
Info Entropy in Information Theory
Calculating information and entropy is a useful tool in machine learning and serves as the foundation for techniques like feature selection, decision tree construction, and, more broadly, fitting classification models. This post will give you a basic understanding of information entropy.

You will understand the following after reading this post about how Information theory is concerned with Machine Learning and how Info Entropy is crucial a measure of information in Information Theory.
Table of Contents
- What is Information?
- Information theory
- Information theory in machine learning
- Information Entropy
- Mutual Information
- Example Application of Entropy: DNA Sequence Analysis
- Implementing Information Entropy for DNA Sequence Analysis using Python
- Applications of Information Entropy in Machine Learning
What is Information?
A collection of facts is what information is. This phrase has been used in every scenario imaginable. But, quite rightly, the world runs on information.
So, what exactly is it?

Let’s try to understand this using an example:
Assume you’ve gone grocery shopping and purchased several items. Because you know the prices of those items, that is raw data for you.
When you check out at a counter, the cashier will scan those items and give you the total cost. To explain, the cashier will total the number of items and the cost of each item and give you a fixed amount that you can pay. In a sense, the cashier processed raw data (individual item prices) and provided you with information (final bill amount). As a result, I can define information as processed data that is contextually relevant.
Information Theory
To understand the information with the help of an example, here are two messages:
- I did not report to work.
- I was absent from work due to a doctor’s appointment.
The second message contains more information than the first. But how am I going to define “more”? How do I put a number on it? This is where Information Theory comes into play!
Information theory is a branch of mathematics concerned with data transmission over a noisy channel.
The idea of quantifying how much information is in a message is a cornerstone of information theory. More broadly, entropy, which is calculated using probability, can be used to quantify the information in an event and a random variable.
Information Theory in Machine Learning
We can use information theory to measure and compare the amount of information in different signals. In this section, we will look at the fundamental concepts of information theory as well as their applications in machine learning.
Let us first define the relationship between machine learning and information theory.
The goal of machine learning is to extract interesting signals from data and make important predictions.
Information theory, on the other hand, is the study of encoding, decoding, transmitting, and manipulating information.
As a result, information theory serves as a foundational language for discussing information processing in machine-learning systems.
Information Theory techniques are probabilistic and typically deal with two specific quantities, namely Information Entropy and Mutual Information. Let’s dig a little deeper into these two terms.
Explore machine learning courses
Best-suited Python courses for you
Learn Python with these high-rated online courses

Info Entropy
Entropy is a measure of a random variable’s uncertainty or the amount of information required to describe a variable.
Entropy is the measure of the average information content. The higher the entropy, the higher the entropy, and the more information that feature contributes.
Info Entropy (H) can be written as:

Where,
X – Discrete random variable X
P(xi) – Probability mass function
Where is Entropy Used?
Entropy is used in Machine Learning for feature engineering.
The Entropy of a feature f1 is calculated by excluding feature f1 and then calculating the entropy of the remaining features.
Now, the higher the information content of f1 is, the lower the entropy value (excluding f1). The entropy of all the features is calculated in this manner. Finally, either a threshold value or a further relevancy check determines the optimality of the features that are chosen. Entropy is commonly used in Unsupervised Learning because the dataset contains a class field, and thus the entropy of the features can provide significant information.
Mutual Information
Mutual information in information theory is the amount of uncertainty in X due to knowledge of Y. Mutual information is defined mathematically as Mutual Information in Machine Learning is primarily calculated to determine the amount of information shared about a class by a feature.
The mutual information between two random variables X and Y can be stated formally as follows:
I(X ; Y) = H(X) – H(X | Y)
Where,
I(X ; Y) = Mutual information for X and Y,
H(X) = Entropy for X
H(X | Y) = Conditional entropy for X given Y.
Mutual Information is mostly used in Supervised Learning for dimensionality reduction. In supervised learning, features with a high mutual information value corresponding to the class are considered optimal because they can influence the predictive model toward the correct prediction and thus increase the model’s accuracy.
Example Application of Entropy: DNA Sequence Analysis

