
Internal dynamics of the Recommendation Engine using collaborative filtering from scratch
Let’s start the article by thinking!
Think of a situation that you watched three movies on Netflix and the next time you logged in to the platform you receive a tailor-made list of movies that were specifically recommended to you. Wouldn’t that be awesome? That saves your time to find movies of your liking and vastly improves your user experience.

The algorithm which does this for you is a Recommendation Engine. Your own personal automated AI companion who can better serve you by knowing your preferences.
In today’s world Recommendation engine is essential for almost all e-commerce or online businesses ranging from Netflix, Amazon, Flipkart to Meesho, Zomato to have a competitive advantage over their counterparts. An effective personalized recommendation engine capable of enhancing the consumer experience, attract more traffic to the web page which in a way helps to grow their business without losing the existing consumer base. Hence, in today’s world building a recommendation engine using a data driven approach is in high demand.
You can also explore: Movie Recommendation System using Machine Learning
In this article we will cover how to build a recommendation engine using collaborative filtering which is a leading data driven algorithm vastly used by top tech giants over and again. If you don’t understand what collaborative filtering is, nothing to worry about!
We will cover all the behind-the-scenes explanations and perceptions of collaborative filtering along with how it can be used for recommendations.
So, let’s get started.
Content
- Back story of Recommendation Engine
- Collaborative Filtering overview
- Measures of recommendation effectiveness
- Conclusion
Back story of Recommendation Engine
If we look closely at how we used to make purchases in the past, you will see that most of the time, you consult your friends, family, or the merchandise supplier for recommendations prior to making a purchase. But in the dawn of digital age, product variety increased exponentially, making it very difficult to find a close relative who would highly recommend a given product that would suit your tastes.
You can also explore: Engineer who claimed AI has come to life suspended by Google!
The recommendation engine steps in at this point. It uses a consumer’s prior history to identify preferable consumer groups with similar preferences and then uses that information to calculate a consumer’s preference score or likelihood of liking of an undiscovered product.
Now the obvious question that one can ask.
What will I do if a consumer has no prior history available? What if the consumer is a new one?
There are a few potential solutions in that case, and it could be a completely different topic to illustrate and hence, not in the scope of this article to discuss in detail but nevertheless let me mention one of the most obvious ways to do it. The Recommendation engine can explore the most purchased products/popular movies across all consumers to recommend those for the “first-timers”. If you presume that, by this approach the resulting recommendation list for new consumers will be static and not tailored to their needs – then you are right. This is a draw back for the engine in this specific scenario.
Must explore: Curse of Dimensionality
Thoughts to ponder: What if you can collect the attributes of the new consumers and do a profiling against old consumers to identify a consumer group like new one and then use that information to make recommendations? This approach will cater the need of the new customer in a large extent compared to a static list approach discussed earlier.
Now that we have discussed about the recommendation engine and some of its aspect let’s dive into collaborative filtering.
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses

Collaborative Filtering Overview
Collaborative filtering is a technique for determining a user’s reaction to unexplored items. This is what it is. Let us assume that there are 15000 movies are present across the platform of Netflix. If a user had rated 5 different movies, then the task is to determine the ratings that could have given by the user to the other movies based on these 5 ratings. This can be achieved by collaborative filtering.
Before jumping into the practical details of Collaborative filtering one may ask for a simple approach.
What if I can identify the similar movies to the ones which were rated highly by a user and endorse similar movies to them?
Well yes. This is one way to go about it. The technique which can be used to achieve this is popularly known as Content Based Filtering.
Content Based Filtering
The primary goal of this technique is to identify the similar movies or products depending on their characteristics or features. Every item is represented by a set of numbers known as “Characterization Vector (CV)”. This is one key step in many data science use cases to identify the correct “Characterization Vector” which adequately represent the item under consideration. For an example, to identify a movie in terms of CV different genre parameters can be chosen like action, comedy, horror, sci-fi, drama etc.
This CV can be further modified by adding some other parameters like whether the movie is old or new, longer than 90 minutes or not etc which can further improve the movie’s CV representation. This process of identifying the right combination of CV solely depends on the use case and accuracy under consideration. Again, one can use 1/0 just to represent the presence or absence of different genre like action, comedy or can use floating point numbers like 0,0.5 or 1 to represent the presence and intensity of the presence in the movie. This is another intriguing idea that can be evaluated during the CV creation process.
For example, James Cameron movie “The Avatar” can be represented by the below Characterization Vector.

