
Steps to Create Your Own Machine Learning Models
Machine learning involves a series of techniques that allow computer systems to predict, classify, order, make decisions and, in general, extract knowledge from the data without the need to explicitly define the rules to perform these tasks. It is a subfield of artificial intelligence that aims to teach computers the ability to perform example-based tasks without explicit programming. Due to the continuous growth in business complexity and the amount of data to be analyzed, we are moving from rules-based to data-based intelligence, and the primary step involves creating machine learning models to achieve the desired results.

To learn about machine learning, read our blog – What is machine learning?
Applications of Machine Learning Models
before we head to the steps involved in creating a machine learning model, let’s check out the most popular applications of these models.
| Model | Applications |
| Bayesian Classifiers | Spam and noise filtering |
| Convolutional Neural Networks | Image processing |
| Fully connected networks | Classification |
| Generative Models | Image creation |
| K-means | Segmentation |
| k-Nearest Neighbors | Recommendation systems |
| Logistic Regression | Prediction of costs |
| Random Forest | Fraud Detection |
| Recurrent Neural Networks | Voice recognition |
| Reinforcement Learning | Learning by trial and error |
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses

Understand the Problem
Before taking the first step, you need to understand the problem you wish to solve. Understanding the problem accurately takes a lot of time, especially if the problem comes from an industry you have no or very little idea about. A good approach will be to collaborate with people who know a lot about the problem.
It is common to do an exploratory data analysis to familiarize ourselves with them. In exploratory data analysis, graphs, correlations, and descriptive statistics are created used to better understand what story the data is telling us. It also helps to estimate if the data we have is sufficient and relevant.
Must Read – Statistical Methods Every Data Scientist Should Know
Steps to Create a Machine Learning Model
Lets check the steps involved in creating machine learning models –
Define Evaluation Criteria
Imagine that we obtain a perfect machine learning model … how would we know? The evaluation criterion is normally a measure of error. The mean square error is typically used for regression problems and cross-entropy for classification problems. For classification problems with two classes, we can use other measures such as precision and completeness.
Also Read – An Introduction to Different Methods of Clustering In Machine Learning
Collect the Data
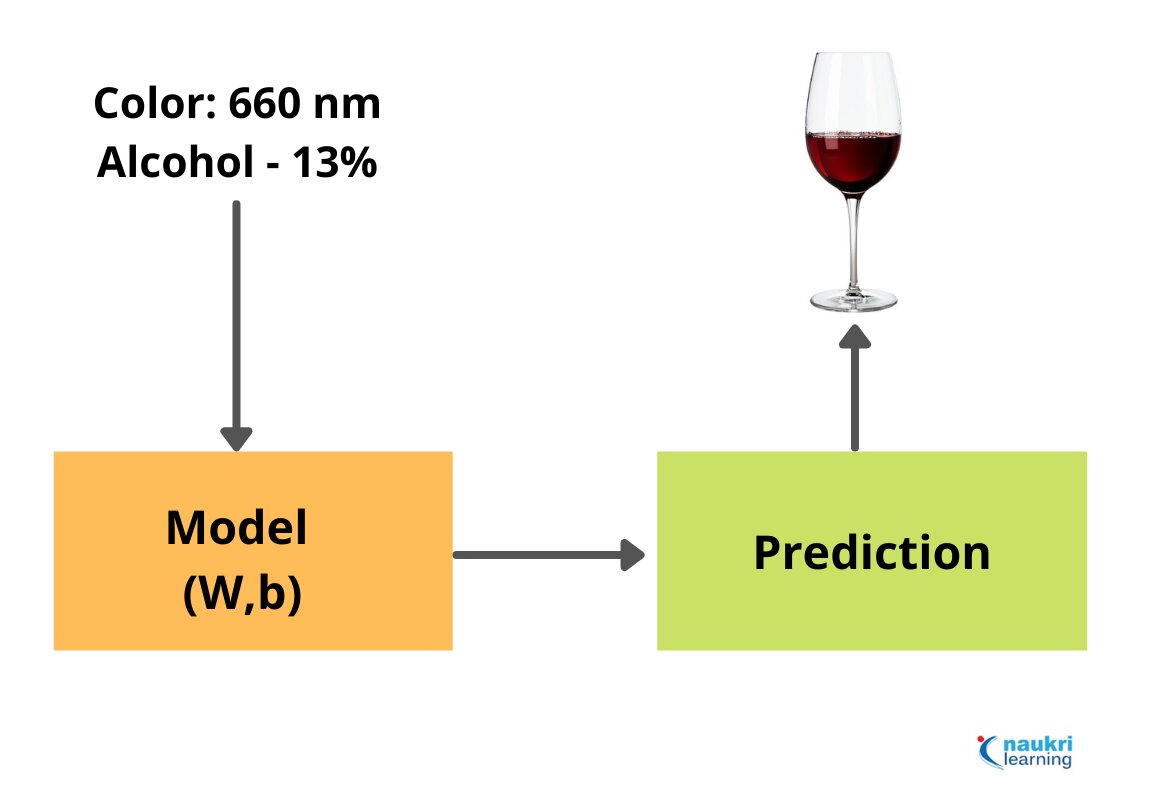
Once you understand the problem you will be targeting, investigate the data and pick the relevant information to feed your machine. The quality and quantity of information directly affect the outcomes, whether good or bad. Take this example of training data. The data collected will be color and alcohol content in each beverage.
| Color (nm) | Alcohol (%) | Wine or Beer |
| 610 | 6 | Beer |
| 599 | 14 | Wine |
| 693 | 15 | Wine |
If it is a small project of creating machine learning models, you can create a spreadsheet that can be easily exported as a CSV file. Another option is to use the web-scraping technique to automatically collect information from various sources.
Prepare the Data
