
Introduction to Word Embeddings in NLP
In this article, we will learn the concept of word embedding, and its importance. Later in the article, we will also learn the concepts of continuous bag of words model, continuous skip-gram model, and finally we will also discuss the concept of global vectors for word representation.

Humans are naturally skilled in language comprehension. While it may be easy for us to recognize relationships between words, such as king and queen, man and woman, and tiger and tigress, it can be challenging for computers to grasp these connections. Word embeddings are a solution to this challenge, serving as a bridge between human and machine language understanding.
In this article, we shall delve into the introduction to Word Embeddings – an approach used in Natural Language Processing (NLP) for text analysis.
We will be covering the following sections today:
- Introduction to NLP
- Bag of Words
- What are Word Embeddings?
- Why do we need Word Embeddings?
- Word2Vec
- GLoVe (Global Vectors for Word Representation)
Introduction to NLP
NLP is a branch of computer science that focuses on developing systems that can understand human language. This includes analyzing and processing words and sentences to extract valuable information. Some applications of NLP include text summarization, sentiment analysis, language translation, and chatbots.
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses

Bag of Words
Machine learning models are not capable of processing text; therefore, we must find a way to convert textual data into numerical data. Techniques such as Bag of Words, and Count Vectorizer are commonly used to achieve this task. Let’s understand how:
Bag of Words is a straightforward and widely-used method for extracting features from text. The model counts the frequency of each word in a sentence, also known as vectorization.
In a text classification problem, there is a text and respective labels. We use the Bag of Words model to extract features from the text. This is done by converting the text into a matrix of occurrences of words within a document.
Limitations of Bag of Words Approach
The problem with the bag of words model is that it represents each document as a vector of word counts. These counts can be binary (indicating whether a word appears in the text or not) or absolute counts. The size of the vector is equal to the number of elements in the vocabulary, and if most elements are zero, the bag of words will be a sparse matrix.
In deep learning, the use of sparse matrices is common due to the large amounts of training data. However, sparse representations are more difficult to model, both for computational and informational reasons.
The issues include:
- A large number of weights, resulting from large input vectors
- Computationally intensive, requiring more computation to train and predict due to the increased number of weights
- A lack of meaningful relationships and no consideration for the order of words, as the bag of words only collects words from the text or sentences and their counts, ignoring the order in which they appear.
These issues can be resolved by using Word Embeddings.
What are Word Embeddings?
Word embeddings are a method of representing words and documents through numerical vectors. They represent text in a numerical, n-dimensional space where words with similar meanings are represented by similar vectors that are close together. These embeddings are crucial for solving many natural language processing tasks.
Embeddings convert large, sparse vectors into a smaller, dense representation that maintains semantic relationships:
- The issue of sparsity in bag of words is addressed by reducing high-dimensional data to a lower dimension.
- The lack of meaningful relationships in bag of words is resolved by having vectors of semantically related items close to each other. This way, words with similar meanings have similar distances in the vector space.
| Programming Online Courses and Certification | Python Online Courses and Certifications |
| Data Science Online Courses and Certifications | Machine Learning Online Courses and Certifications |
Why do we need Word Embeddings?
The use of word embeddings allows words with similar meanings to be grouped together in a lower-dimensional vector space. For instance, the words that are closest in meaning to the word “fish” would include “whale,” “shark,” and “cod.” This means that if a classifier only sees the word “fish” during training, it will not be misled when it encounters “cod” during testing, as the vector representations of these words are similar.
Furthermore, word embeddings can capture relationships between words, as the difference between the vectors of two words can be combined with another word vector to find a related word. For instance, “lord” – “lady” + “queen” ≈ “king”.
Now, we will be discussing the different approaches to getting Word Embeddings:
Word2Vec
Word2vec is one of the most popular methods for generating word embeddings. It was developed in 2013 by Tomas Mikolov and others at Google, to make the training of neural network-based embeddings more efficient.
Word2Vec transforms words into numerical representations in a vector space, with similar words placed near each other and dissimilar words separated. This is achieved by considering the semantic relationship between words. Additionally, Word2Vec considers the linguistic context of words within a sentence. The surrounding words provide crucial context for understanding the meaning of a particular word, much like in human communication.
For example, a sentence like “The girl was working at the cafe ” may convey one meaning, but with added context such as “The girl had better wi-fi connectivity at the café,” the interpretation changes to reflect the additional information.
Word2Vec is a combination of two neural network-based variants:
Continuous-Bag-Of-Words model (CBOW)
The CBOW model the context of surrounding words to predict a target word.
For instance, let’s look at the following sentence:
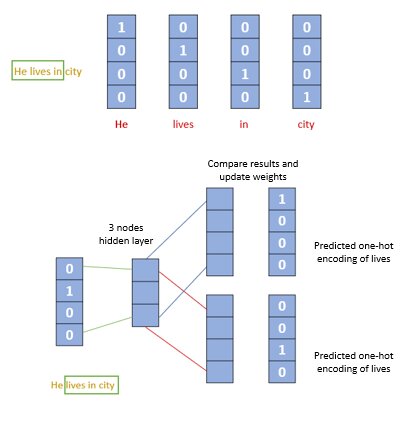
He lives in city.
In this example, the context words would be “He” and “in”, and the target word would be “lives”. The model will predict the probability of the target word “lives” given the context words “He” and “in”.
Note that this is just a simple example, and the model can be applied to multiple context words and a group of target words, but for clarity, this scenario uses only a small example with four words in one sentence.

