
Random Forest Algorithm: Python Code
This blog will explain you about random forest in machine learning with bagging and boosting techniques

In the list of supervised algorithms, we always talk about the random forest algorithm.
The Random forest algorithm is a machine learning algorithm that has the capability of reducing the variance, enhancing the out-of-sample accuracy, and improving model stability. It does this by creating multiple decision trees. For each tree in a forest, it starts with a bootstrap sample of the data. The algorithm then randomly selects variables to create splits at each node and uses voting among the trees to make predictions.
We will give brief details on ensemble learning techniques(bagging and boosting) in this blog about Random Forest Algorithm!! These topics are very important from an interview point of view also.
We urge you to read about machine learning too.
Let’s get started!!!
Table of contents
- What is a Random forest?
- How does Random Forest work?
- Ensemble learning techniques
- Real-life analogy
- Random forest python
- Assignment
- Endnotes
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses

What is a Random Forest?
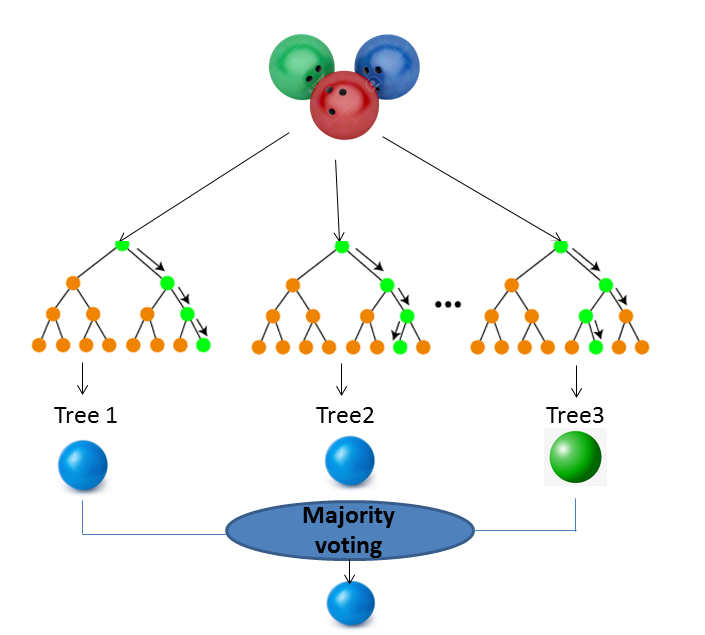
A random forest is a supervised machine learning algorithm used to solve regression and classification problems. As the name forest suggest multiple trees, in the same way random forest also have multiple trees. More trees mean a more robust forest. Different decision trees are created on data samples and the prediction from each of them is collected and the final decision is selected by means of voting. Random forest eliminates the drawbacks of decision trees by reducing the overfitting of datasets and increasing precision.
This type of technique is called ensemble learning. The motivation behind ensemble learning is the belief that a group of experts working together are more likely to be accurate than individual experts
Summary:
The Random forest algorithm doesn’t rely on single decision tree output, it analyses output from different decision trees and finally gives output on the basis of majority voting.
Real-life Analogy
We also follow the same technique of random forest in our daily life. Be it buying furniture/electronics items, taking admission to a college, going out for a watching movie we ask our friends and family for their opinions and on the basis of it we take our final decision. So the same thing random forest applies also. Suppose a student wants to choose a course after your 10+2, and he is not able to decide which course he should take admission based on his skill set. So he decides to consult various people like his teachers, parents, cousins, degree students, and working people. Finally, after consulting various people he decides to take the most suggested course by most of the people. So random forest works the same. It gives output on the basis of the majority output.
You can also explore:

 Read Later
Read Later

How does Random Forest work?
Before going for random forest working let’s understand briefly ensemble learning because the random forest is based on ensemble learning. Ensemble’s literal meaning is the group. So ensemble learning is a technique for combining outputs of different models. These models are called weak learners. Rather than going for individual trees, different trees make predictions and the output is selected according to majority voting. Or you can say model averaging will be followed. Suppose there are 5 models. Out of which 3 have predicted as YES and 2 have predicted as NO. Then the final predictions will be taken as YES.
NOTE: Majority voting for classification and averaging for regression.
Ensemble learning techniques
Bagging
Bagging, an ensemble technique, is known by the name Bootstrap Aggregation. Bagging chooses a randomized subset from the data set. Then Original Data is randomly selected and is given parallelly to different models(weak learners or base learners) but with replacement. Replacement means there is a high possibility that the data sample could be repeated. This is called row sampling and when this step is done with replacement is called bootstrap. After this, each model is trained for generating results. Then results are combined and majority voting is done to generate the final output. This is known as aggregation.
Boosting
Boosting is an ensemble learning technique that random forest use. Like bagging boosting combines weak learners to get the final outcome. Unlike the bagging process boosting follow the sequential process.In which we have sequential learners where every model learns from the mistakes of the previous model and corrects them as shown in fig.
Boosting techniques
- Gradient Boosting
- AdaBoost algorithm (Adaptive Boosting)
- XGBoost

Understanding these techniques with a real-life analogy
Bagging:
Suppose after interviewing a candidate four interviewers gave their feedback parallelly and three selected the candidate and one rejected it. So we can say that candidate is selected(majority wins!!). So this will follow the bagging technique.
Boosting:
But if the first interviewer is giving his outcome and forwarding the feedback to the second interviewer and the second interviewer learning from the feedback of the first interviewer and so on.
Pros of Random forest Algorithm
- The random forest algorithm can be used to solve both classification and regression problems.
- The performance of a random forest algorithm is better than other algorithms on small datasets which may contain outliers.
- Random Forest also has low variance which means that it usually generates similar predictions for different instances (samples) from the same class.
Cons of Random Forest Algorithm
- The random forest algorithm suffers from overfitting
- It is computationally expensive. It can take up to 100 times more computation time than gradient-boosted trees (GBT) when it comes to the training process.
Random forest python
Now comes the fun part!! Now we are going to turn the conceptual knowledge into python code.
About dataset
The dataset used in this is ‘titanic.csv’ which is available for free, which is available on Kaggle.com. This dataset includes the following features
1. Importing Libraries and reading dataset
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns df = pd.read_csv("titanic.csv") df

2. Data preprocessing
df.drop(['Cabin','PassengerId','Name','Ticket’],axis=1,inplace=True) df = df.fillna(0)
For a better understanding of data preprocessing you can check my blogs