The movie is primarily a science-fiction action movie. So, in the above vector Sci-fi and Action genre indicators are 1. As discussed above one can add additional features like “New/Old”, any movie after 2005 considered “New”, also if the run time is less than 90 minutes then the “Run-Time” indicator will be 1.
The next step is to calculate the similarity between all the movies using co-sine similarity. Again, any other similarity measure also can be tried out.
(One fun fact to try out, no matter what similarity measure one uses the relative similarity strength and direction between items remain the same.)
Sim(A,B)=Cosinesimilarity(A,B)=∑ni=1aibi(∑ni=1a2i−−−−−−−√2∗∑ni=1b2i−−−−−−√2)/SimA,B=CosinesimilarityA,B=∑i=1naibi∑i=1nai22∗∑i=1nbi22 (*)
The above formula can be used to calculate all possible pair of similarity scores between the movies. In these scenarios, the measure of cosine similarity will vary between 0 to +1. 0 being the lowest similarity and +1 being the highest similarity between two objects under consideration.
You can also explore: Introduction to Semi-supervised Learning
The next step is to recommend movie based on the scores. As a first step we can identify the top-rated movies by the user. For recommendation purposes, either of the approaches listed below can be used against each top-rated movie.
- Top N movies: Sort all the movies in descending order of similarity and pick top N to recommend.
- Threshold Approach: Recommend all the movies that clear the threshold.
The one major disadvantage of using the content-based filtering is it fails to recommend new kind of movies/products to the user. This can be addressed by using the collaborative filtering.
Collaborative Filtering are primarily of two types:
- User based Collaborative Filtering
- Item based Collaborative Filtering
User Based Collaborative Filtering
The primary idea of this variant of collaborative filtering is to identify the most similar user for the given user under consideration and then use the ratings or inputs of those similar users to identify the rating of an unseen product for the given user.
Let’s consider the below data set to illustrate the model:
| UserItem | I1 | I2 | I3 |
|---|---|---|---|
| U1 | 2 | – | 4 |
| U2 | 5 | 2 | – |
| U3 | 3 | 3 | 1 |
| U4 | – | 2 | 2 |
In the above table we can see that U1 (user1) has rated I1(item1) and I3(item3) where as U2 has rated all I1 and I2. The highest possible rating that can be associated with any item is 5 and the lowest is 1.
Let us identify similar user for U1:
We need to represent all the user in terms of ratings of items and only consider those items which are present for both users. For example,
U1 = 2*I1 and U2 = 5*I1 (as I1 is the only item common between U1 and U2) and using the cosine similarity measure in (*) the similarity score is (2*5)/ (Ö4*Ö25) =1
Similarly, U1=2*I1+4*I3 and U3 = 3*I1+1*I3 and similarity score is: .70
Again, U1=4*I3 and U4=2*I3 and similarity score is: 1
As we observed that U2 and U4 both having maximum similarity score with U1 so item I2 can be recommended to U1.
There is another sophisticated way to predict the score for Item2 by User1. We will discuss that aspect in detail in the next phase.
One major disadvantage of using the method is to identify the similarity scores between all the users. As in reality, number of users will be in millions (if not in billions) hence computing all possible similarity scores for every individual is extremely time and space extensive process.
In this case, Item based Collaborative Filtering comes in handy.
Item Based Collaborative Filtering
First, the concepts and the implementation of item based collaborative filtering goes hand in hand with user based collaborative filtering, but as the number of items will always be significantly smaller than number of users hence it is more effective to use in almost all real-life applications.
In case of item based collaborative filtering the similarities between the items are determined and those are used to predict the rating of an unrated item by the user. Yes, we are going to predict the rating here as mentioned earlier. Again, just to highlight that the characterization vector (CV) for an item can be anything and not restricted to ratings only which we are going to use here for further illustrations.
Let us consider the below data table from the last illustration:
| UserItem | I1 | I2 | I3 |
|---|---|---|---|
| U1 | 2 | – | 4 |
| U2 | 5 | 2 | – |
| U3 | 3 | 3 | 1 |
| U4 | – | 2 | 2 |
The first step is to find the similarity between the items.
Hence, we need to represent the items in the vector form and compute the cosine similarity.
For the similarity between I1 and I2: (Only need to consider those users who have rated both the items)
I1=5*U2+3*U3
I2=2*U2 + 3*U3
and the similarity score between I1 and I2 is ((5*2) +(3*3)) / (Ö34*Ö13) = .90
Similarly, for I2 and I3:
I2= 3*U3 + 4*U4 and I3=1*U3 + 2*U4
Similarity score is: .86
Using the above illustrations calculate the similarity score of I1 and I3. which will be .78.
