
How Can Decision Tree Handle Complex Data?
A decision tree’s objective is to categorize data into one of two groups based on a set of attributes. A decision tree might be used, for instance, to categorize emails as “spam” or “not spam” depending on the terms they contain.

In this article, we will investigate the extension of a decision tree to multi-class classification issues, which entail the classification of data into more than two categories. Before exploring the difficulties of multi-class classification and the many strategies that can be employed to solve them, we will first go through the fundamentals of decision trees and binary classification. Finally, we will look at several real-world situations where decision trees are being utilised to manage complex data.
Table of Contents
- Introduction
- Knowledge of decision trees
- Decision Trees and Binary Classification
- Deterministic Multi-Class Classification
- Practical Case Studies
Introduction
A well-liked machine learning approach for classification and regression tasks is decision trees. They are very helpful for analysing complex data since they can handle a lot of features and can understand intricate correlations between those features. However, the majority of conventional decision tree algorithms are only intended to address binary classification issues, which limits their ability to divide data into two groups. When working with larger, more complicated data sets, this restriction can be troublesome because the categorization issue might call for more than two categories.
Explore machine learning courses
Knowledge of Decision Trees
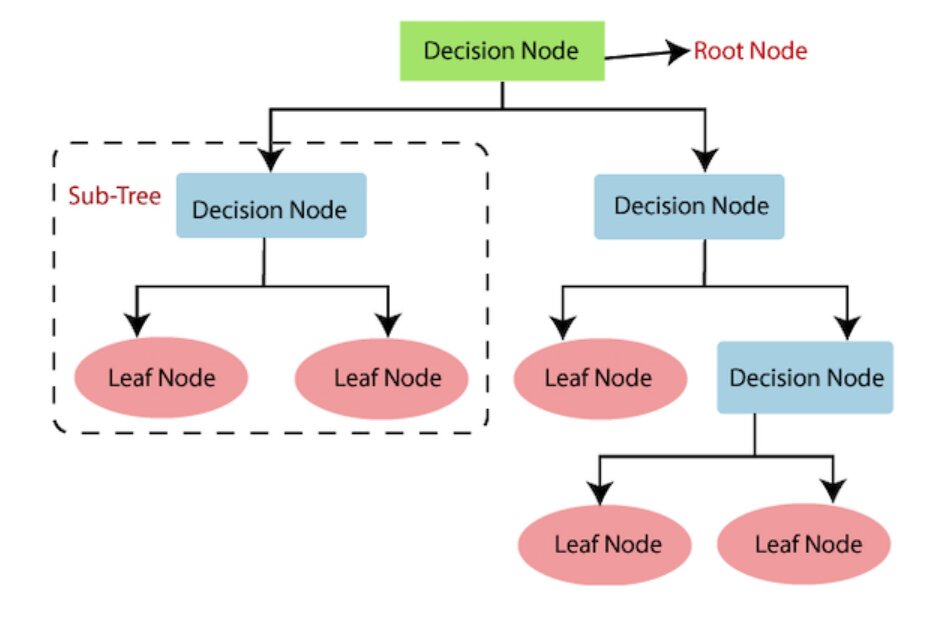
Let us first go through the fundamentals of binary classification and decision trees before getting into the specifics of multi-class classification. A set of decisions and the results of those decisions are represented by a tree-like structure called a decision tree. The edges of the tree depict the potential outcomes of each node, which in turn represents a choice or characteristic.

The algorithm begins by determining the most crucial attribute that will result in the greatest information gain before constructing a decision tree. Entropy before and after the feature is employed to divide the data is measured as information gain. The data is divided into two subsets using the feature with the maximum information gain, and these subsets are then further divided using other features up until a stopping requirement is satisfied. The least quantity of information gained, the minimum number of samples needed to split a node, or the maximum depth of the tree could all serve as this stopping condition.
Following the construction of the decision tree, fresh data can be classified using it by moving up the tree from the root node to a leaf node, where the leaf node denotes the classification result. As an illustration, in an issue involving spam categorization, the root node would stand in for the existence of the term “Viagra,” while the leaf nodes might stand in for “spam” or “not spam.”
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses

Decision Trees and Binary Classification
Decision trees have been discussed thus far in the context of binary classification issues, where the objective is to categorise data into one of two groups. These can be used to tackle binary classification problems with relative ease since the tree can be constructed using the attributes that give the maximum information gain for distinguishing the two classes.

