
Text Classification with BERT
Fine-tune a pre-trained BERT model on labeled data for text classification tasks. BERT has achieved state-of-the-art results and is useful for NLP tasks.

BERT (Bidirectional Encoder Representations from Transformers) is a pre-trained language model developed by Google. It is a transformer-based model that can be fine-tuned for a wide range of natural language processing tasks, such as sentiment analysis, question answering, and language translation.
One of the key features of BERT is its bidirectional nature. Unlike traditional language models, which process the input text in a left-to-right or right-to-left manner, BERT processes the input text in both directions, taking into account the context of the words before and after a given word. This allows BERT to capture more contextual information and improve performance on a wide range of tasks.
BERT has achieved state-of-the-art performance on a number of natural language processing benchmarks and is widely used in industry and academia. It has been pre-trained on a large corpus of text data and can be fine-tuned for specific tasks using a small amount of labeled data.
How does BERT work?
BERT is based on the transformer architecture, which uses self-attention mechanisms to process the input data. The transformer takes in a sequence of input tokens (such as words or sub-words in a sentence) and produces a sequence of output tokens (also known as embeddings).
One of the key features of BERT is its bidirectional nature. Unlike traditional language models, which process the input text in a left-to-right or right-to-left manner, BERT processes the input text in both directions, taking into account the context of the words before and after a given word. This allows BERT to capture more contextual information and improve performance on a wide range of tasks.
BERT uses a multi-layer transformer encoder to process the input data. The input tokens are first embedded using a token embedding layer, and then passed through the transformer encoder. The transformer encoder consists of multiple self-attention layers, which allow the model to attend to different parts of the input sequence and capture long-range dependencies. The output of the transformer encoder is a sequence of contextualized token embeddings, which capture the meaning of the input tokens in the context of the entire input sequence.
BERT has been pre-trained on a large corpus of text data and can be fine-tuned for specific tasks using a small amount of labeled data. This allows the model to be used for a wide range of natural language processing tasks with minimal task-specific training data.
Best-suited NLP and Text Mining courses for you
Learn NLP and Text Mining with these high-rated online courses