Okay, so the first stage is completed.
Let’s begin the second stage of predicting the ranking with the following formulation.
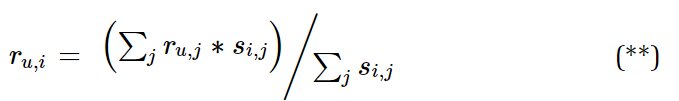
Now,
ru,i = rating for the ith item for the uth user which we want to predict.
ru,j = known rating for the jth item for the uth user.
si,j = similarity between the ith and jth item ( which we computed in the first step).
Now let’s understand it with an example:
Say we want to predict the rating of I2 for user U1.
Hence, by using the formula stated in (**) it will come out to be
= { 2 ( rating of I1 given by U1) * .90 ( similarity score of the product I2 and I1) + 4 ( rating of I3 given by U1) * .86 ( similarity score of the product I2 and I3) } / (0.9 +0.86) ( similarity score of I2 with I1 and I3 respectively)
= 2.97
@ 3
Now that we’ve learned how to predict an unknown rating, consider what comes next.
The next step to use these predicted ratings to recommend the new items to the user. As mentioned earlier as well two popular approaches can be –
- Sort predicted ratings in descending order and recommend top N items to the user.
- Recommend everything which is higher than the threshold ( one choice of threshold could be the average rating of the user across items).
To summarize all important advantages of this algorithm –
- A new and diverse range of items can be recommended.
- It is not time or computationally expensive, so it can be easily implemented with real-world data sets.
But, before we wrap up the algorithm discussion, let’s look at two important borderline cases.
New user – When a new user comes into the platform for the first time no ratings for that user is available, hence the algorithm can’t be used.
A simple work around here could be to recommend a list of highest rated items.
A better more dynamic approach could be to use a fusion of user based collaborative filtering where the CV will be made up by customer profiling parameters like gender, age-group, nationality etc rather than ratings and similar concept of user-based filtering can be extended here to find out a group of similar users and then recommend items/products.
New Items – When a new item is introduced for the first time, the above algorithm cannot be used because the item does not yet have a rating.
Here, a variant of content-based filtering can be used where the CV for the new item and the other items are made of items specifications rather than ratings. One example of such kind could be the CV representation of movies that got discussed earlier in content-based filtering.
Final step is to evaluate the effectiveness of the filtering algorithms.
Measures of recommendation effectiveness
There are various ways to identify the effectiveness of the recommended items.
Two most popular approaches are Recall and Precision.
Recall : This measures the effectiveness of recommendation engine by capturing the proportion of items that the engine can successfully recommend out of total likings of the user. The formula for recall is :
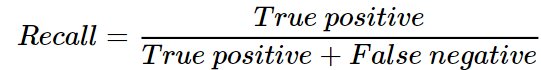
True positive : Number of items recommended to the user which are liked by the user.
False negative : Number of items liked by the user which were not recommended.
So, True positive + False negative gives the total number of items liked by the user.
Recall ranges between 0 to 1. The higher the recall value, the more efficient the engine.
Precision : This measure captures the effectiveness of the total recommended products by the engine.
Again, take a pause and think about the situation what if someone recommends everything to a user without using a ML algorithm. In that case Recall will always be 1 (right ?). Here is where we need precision to overcome this shortcoming of recall.
The formula is :
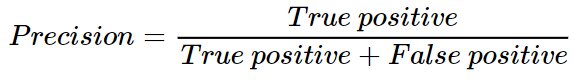
True positive : Number of items recommended to the user which are liked by the user.
False positive : Number of items not liked by the user which were recommended.
Precision also ranges between 0 to 1 and larger the precision the better.
Hence, one needs to find a solution where Precision and Recall both gets the optimum larger value.
Conclusion
I hope this article is good enough for anyone to start with the basics of recommendation engine and eventually gets a deep dive of different aspects of collaborative filtering and how to use these algorithms to build a customize engine cater to their need.
Many of the aspects of this article demands a separate article of its own and hence out of scope of this one, but from time to time I have tried to give a flavor and hint in which direction the algorithms and the concepts can be tweaked for research and further exploration purposes.
Finally , I will recommend anyone to code up the implementation of your own without libraries using the concepts and theories that discussed above.
You can also explore: Top 10 Machine Learning Projects for Beginners
Happy Learning !
Author: Souvik Chakraborty

This is a collection of insightful articles from domain experts in the fields of Cloud Computing, DevOps, AWS, Data Science, Machine Learning, AI, and Natural Language Processing. The range of topics caters to upski... Read Full Bio