
Supervised Learning in Action: Real-World Applications and Examples
Supervised learning is a type of machine learning where a model is trained to make predictions based on labeled data. The model is given input data and the corresponding correct output, and it learns to predict the output for new data based on this training. This allows the model to perform tasks such as classification and regression.

Supervised learning is a way that we can teach computers to do things by showing them examples and telling them the right answer. For example, let’s say we want to teach a computer to recognize pictures of dogs. We can show it pictures of different breeds of dogs and tell it the name of each breed. Then the computer will try to figure out which characteristics typically go with each breed of dog.
Once the computer has learned enough about different breeds of dogs, we can test it by showing it a picture of a dog it has never seen before. The computer will use what it has learned to try to guess which breed of dog it is. If it guesses correctly, we can say that the computer did a good job of learning about dogs. If it doesn’t guess correctly, we can give it more examples to help it learn even better.
We use supervised learning algorithms widely for many tasks, including predicting a discrete label with classification, predicting a continuous value with regression, and predicting future events based on past data with time series forecasting. Some common examples of supervised learning include spam filters, fraud detection systems, recommendation engines, and image recognition systems.
Table of contents
- What is Supervised Learning?
- How does supervised learning work?
- Supervised Learning Algorithm
- Types of supervised Machine learning Algorithms
- Application of supervised Learning
- Advantages of supervised Learning
- Disadvantages of supervised Learning
- Conclusion
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses

What is Supervised Learning?
Supervised learning is a type of machine learning in which a model is trained on labeled data, where the input data is paired with the correct output labels. Supervised learning algorithms learn by analyzing a large dataset of labeled examples and adjusting the parameters of the model in order to minimize the error between the model’s predictions and the correct output labels. Once the model has been trained, it can be used to make predictions on new, unseen data.
One way to think about supervised learning is to compare it to a student learning from a teacher. In this analogy, the teacher is the labeled data, and the student is the machine learning model. The teacher provides the student with examples of the correct answer (the output label) along with the corresponding input data (e.g. a math problem and the correct solution). The student uses this information to learn how to solve similar problems on their own.
Once the student has learned from the teacher, they can use their knowledge to solve new problems (make predictions on new, unseen data). The teacher can also evaluate the student’s performance by testing them on problems they haven’t seen before (testing the model on a separate dataset). If the student’s performance is satisfactory, they can be considered ready to solve similar problems on their own.
Supervised learning is a type of machine learning in which a model is trained on labeled data in order to learn how to make predictions based on the patterns and relationships in the data.