Machine learning algorithms work much better if we offer you relevant features instead of raw data. For example, it is much easier for us to know the temperature in degrees Celsius than to know how much so many milligrams of mercury have expanded in a traditional thermometer. In the same way, it is very useful to transform the data to make the learning task easier. We must have the amount of data balanced so that we have for each result (class), so that it is representative, since if not, the learning may be biased towards a type of response and when our model tries to generalize the knowledge it will fail.
The data can be divided into two groups – one for training and another for model evaluation. We can divide the data in a ratio of 80:20, however, but it can vary according to the case and the volume of data that we have.
Read our blog to understand how data preprocessing is done in the data mining process.
Choose the Model
The phase of building a machine learning model is surprisingly shorter, once we have the data ready. This happens because there are already several machine learning libraries and techniques available. The machine learning algorithm will automatically learn to obtain the appropriate results with the historical data that we have prepared.
We can use different methodologies basis our objective. For example, we can use machine learning algorithms for classification, prediction, linear regression, clustering, deep learning, etc.
Analyze the Error
The error analysis phase requires a medium relative effort. Analyzing errors is important to understand what we have to do to improve machine learning results. You can –
- Use a more complex model
- Use a simpler model
- Figure out if you need more data and/or information
- Develop a better understanding of the problem and think about the next step
In the error analysis phase, we try to ensure that our model is capable of generalization. Generalization is the ability of machine learning models to produce good results when using new data.
Must Read – Top 10 Machine Learning Algorithms for Beginners
Train the Model
Training data is then used to run the machine and mark any incremental improvement (for prediction). It takes a great effort to build data interfaces so that the model can obtain data automatically and the machine can use its prediction automatically. This helps to separate the wine and beer systematically and accurately.

In this phase, we need to –
- Repeat data preparation phases
- Ensure that the machine learning model is able to communicate with other parts of the system
- The system uses the results
- Automatically monitor the errors in the model and keep removing them
- Rebuild the machine learning model using accurate data
Evaluate
After you have trained your machine and created the desired machine learning models, we need to check the created models against our set of parameters to evaluate them. If the accuracy of the model is less than or equal to 50%, the model isn’t very useful. It can be called a good machine learning model if it reaches an accuracy of 90% or higher.
Conclusion
In-depth analysis, also known as modeling applies the information obtained in the previous phases to define, train, select and execute the machine learning models and thus obtain the business responses. Always remember that the goal is not to create a wonderful machine learning model, but to solve a real and concrete business problem by harnessing the potential offered by the use of data and digital innovations.
If you have recently completed a professional course/certification, click here to submit a review.

Rashmi is a postgraduate in Biotechnology with a flair for research-oriented work and has an experience of over 13 years in content creation and social media handling. She has a diversified writing portfolio and aim... Read Full Bio