Model Architecture of BERT
The model architecture of BERT consists of the following components:
- Token embedding layer: The input tokens (such as words or sub words in a sentence) are first embedded using a token embedding layer. This layer maps each token to a high-dimensional embedding vector, which captures the meaning of the token.
- Transformer encoder: The input token embeddings are then passed through a multi-layer transformer encoder. The transformer encoder consists of multiple self-attention layers, which allow the model to attend to different parts of the input sequence and capture long-range dependencies.
- Output layer: The output of the transformer encoder is a sequence of contextualized token embeddings, which capture the meaning of the input tokens in the context of the entire input sequence. The output layer is responsible for making the final prediction for the task at hand, such as classifying the sentiment of a sentence or answering a question.
BERT is a transformer-based model that is trained using a variant of the masked language modeling objective. During training, a portion of the input tokens are randomly masked, and the model is trained to predict the masked tokens based on the context provided by the unmasked tokens. This allows the model to learn the relationships between the words in a sentence and their meaning in the context of the entire input sequence.
After training, BERT can be fine-tuned for specific tasks using a small amount of labeled data. This allows the model to be used for a wide range of natural language processing tasks with minimal task-specific training data.
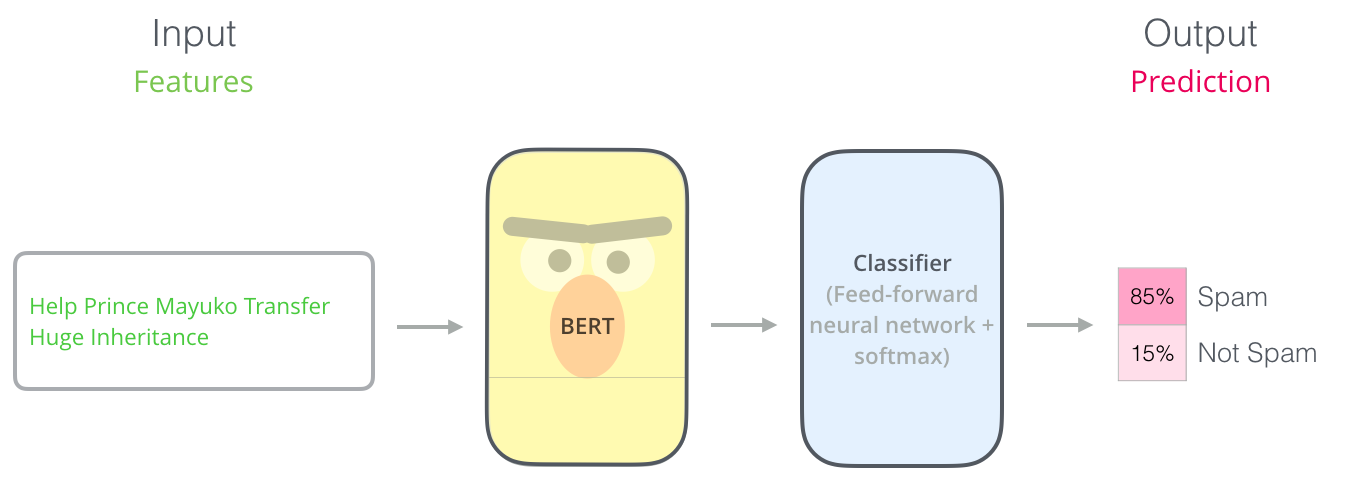
Text Classification using BERT
BERT can be used for text classification tasks by fine-tuning the pre-trained model on a labeled dataset. Here is a general outline of the process:
- Preprocess the text data: This may include tasks such as lowercasing, tokenization, and removing stop words.
- Convert the text data into numerical input features: BERT operates on numerical input data, so it is necessary to convert the text data into numerical form. This can be done using techniques such as word embeddings or sentence embeddings.
- Load the pre-trained BERT model and add a classification layer: The BERT model can be loaded from a checkpoint and a classification layer can be added on top of it. The classification layer will be responsible for making the final prediction.
- Fine-tune the model on the labeled dataset: The model can be fine-tuned by adjusting the weights of the classification layer and the pre-trained layers using gradient descent. This can be done using a small labeled dataset and a labeled text classification dataset.
- Evaluate the model on a test set: After fine-tuning, the model can be evaluated on a test set to assess its performance. Performance metrics, such as accuracy and the F1 score, can be used to measure the model’s performance.
BERT can be fine-tuned for text classification tasks using a small labeled dataset and has achieved state-of-the-art performance on a number of benchmarks.
Implementation of Text Classification using BERT
Here is an example of how to perform text classification with BERT in Python using the transformers library:
# install the transformers library!pip install transformers
# import the necessary librariesimport torchfrom transformers import BertTokenizer, BertForSequenceClassification
# load the pre-trained BERT model and tokenizermodel = BertForSequenceClassification.from_pretrained('bert-base-uncased')tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# define the input text and convert it to input featurestext = "This is a positive review."input_ids = torch.tensor(tokenizer.encode(text)).unsqueeze(0) # batch size 1
# make the predictionoutput = model(input_ids)prediction = output[0].argmax().item()
# print the predictionprint(f'Prediction: {prediction}')
This example loads the pre-trained BERT model and tokenizer from the ‘bert-base-uncased’ model, converts the input text into input features using the tokenizer, and makes a prediction using the model. The final prediction is a class label, with 0 corresponding to the negative class and 1 corresponding to the positive class.
You can fine-tune the BERT model for text classification by adjusting the weights of the model using gradient descent and a labeled dataset. You can also use other pre-trained models and fine-tune them for text classification tasks.
Conclusion
In conclusion, BERT (Bidirectional Encoder Representations from Transformers) is a powerful tool for text classification tasks. It is a pre-trained language model that has been trained on a large dataset of text, allowing it to capture the context and meaning of words in a way that is useful for natural language processing tasks. BERT can be fine-tuned for a specific text classification task by adding a classification layer on top of the pre-trained model and training it on the task-specific dataset.
One of the key advantages of using BERT for text classification is that it allows for the use of large amounts of unannotated data, which can significantly improve the performance of the model. BERT also has the ability to handle long-range dependencies in text, which is important for many natural language processing tasks.
Overall, BERT has shown to be a very effective tool for text classification and has achieved state-of-the-art results on a number of benchmarks. It is a versatile model that can be fine-tuned for a variety of text classification tasks and is an important tool for natural language processing researchers and practitioners.

Experienced AI and Machine Learning content creator with a passion for using data to solve real-world challenges. I specialize in Python, SQL, NLP, and Data Visualization. My goal is to make data science engaging an... Read Full Bio