Genealogists examine various complexity measures for DNA sequence analysis and employ Information Entropy to quantify the amount of complexity in small chromosomal segments.
They collect chromosome DNA samples and cut them into finite sub-segments.
Calculate the Entropy on the sub-segment using the frequency of the characters (ATGC- which is common in DNA fragments) as the P. (X).
Repeat the process for the remaining chromosomes.
After running the analysis through this pipeline, the Information Entropy across the DNA sequence was plotted on a graph to produce the map shown below:
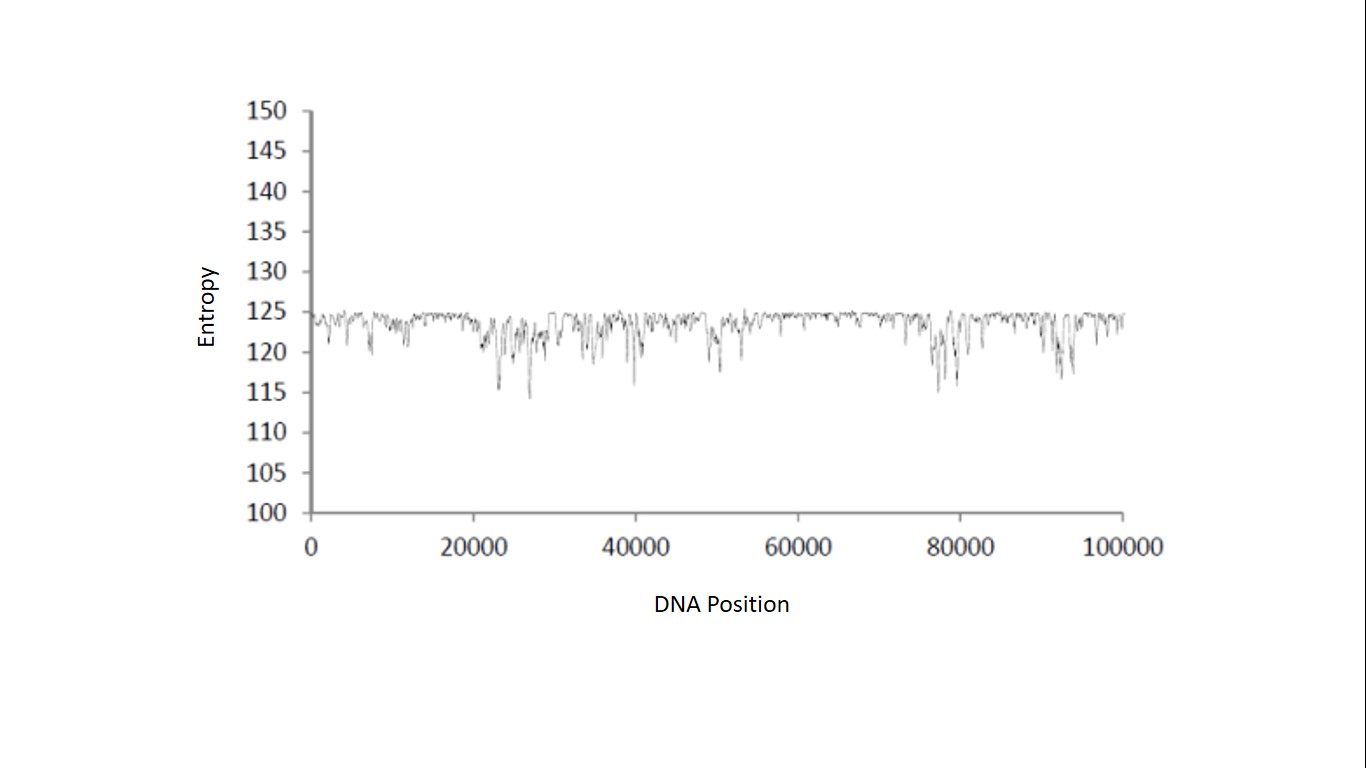
With this metric, we can determine which areas of a DNA sequence are more or less “surprising” and have higher information content.
Let’s see how we can recreate that graph with a Python implementation!
Explore free Python courses
Implementing Info Entropy for DNA Sequence Analysis using Python
Let’s write a Python code for computing entropy for a given DNA/Protein sequence.
Code Example:
import collections from scipy.stats import entropy def estimate_information_entropy(dna_sequence): bases = collections.Counter([tmp_base for tmp_base in dna_sequence]) # define distribution dist = [x/sum(bases.values()) for x in bases.values()] # use scipy to calculate entropy entropy_value = entropy(dist, base=2) return entropy_valueprint("Entropy of Given DNA Sequence is:", estimate_information_entropy("ATCGTAGTGAC"))
Code Output:
Entropy of Given DNA Sequence is: 1.9808259362290785
Applications of Info Entropy in Machine Learning
There are many more applications of Information Entropy in Machine Learning, but let’s discuss a few popular ones.
Decision Trees
Decision Trees (DTs) are non-parametric supervised learning methods that can be used for classification and regression. ID3 is the name of the core algorithm used here. It uses a top-down greedy search approach and involves partitioning the data into homogeneous subsets. The ID3 algorithms determine the partition by calculating the sample’s homogeneity using entropy. Entropy is zero if the sample is homogeneous, and maximum entropy is if the sample is uniformly divided.
Cross-Entropy
It is the difference between two probability distributions for a given random variable or set of events that is measured as cross-entropy.
Cross-entropy is commonly used in deep learning models. It is used as a loss function to assess the performance of a classification model, the output of which is a probability value ranging from 0 to 1. As the predicted probability diverges from the actual label, cross-entropy loss increases.
Calculating The Imbalance in Target Classes Distribution
In Machine Learning, target class imbalances can be calculated using entropy. If we consider the predicted feature to be a random variable with two classes, a balanced set (50/50 split) should have the highest entropy. However, if the distribution is skewed and one class has a 90% prevalence, there is less knowledge to be gained, resulting in a lower entropy. We can use the chain rule to calculate entropy to see if a multiclass target variable is balanced in a single quantified value, albeit an average that masks the individual probabilities.
Kullback-Leibler (K-L) Divergence
The Kullback-Leibler Divergence score abbreviated as the KL divergence score, which is based on the theory of relative entropy, quantifies how much one probability distribution differs from another.
The KL divergence between two distributions Q and P is frequently expressed using the notation:
KL(P || Q)
Where the “||” operator indicates “divergence” or P’s divergence from Q.
Conclusion
In this blog, we discussed how Information Theory is an exciting field that makes significant contributions to a variety of fields. Machine Learning, for example, has not fully utilized everything that Information Theory has to offer.

This is a collection of insightful articles from domain experts in the fields of Cloud Computing, DevOps, AWS, Data Science, Machine Learning, AI, and Natural Language Processing. The range of topics caters to upski... Read Full Bio