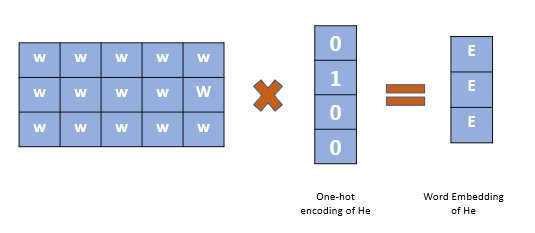
As you can see from the pictorial representation above, we first convert each word into a one-hot encoding form. Note that we are not going to consider all the words in the sentence rather only certain words in a window as shown above.
For example, for a window size equal to 3, we only consider three words in a sentence. The objective of the CBOW model is to predict a target word based on its surrounding context words. During training, the neural network receives a sliding window of two context words and tries to predict the middle word. This process is repeated multiple times until the network is well trained.
The end result of training is a set of weights that can be used to generate word embeddings. The embeddings capture the relationships between words and can be used for various NLP tasks, such as semantic analysis and recommendation systems.
Usually, the considered window size is of 8-10 words and vector size is 300.
| Recursion Function in Python | count() Function in Python |
| len() Function in Python | float() Function in Python |
| range() Function in Python | lambda() Function in Python |
Continuous Skip-gram model
The Skip-gram architecture operates in an inverse manner compared to CBOW. It predicts the context words based on a central target word. The process and neural network structure are comparable to CBOW, with the exception of the way the weight matrix is generated.
Once the weight matrix is obtained, the steps to get word embedding are the same as in CBOW.
So now, which of the two algorithms should be used for implementing word2vec?
The Continuous Skip-gram model is a shallow neural network that predicts surrounding words based on the current word, while the CBOW predicts the current word based on its surrounding context.
CBOW is faster and performs better in representation of common words, while the Skip-gram is better suited for capturing rare words and phrases. Both of these models rely on the usage of surrounding words in order to learn and provide more accurate word embeddings. This learning method consumes less space and computational time, making it feasible to generate embeddings from large text corpora containing billions of words.
Both variants of Word2Vec leverage the context of surrounding words to drive the learning process, resulting in improved word embedding with reduced storage and computational requirements. This enables the creation of embeddings for massive text corpora, even billions of words in size.
GLoVe (Global Vectors for Word Representation)
GloVe is another algorithm that enhances the work of Word2Vec by incorporating global contextual information in a text corpus. Unlike Word2Vec, which only considers the local context of words, GloVe takes into account the entire corpus and creates a co-occurrence matrix to capture the relationships between words.
The GloVe approach combines the benefits of matrix factorization and the local context window method used in Skip-gram. It also has a simpler cost function, reducing the computational burden of training the model and resulting in improved word embeddings.
GloVe performs exceptionally well in word analogy and named entity recognition tasks and is superior to Word2Vec in some cases, while in others it performs similarly. Both techniques are effective in capturing semantic information in a corpus.
Endnotes
In this article, we learnt about word Embeddings and how Word2Vec is a popular and widely used method in Natural Language Processing to generate word embeddings. Hope this article was useful to you.
Explore our articles to find out more about natural language processing and consolidate your knowledge of the fundamentals.
Contributed By: Prerna Singh
Top Trending Article
Top Online Python Compiler | How to Check if a Python String is Palindrome | Feature Selection Technique | Conditional Statement in Python | How to Find Armstrong Number in Python | Data Types in Python | How to Find Second Occurrence of Sub-String in Python String | For Loop in Python |Prime Number | Inheritance in Python | Validating Password using Python Regex | Python List |Market Basket Analysis in Python | Python Dictionary | Python While Loop | Python Split Function | Rock Paper Scissor Game in Python | Python String | How to Generate Random Number in Python | Python Program to Check Leap Year | Slicing in Python
Interview Questions
Data Science Interview Questions | Machine Learning Interview Questions | Statistics Interview Question | Coding Interview Questions | SQL Interview Questions | SQL Query Interview Questions | Data Engineering Interview Questions | Data Structure Interview Questions | Database Interview Questions | Data Modeling Interview Questions | Deep Learning Interview Questions |

This is a collection of insightful articles from domain experts in the fields of Cloud Computing, DevOps, AWS, Data Science, Machine Learning, AI, and Natural Language Processing. The range of topics caters to upski... Read Full Bio