
Extracting Information from Text Data Using Spacy in NLP
In this article, we will discuss how to extract structured information from unstructured textual data using the spaCy package and its functions – namely, nlp() and Matcher() to search for a pattern in a string.

Natural Language Processing (NLP) is one of the most fascinating subfields of data science. Knowledge of NLP is essential for data scientists to whip up solutions for exploiting unstructured textual data.
One of the most common tasks in NLP is to extract information, in a structured way, from textual data before performing an analysis on it. In this article, we will discuss how to accomplish this using the increasingly popular spaCy package in Python.

Introduction to Natural Language Processing
Natural Language Processing (NLP) is a branch of Artificial Intelligence that grants computers the ability to read and interpret the text in the same way as humans do.
“NLP is the process of analyzing, understanding, and deriving meaning from human languages for computers.”
Excerpts of human interaction through textual data in the form of tweets, text messages, etc. are highly unstructured. Traditional techniques are not capable enough to extract any direct information from such data due to variations in languages, slang, or tones used. This is where NLP comes in as a huge player in the industry by developing methodologies to bridge the gap between data science and human languages.
NLP finds its applications in a wide range of domains such as healthcare, fintech, media, etc. for utilizing data available in the form of text/speech to draw relevant outcomes from it. In fact, text & speech recognition apps such as Apple Siri and Amazon Alexa are built using NLP.
Must Check: NLP and Text Mining Online Courses & Certifications
Must Check: Introduction to Natural Language Processing
What is Spacy?
spaCy is an open-source Python package that is used to build systems that understand natural language and perform information extraction. It also helps in pre-processing text for neural networks in deep learning. Spacy makes more than 60 languages available for text processing such as English, Hindi, German, French, Spanish, and more. It is an industry-grade package that has lots of active standalone projects built around it.
Must Read: Deep Learning vs Machine Learning – Concepts, Applications, and Key Differences
Spacy Installation
The spaCy library can be installed in your working environment by executing the pip command in your terminal:
pip install spacy
Now, you can download one of the following pre-trained pipeline models from the command prompt, if required:
- en_core_web_sm — Size: small, 13 MB
- en_core_web_md —Size: medium, 44 MB
- en_core_web_lg — Size: large, 742 MB
The accuracy and speed of execution depend on which pre-trained model you have chosen.
Spacy Language Processing Pipeline
Once we have downloaded and installed our pre-trained pipeline model, as mentioned earlier, we will run the model through the nlp() pipeline which takes a string as a parameter and returns a spaCy Doc object.
When you invoke nlp(), you are running the following steps in the pipeline:

Let’s discuss each step briefly:
Tokenizer
This is always the first step before any text data processing in NLP. A Tokenizer in spaCy converts text into small segments comprising of words, symbols, and punctuations by applying specific rules to each language. These are referred to as tokens.
PoS Tagger
Once we have tokenized the text data, the next step is to perform Part-of-speech (POS) tagging to understand the grammatical properties (noun, verb, adjective, etc.) of each token. This component tags each token as a corresponding PoS based on the used language model.
Parser
This Component is for dependency parsing – to find the structure in text with the help of determining the relationship between words in a sentence.
NER (Named Entity Recognizer)
Named entities are “real world objects” that are assigned a name. This component helps us categorize words into certain generic names for further processes.
Attribute Ruler
This component sets attributes to individual tokens when you assign your own rules – like word/phrase token matching.
Lemmatizer
This component creates lemmas for each of the words/tokens in the doc. A lemma is a base word that has been converted through the process of lemmatization. For example, the word ‘magical’ will have the base word as ‘magic’ – this is the lemma.
Get Structured Information from Text Data Using Spacy
Problem Statement:
For demonstration, we will be creating a structured dataset from an excerpt of textual data using the spaCy library. As a dummy example, we are considering a Nobel Prize winners list, which contains the following text:
On February 12 1809 Nobel Prize winner Charles Darwin was born in UK. He was a naturalist, geologist and biologist. On November 20 1889 Nobel Prize winner Edwin Hubble was born in US. He was an astronomer. On November 7 1867 Nobel Prize winner Marie Curie was born in Poland. She was a physicist and chemist. On January 8 1942 Nobel Prize winner Stephen Hawking was born in UK. He was a physicist and cosmologist. On January 23 1918 Nobel Prize winner Gertrude Elion was born in US. She was a biochemist and pharmacologist.
Each row of the above text contains some details on each scientist. All the rows have the same structure. Let’s assume that this piece of text is stored in a text file by the name data.txt.
Tasks to be Performed:
From the ‘data.txt’ text file, we will extract the following information:
- Scientist’s name
- Surname
- Birthplace
- Birthdate
- Gender
We will be following these steps to extract the above information:
Step 1 – Convert the text into a Pandas DataFrame
We will create a Pandas DataFrame where each row corresponds to a line of text.
For that, we will open the text file, split it line-wise, and store each line as a list item. Then build a DataFrame, as shown:
import pandas as pd #Split the text and create a list with open('data.txt', 'r') as f: data = [line for line in f.readlines()] #Create a dataframe using the list df = pd.DataFrame(data,columns=['text']) df.head()