For illustration, suppose we obtain a dataset of weather reports from a meteorological department and we want to foretell whether the rain will come or not. We might create a decision tree utilising criteria like temperature, wind, and humidity. The leaf nodes would signify “rain” or “not rain,” and the tree would be constructed using the feature that yields the largest information gain at each stage.
Example
Preparing the data
To illustrate binary classification, we will utilise the scikit-learn breast cancer dataset. The malignancy and benignity of breast cancer tumours are described in this dataset. The dataset will be loaded and divided into training and testing sets.
Python code:
from sklearn.datasets import load_breast_cancerfrom sklearn.model_selection import train_test_split
breast_cancer = load_breast_cancer()X_train, X_test, y_train, y_test = train_test_split(breast_cancer.data, breast_cancer.target, test_size=0.3, random_state=42)
Training the Decision Tree
The training data will then be used to train a decision tree. The DecisionTreeClassifier class from Scikit-Learn will be used to build the model. In order to avoid overfitting, we will additionally limit the depth of the tree by setting the max_depth option to 3.
Python code:
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(max_depth=3, random_state=42)clf.fit(X_train, y_train)
Making Predictions
We may use the decision tree model to generate predictions on the test data now that it has been trained. On the basis of the test data, predictions will be made using the predict method of the DecisionTreeClassifier class.
Python code:
_pred = clf.predict(X_test)
Evaluating the Model
We will use the accuracy score from scikit-learn to assess the performance of our decision tree model. This indicator determines the percentage of instances in the test data that were correctly categorised.
Python code:
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_pred)print(f"Accuracy: {accuracy}")
Output:
Accuracy: 0.9649122807017544
Visualizing the Decision Tree
In order to understand how the decision tree generates its predictions, we may finally visualise it. The tree will be exported in Graphviz format using the scikit-learn export_graphviz function, and will then be visualised using the graphviz library.
Python code:
from sklearn.tree import export_graphvizimport graphviz
dot_data = export_graphviz(clf, out_file=None, feature_names=breast_cancer.feature_names, class_names=breast_cancer.target_names, filled=True, rounded=True, special_characters=True)graph = graphviz.Source(dot_data)graph.render("breast_cancer_decision_tree")
Output:

The decision tree, which is composed of nodes and edges, is shown graphically in the Image. The edges stand in for the branches that connect the nodes, while the nodes themselves serve as decision points. Every node in the decision tree corresponds to a choice or feature, and every edge shows the potential results or values of that choice.
The root node, which is the topmost node in the tree, serves as the tree’s initial point of decision. The root node reflects the first choice the model makes in the event of the binary classification problem we previously presented, namely whether a tumour is malignant or benign.
The decision tree is divided into layers, and each level corresponds to a choice the model made. The decisions get more specific and the tree branches out into more options as we proceed down the decision tree.
The model’s final judgement is represented by each leaf node in the tree. Each leaf node in a binary classification represents a categorization choice, either benign or malignant.
The decision tree is displayed graphically in the Image created by the code, and each node is labelled with the decision or feature it stands for. The decision’s potential outcomes or values are labelled on the edges linking the nodes, and the leaf nodes are labelled with the classification’s final determination. The decision tree’s visual representation can give us insights into the data and the model’s operation, as well as into how the model classifies objects.
Deterministic Multi-Class Classification
Let’s now have a look at the situation of multi-class classification issues, where the objective is to divide the data into more than two groups. Compared to binary classification issues, multi-class classification problems are more difficult to solve since there are more potential outcomes and probable complexities in the interactions between the features.
Using multiple binary decision trees, commonly referred to as “one-vs-all” or “one-vs-rest” classification, is one method for solving multi-class classification issues with decision trees. In this method, each class is represented by a separate binary decision tree that distinguishes it from all other classes. For instance, if we have a dataset of photos and want to categorise them into various animal species, we might construct distinct decision trees for each animal class (such as dogs, cats, birds, etc.), where each tree distinguishes the animal class from the other classes.
This strategy may be successful, but it also has the potential to produce imbalanced trees, where one class has more samples than the others. Because the decision tree will be biased in favour of the majority class, this could lead to subpar performance of the minority classes. Additionally, it may not scale well to huge datasets and be computationally expensive to construct many decision trees.
Using a single decision tree that can handle several classes is another method for using decision trees to solve multi-class classification problems. The “one-vs-one” classification strategy, which entails creating a separate binary decision tree for each pair of classes, is a well-liked algorithm for this. We would construct three binary decision trees, one for A vs. B, one for A vs. C, and one for B vs. C, for instance, if we had three classes (A, B, and C). We would use each of the three decision trees to classify a new sample before using a voting system to establish the final classification.
Utilising a multi-class splitting criterion, such as the Gini impurity or information gain, is an alternative strategy. Instead of only two subsets, as in binary classification, nodes are divided into many subsets based on the class labels of the samples. This method may be less biassed towards the majority class and more effective, but it may also be more prone to overfitting.
Example:
Preparing the Data
We will utilise the well-known iris dataset from scikit-learn to show how decision trees can perform multi-class classification. This dataset includes data on the setosa, versicolor, and virginica varieties of iris blooms. The dataset will first be loaded and divided into training and testing sets.
Python code:
from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_split
iris = load_iris()X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=42)
Training the Decision Tree
The training data will then be used to train a decision tree. The DecisionTreeClassifier class from Scikit-Learn will be used to build the model. In order to avoid overfitting, we will additionally limit the depth of the tree by setting the max_depth option to 3.
Python code:
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(max_depth=3, random_state=42)clf.fit(X_train, y_train)
Making Predictions
We may use the decision tree model to generate predictions on the test data now that it has been trained. On the basis of the test data, predictions will be made using the predict method of the DecisionTreeClassifier class.
Python code:
y_pred = clf.predict(X_test)
Evaluating the model
We will use the accuracy score from scikit-learn to assess the performance of our decision tree model. This indicator determines the percentage of instances in the test data that were correctly categorised.
Python code:
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_pred)print(f"Accuracy: {accuracy}")
Visualizing the Decision Tree
In order to understand how the decision tree generates its predictions, we may finally visualise it. The tree will be exported in Graphviz format using the scikit-learn export_graphviz function, and will then be visualised using the graphviz library.
Python code
from sklearn.tree import export_graphvizimport graphviz
dot_data = export_graphviz(clf, out_file=None, feature_names=iris.feature_names, class_names=iris.target_names, filled=True, rounded=True, special_characters=True)graph = graphviz.Source(dot_data)graph.render("iris_decision_tree")
Output:
Although there are a few differences, the Image created for a multi-class classification problem using decision trees is similar to the one created for binary classification. Each leaf node in the decision tree in this scenario represents a different class label, and the decision tree is built to support several classes.
Based on the features in the incoming data, the nodes in the tree reflect decision points. Each decision node has one or more edges that are representative of the decision’s potential values. The value of the feature leading to that branch is written on the edges as a label.
The tree analyses the incoming data at each decision node and decides depending on the values of the characteristics. The model then moves on to the next decision node by following the branch that corresponds to the decision’s value.
The final classification of the input data is shown by the leaf nodes in the tree. Each leaf node has a unique class label that serves as the projected output for the input data for that leaf node.
Each node in the decision tree is identified in the PDF file with the feature and decision that it represents, and the edges are identified with the decision’s values. The projected class label is applied to each leaf node.
We can learn more about the categorization decisions the model is making by looking at the decision tree in the PDF file. We can also determine which characteristics are most crucial to the model’s decision-making. Understanding the data and enhancing the model’s performance can both benefit from this knowledge.
Practical Case Studies
Many different applications, such as image classification, text classification, and medical diagnosis, have employed decision trees to manage complex data. Here are a few real-world illustrations:
- Image Categorization: Decision trees have been used to categorise photos into several groups, such as various species of animals or objects. A decision tree, for instance, might be used to categorise fresh photographs based on the presence of specific traits like fur, feathers, or scales after being trained on a dataset of animal images.
- Text Classification: Text data classification techniques like sentiment analysis and spam categorization have also been applied to decision trees. In order to categorise incoming reviews as positive or negative based on the existence of particular keywords or phrases, a decision tree might, for instance, be trained on a dataset of customer reviews.
- Medical Diagnosis: Based on patient information such as symptoms, test findings, and medical history, decision trees have been used to diagnose medical disorders. To diagnose a new patient based on their symptoms and test results, for instance, a decision tree might be trained on a dataset of patient data.
Conclusion
A number of applications may manage difficult data using decision trees, a potent machine learning method. Traditional decision tree methods are built to address binary classification issues, but there are a number of ways to adapt them to handle multi-class classification issues as well. You can select the strategy that will work best for your particular challenge and increase the precision of your classification models by being aware of these approaches’ trade-offs.
Decision trees are a flexible and strong machine-learning technique that can handle complex data in a range of applications. Traditional decision tree methods are built to address binary classification issues, but there are a number of ways to adapt them to handle multi-class classification issues as well. These include multi-class splitting criteria, one-vs-all and one-v-one classification, and. In order to increase the precision and robustness of the classification model, decision trees can also be utilised in ensemble approaches and feature selection procedures. You can select the strategy that is ideal for your particular problem and create classification models that are more precise and efficient by being aware of various approaches’ trade-offs.
Contributed by: Vishwa Kiran

This is a collection of insightful articles from domain experts in the fields of Cloud Computing, DevOps, AWS, Data Science, Machine Learning, AI, and Natural Language Processing. The range of topics caters to upski... Read Full Bio