 Read Later
Read Later

Learn more: Difference between Supervised and Unsupervised Learning
You can also explore – What is the Future of Machine Learning?
Also explore: Introduction to Semi-supervised Learning
How does Supervised Learning work?
Here is a summary of how supervised learning works:
- Gather a dataset of labeled examples: The first step in supervised learning is to gather a dataset of labeled examples that the model will be trained on. The examples should be representative of the problem at hand and should include both the input data and the correct output labels.
- Preprocess the data: Next, the data may need to be preprocessed in order to prepare it for use in a machine learning model. This may include tasks such as cleaning the data, filling in missing values, or normalizing the data.
- Train the model: Once the data is prepared, the model can be trained on it. This involves using an optimization algorithm to adjust the parameters of the model in order to minimize the error between the model’s predictions and the correct output labels.
- Test the model: After the model is trained, it can be tested on a separate dataset to evaluate its performance. The model’s accuracy can be measured using metrics such as precision, recall, and F1 score.
- Use the model to make predictions: Once the model has been trained and tested, it can be used to make predictions on new, unseen data. The model will use the patterns and relationships learned during training to make predictions based on the input data.
Supervised learning is a straightforward process that involves training a model on a labeled dataset and using the model to make predictions based on the patterns and relationships learned during training.
Also read: How to improve machine learning model
Also read: Evaluating a machine learning algorithm
Explore: ROC-AUC vs Accuracy: Which Metric Is More Important?
Supervised Machine Learning Example
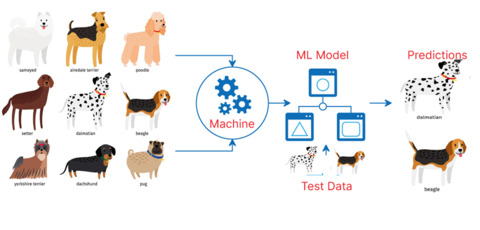
In this example, we are using a machine learning model to learn about different breeds of dogs. We have a list of dogs with their breed names, and we use this information to teach the model. The model tries to figure out which characteristics are typically associated with each breed of dog. After the model has learned enough, it can guess which breed a dog belongs to, even if it has never seen that specific dog before.
Also explore: Machine learning courses
Also explore:Top 10 Free Machine Learning Courses to Take Up in 2022
Also, explore: Top 10 concepts and technologies in machine learning
Supervised Learning Algorithm
It mainly deals with two powerful algorithms for Classification and Regression Models. Some of the famous classification and regression algorithms are:
- Linear Regression
- Logistic Regression
- Decision Tree Classification
- Random Forest Classification
- Naive Bayes Classifier
- Support Vector Machine (SVM)
- K – Nearest Neighbor (KNN)
Also Read:
- Applications of AI and Machine Learning in Education
- How can machine Learning help save lives in the healthcare sector?
Types of Supervised Machine learning Algorithms

1. Regression
Regression is a type of machine learning task that is used to predict a continuous value, such as a numerical or a probability. It is a supervised learning task, which means that the model is trained on a dataset of labeled examples, where the input data is paired with the correct output labels.
Here is an example of a regression task:
Imagine that you want to predict the price of a house based on its size, location, and other features. You could use a regression model to make this prediction. To do so, you would need to gather a dataset of houses that includes the size, location, and other features of the houses as well as their sale prices. You would then use this dataset to train a regression model.
Once the model is trained, you can use it to make predictions about the price of a new house based on its size, location, and other features. For example, if you input the size, location, and other features of a house into the model, it will output a predicted price for the house.
Regression models can be used to solve a wide range of problems, including predicting the likelihood of an event occurring, forecasting time series data, and more. They are particularly useful for tasks where it is important to predict a continuous value with a high degree of accuracy.
Here are a few more examples of regression tasks:
- Predicting the demand for a product based on historical sales data
- Forecasting the stock price of a company based on financial data
- Predicting the likelihood of a customer defaulting on a loan based on their credit history
- Estimating the life expectancy of a patient based on their medical history and other factors
- Predicting the fuel efficiency of a car based on its engine size and other features
- Determining how much a customer is willing to pay for a particular product based on age.
2. Classification
Classification algorithms are used when the output variable is categorical. This means there are two classes: yes-no, male-
Classification is a type of machine learning task that involves predicting a discrete label based on input data. For example, a classification model might be trained to predict whether an email is spam or not spam, based on the contents of the email.
Here is an example of how a classification model might work:
Imagine that you want to build a model to predict whether a customer will churn (cancel their subscription) based on their activity on your platform. You could use a classification model to make this prediction.
To do so, you would need to gather a dataset of labeled examples that includes information about the customer’s activity on your platform (e.g. number of logins, amount of time spent on the platform, etc.) as well as a label indicating whether or not the customer churned. You would then use this dataset to train a classification model.
Once the model is trained, you can use it to predict whether a new customer is likely to churn based on their activity on your platform. For example, if you input the activity of a new customer into the model, it will output a prediction of whether the customer is likely to churn or not.
Here are a few more examples of classification tasks:
- Predicting the type of a given plant based on its features (e.g. flower color, leaf shape, etc.)
- Predicting the sentiment of a given tweet based on its text (e.g. positive, negative, or neutral)
- Predicting whether a given image contains a cat or a dog
- Predicting the likelihood of a patient having a certain disease based on their medical history and other factors
- Predicting the type of a given star based on its characteristics (e.g. red giant, white dwarf, etc.)