Must Read: How to Read and Write Files Using Pandas
Must Read: Series vs. DataFrame in Pandas – Shiksha Online
Step 2 – Perform PoS Analysis
Now, we will perform basic NLP processing by analyzing the structure of the sentence to extract Part of Speech (PoS) and perform PoS tagging.
We will import the en_core_web_sm lexicon and load all the lexicons of the languages supported by spaCy. Our focus here is going to be on the English language.
Now, we can start with our NLP processing:
import spacy import en_core_web_sm text = df['text'][0] nlp = en_core_web_sm.load() doc = nlp(text)
The processed information is stored in the variable doc, as specified above. Now, let’s extract PoS:
features = [] for token in doc: features.append({'token' : token.text, 'pos' : token.pos_})
Each token in the sentence now has a PoS tagged to it and stored in the list features. Now, we will create a DataFrame with these extracted features to visualize the results in an ordered manner.
fdf = pd.DataFrame(features) fdf.head(len(fdf))
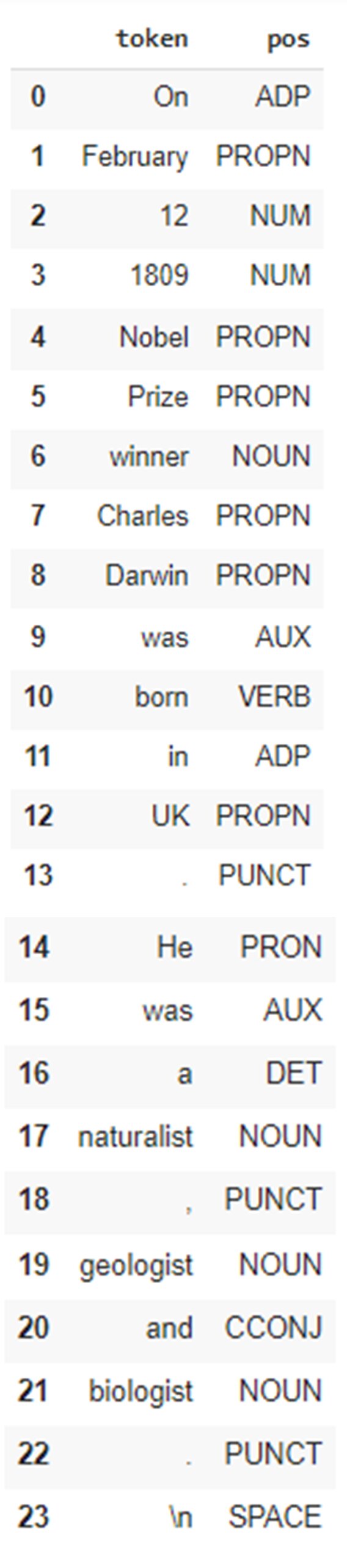
Step 3 – Extract the scientist name
From the above DataFrame, we note that the scientist (Charles Darwin) has been assigned the PROPN (proper noun) label, which means it is the name of the person.
We can also see that it is preceded by the word ‘winner’ and followed by the word ‘was’. Both observations are true for all the sentences.
Based on this, we will now build a pattern that extracts the scientist’s name and surname. To do this, we will define two variables first_tokens and last_tokens, as shown below. These will contain the preceding and following tokens respectively:
first_tokens = ['winner', 'name'] last_tokens = ['was', 'born']
We will define the pattern that identifies the scientist:
pattern_winner = [[{'LOWER' : {'IN' : first_tokens}}, #preceding words without case matching {'POS':'PROPN', 'OP' : '+'}, #searching for PROPN one or more times {'LOWER': {'IN' : last_tokens}} ]] #following words without case matching
Now, we will define the function that uses the spaCy.matcher() class to search for the above-defined pattern. If a match is found, the preceding and following words are removed from the match before returning the result:
from spacy.matcher import Matcher def get_winner(x): nlp = en_core_web_sm.load() doc = nlp(x) matcher = Matcher(nlp.vocab) matcher.add("matching_winner", pattern_winner) matches = matcher(doc) sub_text = '' if(len(matches) > 0): span = doc[matches[0][1]:matches[0][2]] sub_text = span.text tokens = sub_text.split(' ') name, surname = tokens[1:-1] return name, surname
Let’s use the apply() function to get the scientist name for each row:
new_columns = ['scientist name','surname'] for n,col in enumerate(new_columns): df[col] = df['text'].apply(lambda x: get_winner(x)).apply(lambda x: x[n]) df.head()
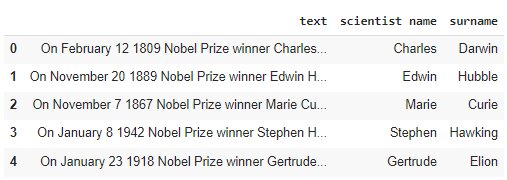
Step 4 – Extract the scientist birthplace
The process of extracting the birth country of the scientists is quite similar to the one we followed above to extract their names. So, let’s start with defining the first_tokens and last_tokens, as shown:
first_tokens = ['in'] last_tokens = ['.'] pattern_country = [[{'LOWER' : {'IN' : first_tokens}}, {'POS':'PROPN', 'OP' : '+'}, {'LOWER': {'IN' : last_tokens}} ]]
Similarly, we will define the function that extracts the birth country:
from spacy.matcher import Matcher def get_country(x): nlp = en_core_web_sm.load() doc = nlp(x) matcher = Matcher(nlp.vocab) matcher.add("matching_country", pattern_country) matches = matcher(doc) sub_text = '' if(len(matches) > 0): span = doc[matches[0][1]:matches[0][2]] sub_text = span.text #remove punct sub_text = sub_text[:-1] tokens = sub_text.split(' ') return ' '.join(tokens[1:])
Again, use the apply() function to get the country name for each row:
df['country'] = df['text'].apply(lambda x: get_country(x)) df.head()
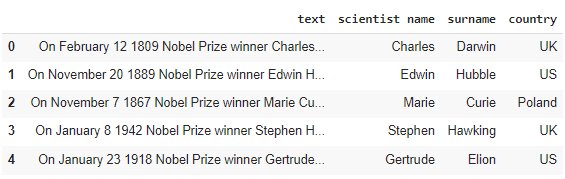
Step 5 – Extract the scientist birth date
Now, we will define a function to extract dates from the text. We will do this by tokenizing the sentence.
Note that the date format followed in the text is month-first. We will convert the month from string to number and return the dates in the format YYYY-MM-DD.
def get_date(x): months={"January":"01","February":"02","March":"03","April":"04", "May":"05","June":"06","July":"07","August":"08","September":"09", "October":"10", "November":"11","December":"12",} tokens = x.split(" ") # month month = months[tokens[1]] # day day=tokens[2] if(len(day)==1): day="0"+day # year year = x.split(" ")[3] return (year+"-"+month+"-"+day)
Now, we will use the apply() function to apply the above function to our DataFrame:
df['birthdate'] = df['text'].apply(lambda x: get_date(x)) df.head()
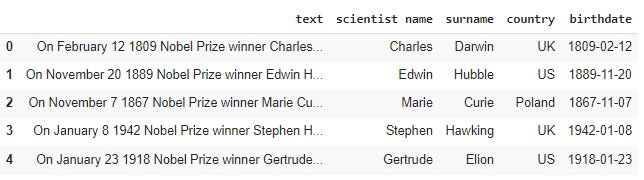
Step 6 – Extract scientist gender
Finally, we will extract the gender. This should be pretty easy – the idea is that if a sentence contains the word ‘He’, the gender is male, or else the gender is female.
Let’s define the function for it:
def get_gender(x): if 'He' in x: return 'M' return 'F'
Let’s apply this function to our DataFrame:
df['gender'] = df['text'].apply(lambda x: get_gender(x)) df.head()
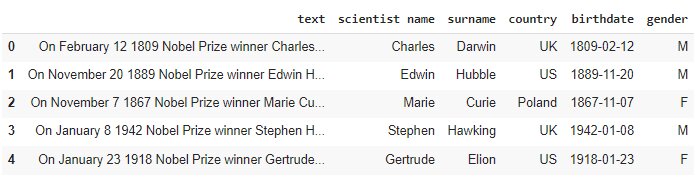
Step 7 – Save the information into a CSV file
Our structures dataset is ready and now we can export it as a CSV file, using a single line command:
df.to_csv('structured_data.csv')

Conclusion
In this article, we have learned how to extract structured information from unstructured textual data using the spaCy package and its functions – namely, nlp() and Matcher() to search for a pattern in a string. Spacy is an important and powerful library in Natural Language Processing.
Top Trending Articles:
Data Analyst Interview Questions | Data Science Interview Questions | Machine Learning Applications | Big Data vs Machine Learning | Data Scientist vs Data Analyst | How to Become a Data Analyst | Data Science vs. Big Data vs. Data Analytics | What is Data Science | What is a Data Scientist | What is Data Analyst

This is a collection of insightful articles from domain experts in the fields of Cloud Computing, DevOps, AWS, Data Science, Machine Learning, AI, and Natural Language Processing. The range of topics caters to upski... Read Full Bio
Comments
(1)
R
a month ago
Report Abuse
Reply to Raju