen based on the source of error we are trying to reduce.

 Read Later
Read Later
What is Bagging in Ensemble Learning – Bootstrap Aggregating
Bagging is an ensemble learning method that is used to reduce the error by training homogeneous weak learners on different random samples from the training set, in parallel. The results of these base learners are then combined through voting or averaging approach to produce an ensemble model that is more robust and accurate.
Bagging mainly focuses on obtaining an ensemble model with lower variance than the individual base models composing it. Hence, bagging techniques help avoid the overfitting of the model.
Bootstrapping: Random Sampling with Replacement
Let’s define bootstrapping first – It is a statistical technique that generates random samples (called bootstrap samples) from the initial dataset by randomly drawing with replacement observations.
The samples should have two properties:
- Representativity: The initial dataset should be large enough so that the samples are a good approximation of sampling from the underlying distribution of data.
- Independence: The initial dataset should be large enough compared to the sample size so that the samples are not much correlated.
In general, classification problems require more samples in comparison to regression problems.

As per our assumptions, each bootstrap sample shown above will act as an almost-independent dataset drawn from the true (unknown) underlying distribution.
Ensemble Learning and Aggregating
Now, we fit a weak learner for each of the samples (ensemble learning) and finally combine their outputs to obtain an ensemble model (aggregating) with lower variance.
- For regression problems, predicted outcomes from base models are averaged.
- For classification problems, majority votes are considered.
Demo: Implementing Bagging
Problem Statement:
Let’s build an ensemble model through the bagging technique. For this, we will implement a Decision Tree as the base learner using the Scikit-learn library in Python.
Dataset Description:
This dataset has the following columns:
- alcohol – Alcohol percentage in that particular type of wine
- malic_acid – Malic acid percentage in that particular type of wine
- ash – Amount of ash in that particular type of wine
- alcalinity_of_ash – Amount of alkalinity of ash in that particular type of wine
- magnesium – Amount of magnesium in that particular type of wine
- total_phenols – Amount of phenols in that particular type of wine
- flavanoids – Amount of flavonoids in that particular type of wine
- nonflavanoid_phenols – Amount of non flavonoid phenols in that particular type of wine
- proanthocyanins – Amount of proanthocyanins in that particular type of wine
- color_intensity – The color intensity of that particular type of wine
- hue – The hue of that particular type of wine
- od280/od315_of_diluted_wines – Amount of dilution of that particular type of wine
- proline – Amount of proline in that particular type of wine
- target – Class label of the wine (1,2, or 3)
The target column is used to predict the class of wine.
Tasks to be performed:
- Load the data
- Split the data into training and testing sets
- Build a Decision Tree Classifier
- Build an Ensemble Model using Bagging
- Train the Ensemble Model
- Evaluate the Ensemble model
Load the data
from sklearn.datasets import load_wine #Load the wine dataset x, y = load_wine(return_X_y=True)
Split the data into training and testing sets
from sklearn.model_selection import train_test_split #Split the dataset into 70% training set and 30% testing set x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=23)
Build a Decision Tree Classifier
We are going to use a Decision Tree with fixed parameters as the base learner.
from sklearn.tree import DecisionTreeClassifier #Decision tree classifier dtree = DecisionTreeClassifier(max_depth=3, random_state=23)
Build an Ensemble Model using Bagging Technique
The bagging ensemble model is initialized with the following:
- base_estimator = Decision Tree
- n_estimators = 5 – To create 5 bootstrap samples to train 5 decision tree base models
- max_samples = 50 – The number of items per sample is 50
- bootstrap = True – The sampling will be with replacement
from sklearn.ensemble import BaggingClassifier #Bagging ensemble model bagging = BaggingClassifier(base_estimator=dtree, n_estimators=5, max_samples=50, bootstrap=True)
Train the Ensemble Model
#Training the model bagging.fit(x_train, y_train)

Evaluate the Ensemble Model
#Evaluating the model print(f"Train score: {bagging.score(x_train, y_train)}") print(f"Test score: {bagging.score(x_test, y_test)}")
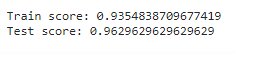
As we can see from the above result, a few learners or estimators are enough for small datasets. However, larger data may require more learners.
One of the most prominent advantages of bagging is that the samples are generated concurrently. So, when different base estimators are fitted independently, intensive parallelization techniques can be used as and when required.
Conclusion
We have discussed how to solve Machine Learning problems based on an ensemble learning – bagging. Ensemble models usually perform more accurately than a single model because they alleviate the overfitting problem while also combining the strengths of different models.
Artificial Intelligence & Machine Learning is an increasingly growing domain that has hugely impacted big businesses worldwide.
Top Trending Articles:
Data Analyst Interview Questions | Data Science Interview Questions | Machine Learning Applications | Big Data vs Machine Learning | Data Scientist vs Data Analyst | How to Become a Data Analyst | Data Science vs. Big Data vs. Data Analytics | What is Data Science | What is a Data Scientist | What is Data Analyst



This is a collection of insightful articles from domain experts in the fields of Cloud Computing, DevOps, AWS, Data Science, Machine Learning, AI, and Natural Language Processing. The range of topics caters to upski... Read Full Bio