Application of Supervised Learning
There are many examples of supervised learning being used in everyday life. Here are a few examples:
- Spam filters: Many email clients use supervised learning algorithms to filter out spam emails. The algorithms are trained on a dataset of labeled emails (spam and non-spam) and use this information to predict whether a new email is spam or not.
- Fraud detection: Many financial institutions use supervised learning algorithms to identify fraudulent activity. The algorithms are trained on a dataset of labeled transactions (fraudulent and non-fraudulent) and use this information to flag potentially fraudulent transactions in real-time.
- Recommendation systems: Many online platforms, such as Netflix and Amazon, use supervised learning algorithms to make recommendations to users based on their past activity. The algorithms are trained on a dataset of user behavior (e.g. which movies or products a user has watched or purchased) and use this information to suggest similar movies or products to the user.
- Speech recognition: Many voice assistants, such as Apple’s Siri and Amazon’s Alexa, use supervised learning algorithms to process and interpret spoken commands. The algorithms are trained on a dataset of labeled speech data (transcribed speech and the corresponding text) and use this information to transcribe and interpret spoken commands.
- Image classification: Many image recognition systems, such as those used by social media platforms to automatically tag photos, use supervised learning algorithms to classify images based on their content. The algorithms are trained on a dataset of labeled images (e.g. images of cats and dogs) and use this information to classify new images.
Advantages of supervised Learning
Supervised learning has several advantages, let us explore some of them:
- Used to solve a wide range of problems: Supervised learning can be used for both classification tasks (predicting a discrete label) and regression tasks (predicting a continuous value). This makes it a versatile tool for solving a wide range of problems.
- Learn from small amounts of data: Supervised learning algorithms can learn from small amounts of data, as long as the data is representative of the problem at hand. This makes it an effective approach for problems where it is difficult or expensive to gather large amounts of data.
- Make accurate predictions: Supervised learning algorithms can make highly accurate predictions when trained on high-quality data. This makes it a useful tool for tasks where accuracy is important, such as fraud detection or medical diagnosis.
- Easy to understand and interpret: Supervised learning algorithms are generally easy to understand and interpret, as they make predictions based on a clear set of input-output pairs. This makes them a good choice for tasks where it is important to understand how the model is making predictions.
Disadvantages of supervised Learning
While supervised learning has many advantages, it also has some disadvantages:
- Requires labeled data: In order to train a supervised learning model, you need a large dataset of labeled examples. This can be time-consuming and expensive to gather, especially for tasks where it is difficult to obtain accurate labels.
- Susceptible to bias: Supervised learning algorithms can be biased if the training data is not representative of the overall population. For example, if a model is trained on a dataset that is predominantly male, it may not perform well on a dataset that is predominantly female.
- May not generalize well to new data: Supervised learning algorithms are trained to make predictions based on patterns and relationships in the training data. If the test data is significantly different from the training data, the model may not generalize well and may make inaccurate predictions.
- May require extensive feature engineering: In order to get good results with supervised learning, it is often necessary to carefully design and select the features that are used as input to the model. This can be a time-consuming and labor-intensive process.
While supervised learning is a widely-used approach for solving many problems, it is important to carefully consider its limitations and potential biases when applying it to real-world problems.
Conclusion
Supervised learning is a powerful method for solving different machine learning tasks. It involves training a model on labeled data in order to make accurate predictions based on patterns and relationships in the data. Although it has some limitations, such as the need for a large dataset of labeled examples, it is likely to continue to play a major role in the field of artificial intelligence.

Experienced AI and Machine Learning content creator with a passion for using data to solve real-world challenges. I specialize in Python, SQL, NLP, and Data Visualization. My goal is to make data science engaging an... Read Full Bio