3. Handling categorical data
from sklearn.preprocessing import LabelEncoder le=LabelEncoder() df['Sex']=le.fit_transform(df['Sex']) df['Embarked']=le.fit_transform(df['Embarked']) df
4. Dependent and independent variables
# Putting feature variable to X X = df.drop('Survived',axis=1) # Putting response variable to y y = df['Survived']
5. Splitting dataset into Training and Testing Set
# Splitting the data into train and test from sklearn.model_selection import train_test_split # Splitting the data into train and test X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=42)
Next, split both x and y into training and testing sets with the help of the train_test_split() function. In this training data set is 0.8 which means 80%.
6. Implementing a Random forest classifier
#Import Random Forest Model from sklearn.ensemble import RandomForestClassifier #Create a Gaussian Classifier clf=RandomForestClassifier(n_estimators=100) #Train the model using the training sets y_pred=clf.predict(X_test) clf.fit(X_train,y_train)
Different parameters are used in the Random forest algorithm
- N_estimators-The number of decision trees in the forest.
Note: The default value is 100. You can increase the number of trees that can increase the accuracy but be careful that should not lead to overfitting
- criterion{“gini”, “entropy”}, default=”gini”
This is to measure the quality of a split. These are the criterion by which the decision tree actually split the variables.
- “gini” for the Gini impurity
- “entropy” for the information gain
- Max_depth int, default=None
The maximum depth of the tree(root node to terminal node).
Note: If you are using a high value that means you are overcomplicating the things and that can lead to overfitting. So be careful while choosing the value.
- min_samples_split(int or float, default=2)
The minimum number of samples actually required to split an internal node:
Remember the lower the value the higher the chance to fit errors but that doesn’t mean you choose a very high value because that will over generalize the model leading to overfitting. So choose value accordingly.
- min_samples_leaf(int or float, default=1)
The minimum number of samples is required to be at a leaf node.
- Max_features {“auto”, “sqrt”, “log2”}, int or float, default=”auto”
a maximum number of features random forest considers when looking for the best split.
- n_jobs(int, default=None)
It is the number of jobs to run in parallel. This is used when you have the capability to do parallel processing where n_jobs= -1 means using all processors and n_jobs=1, it can use only one processor
- random_state(int, RandomState instance or None, default=None)
It Controls both the randomness of the samples used when building trees.
- verbose(int, default=0)
Controls the verbosity when fitting and predicting. It gives you all the run-time information.
You can hyper-tune these by changing the values. You can read my blog on hyper-tuning.
7. Predicting test cases using random forest
# Predicting the test set results Pred = classifier.predict(X_test) print(Pred)
Output:
[0 1 1 0 1 1 1 0 0 0 1 0 1 0 1 1 1 0 0 0 1 0 1 1 1 1 1 1 0 1 0 0 0 0 1 0 1
1 1 1 1 1 1 1 1 0 1 1 0 0 0 0 1 1 0 0 0 1 0 0 0 1 0 1 1 0 0 1 1 1 1 1 1 1
0 1 1 0 0 0 1 0 1 1 0 0 0 1 0 0 1]
8. Checking the accuracy score
from sklearn.metrics import classification_report rand_score=classifier.score(X_test, y_test) '''rand_score=classifier.accuracy_score(y_test,Pred)''' classification_report_rf=classification_report(y_test,Pred) print("Accuracy score:",rand_score)
Output:
Accuracy score: 0.8268156424581006
Assignment
It’s my suggestion to you to implement this code yourself.
- You can implement the Random forest algorithm on some other dataset and see its performance
Tip- You can use a dataset where data preprocessing is required and practice that!!
- Apply hyperparameter tuning process as random forest have a lot of parameters
For more understanding of hyperparameter tuning and data pre-processing, you can follow my previous blogs.
Endnotes
Congrats!!! On making it to the end. By now you must be knowing the basics about the random forest with its implementation.
Now, it can be concluded that Random Forest is one of the best techniques for giving high performance. It can handle missing values.
Overall, the Random forest algorithm is a simple, fast, flexible, and robust model with some limitations. If you liked the blog please share it with other people also.
Happy learning!!!
Top Trending Articles:
Data Analyst Interview Questions | Data Science Interview Questions | Machine Learning Applications | Big Data vs Machine Learning | Data Scientist vs Data Analyst | How to Become a Data Analyst | Data Science vs. Big Data vs. Data Analytics | What is Data Science | What is a Data Scientist | What is Data Analyst
FAQs
What is random forest?
A random forest is a kind of ensemble learning method for classification, regression, and other tasks. Random forest works by creating many decision trees in one training session. It works by averaging multiple decision trees over different parts of the same training set.
How are random forests related to decision trees?
Random forest is an ensemble learning technique that works by building different decision trees. Random forests can be created for both classification and regression tasks. Random forests outperform decision trees and are not prone to overfitting data like decision trees. A decision tree trained on a given dataset will be very deep, causing overfitting. To create a random forest, you can train decision trees on different subsets of the training data set and average the different decision trees to reduce variance.
Explain the advantages of using Random Forest
1. Random forests are very versatile and can be used for both regression and classification tasks. 2. It can also handle all binary, categorical, and numeric functions. Processes are parallelizable and can be split up and run on different machines. 3. It works better in higher dimensions because the work is done on a subset of the data. 4. Training speed is faster than decision trees because decision trees only work on a subset of features. 5. Even with hundreds of functions, the training speed is significantly faster. 6. Random forests are good for smoothing errors in datasets with imbalanced class populations.

This is a collection of insightful articles from domain experts in the fields of Cloud Computing, DevOps, AWS, Data Science, Machine Learning, AI, and Natural Language Processing. The range of topics caters to upski... Read Full Bio