
Understanding Transformers: A Beginner’s Guide to the Basics and Applications
This article briefly discusses what transformer is, the architecture of transformer, the working mechanism of encoder and decoder. In the later part we will briefly discuss what is self-attention and its working mechanism with the help of an example.

You know ChatGPT which is a gp transformer. Today we will cover what transformers are. To make it easier for you to understand, we will first take you through NLP, based on which we will explain the architecture and working of transformers. And then, the working mechanism of self-attention.
So, let’s start!!
Table of Content
- What is NLP?
- What is Transformer?
- How do Transformer work?
- Attention and Self-Attention
- Limitation of Transformer
What is NLP?
NLP (or Natural Language Processing) is a branch of Artificial Intelligence and Linguistics that focuses on enabling computers to understand and interpret the language of human beings. It focuses on understanding every single word individually as well as its context.
The goal of the NLP is not just limited to understanding the language of humans but also generating human language meaningfully. It helps to bridge the gap between human communication and computer understanding.
Must Explore – Artificial Intelligence Courses
NLP uses various techniques and algorithms from computer science, linguistics (parts of speech), and machine learning to train itself and generate results. Some of the common examples of NLP include:
- Sentiment Analysis
- Spam Detection
- Chatbots
- Machine Translation
- Voice Assistants
- Text Summarization
ChatGPT and Google Bard are one of the most prominent examples of NLP, which work as chatbots, and generate texts.

 Read Later
Read Later

Now, we will explore the concepts and mechanisms behind these chatbots.
Best-suited Generative AI courses for you
Learn Generative AI with these high-rated online courses

What is a Transformer?
Transformers are a special type of neural network that was first introduced in 2017 by Vaswani et al. in the Research Paper “Attention is All You Need”. And after that, these transformer models became the foundation of many state-of-the-art NLP models. Unlike the traditional Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM), transformers use self-attention that processes the input sequence in parallel, resulting in better scalability and faster training time.
Mainly transformer is made up of two components: Encoder and Decoder. The basic architecture of a Transformer looks like:

Use of Transformers:
- Transformers can be trained to translate text from one language to another (Google Translate).
- It can determine the sentiment or emotion behind the piece of text (Twitter Sentiment Analysis)
- Transformers can generate human-like text on any given input prompt (ChatGPT and Google Bard).



Now, we will discuss the architecture of the Transformer.
Architecture of Transformers
The architecture of Transformers consists of three main components:
Encoder processes input sequences and consists of identical layers. Each layer contains:
- Self-attention mechanism
- Position-Wise Feed-Forward Network
Decoder: It generates the output sequence, and similar to the encoder, it is also composed of identical layers. Each layer contains:
- Mult-Head Self Attention Mechanism
- Positions-Wise Feed-Forward Network
- Encode-Decoder Attention Layer
Position Encoding: It is used to inject information about the tokens. Since the transformers can’t sense the position of tokens in the input sequence.

Image Source: Research Paper: Attention is All You Need



Now, let’s see the working mechanisms of transformer.
How do Transformer work?
Working Mechanism of Encoder
The encoder is composed of a stack of identical layers and each layer contains two sub-layers: Multi-head Self-Attention Mechanism and a Position-Wise Feed-Forward Neural Network.
Additionally, there are residual connections and layer normalization applied after each sub-layer.
Now, let’s understand the working mechanism of the encoder:

Input Embedding
The input sequence is first converted into a continuous vector representation called embedding. These embeddings are created using embedding algorithms.
Positional Encoding
Position encoding is a sinusoidal function of position. It ensures that the model can differentiate between words based on their position in the input sequence.
These positional encodings are important since the architecture of the transformer doesn’t inherently account for the position of words in a sequence, so position encoding is added to the input embeddings.
Multi-Head Self-Attention (MHSA)
Once the input sequence is passed through MHSA, it computes the attention scores for each word in the sequence by comparing it with the other words.
The mechanism of Self-Attention will be explainer later in the article.
Layer Normalization and Residual Connection
The layer is just after the MHSA, where the residual connection is added. At this layer, the output of the MHSA sub-layer is element-wise added to the original input. This helps mitigate the vanishing gradient problem in deep networks.
After the residual connection, layer normalization is applied to normalize the output along the last dimension to stabilize the training application.
Now, here comes the second sub-layer of the stack, i.e., the Position-wise Feed-Forward Network.
Position-wise Feed-Forward Network (FFN)
The output of the layer normalization is passed through FFN, which consists of two layers with the activation function between them. FFN is applied independently to each position in the sequence, which enables models to learn and apply position-specific transformations.
Similar to the MHSA sub-layer, the output of the FFN is added to the input through residual connection and then goes for layer normalization (followed by layer normalization).
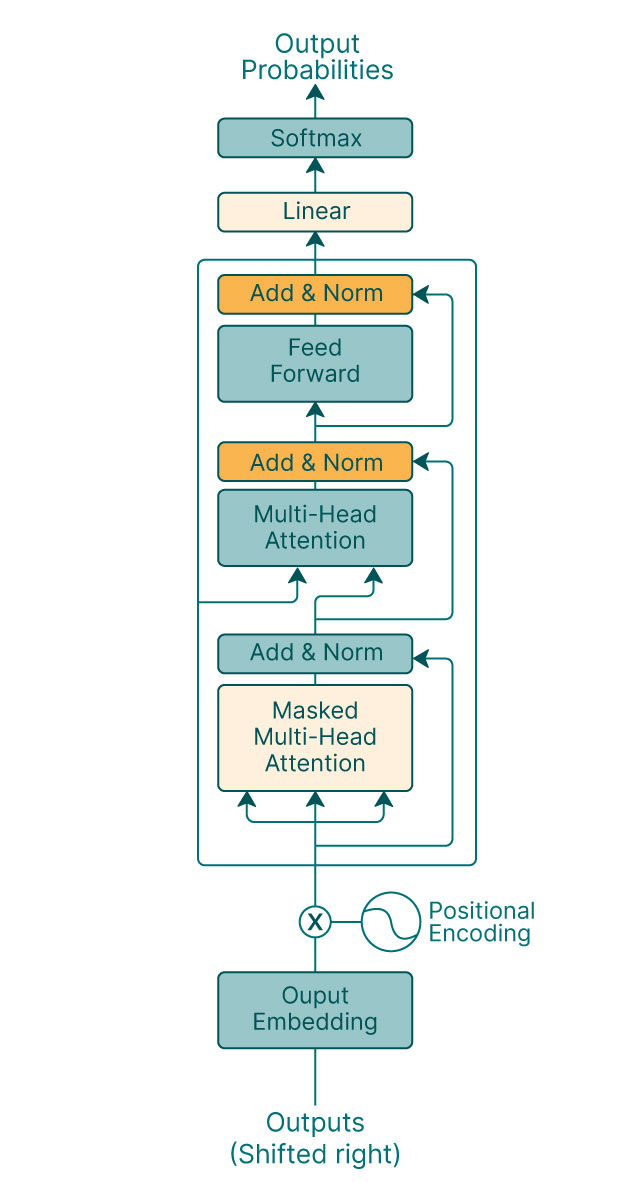
Working Mechanism of Decoder
Decoder processes the contextualized representation generated by the encoder and produces the output sequence. The architecture of the decoder is very similar to the encoder with an extra sub-layer Encoder-Decoder Attention.
Let’s have a look at the architecture of the decoder.
Like the encoder, the decoder is also composed of a stack of identical layers, each containing sub-layers: Multi-Head Self Attention, Encoder-Decoder Attention Mechanism, and Position-wise Feed-Forward Network.
Similar to the encoder, there is residual connection and layer normalization applied after each sub-layer.
Now, let’s understand the working mechanism of the decoder:
The decoder’s steps are very similar to the encoder, so we will not discuss all the steps; we will only discuss the steps and sub-layer that are not present in the encoder.
Encoder-Decoder Attention
It is the sub-layer between self-attention and feed-forward and allows the decoder to focus on relevant parts of the input sequence while generating the output sequence. It is an additional Multi-Head Attention mechanism that attends to the output of the Encoder. The queries come from the previous Decoder layer, while the keys and values come from the Encoder’s output.
Linear Layer and SoftMax
The output of the final Decoder layer is passed through a linear layer that produces logits over the vocabulary. A SoftMax function is then applied to convert the logits into probability distributions for each position in the output sequence. The most probable word is selected as the generated word for that position.
At the start of the article, we mentioned that Transformers, are a special type of neural that was mentioned in the research paper, “Attention is All You Need” and while explaining the working mechanism of encoder and decoder, we mentioned self-attention.
So, in the next section, we will briefly discuss about Attention and Self-Attention and the working mechanism of Self-Attention, with the help of an example.
What is Attention and Self-Attention?
Both attention and self-attention are the mechanisms that allow the transformer model to attend to different parts of the input and output sequences when making predictions.
Self-attention allows a transformer model to attend to different parts of the same input sequence while, the attention model allows a transformer model to attend to different parts of another sequence.
In simple terms, the traditional attention mechanism focuses on the relationship between elements from two different sequences (eg. input and output sequences in a sequence-to-sequence model) whereas, self-attention focuses on the relationship within a single sequence.
Self-attention enables the model to capture the dependencies between elements in the sequence, even if they are far apart.
Now, it’s time to get a brief explanation of the self-attention mechanism that we will use while discussing the architecture of transformers.
Mechanism of Self-Attention
The self-Attention mechanism allows them to interact with each other and determine to whom they should give more priority (or attention). The resulting outputs are aggregates of these interactions and the attention score. It takes n-input and returns n-output.
Now, let’s have a look at the step-by-step mechanism of self-attention.
Step-1: The very first step is to vectorize the input, i.e., converting each input word into the vector using an embedding algorithm
Let’s consider three words:
1. very delicious food, 2. not delicious food, 3. very very delicious food
now, to vectorize here we will use the concept of tokenization
#step - 1: vectorization of words
from sklearn.feature_extraction.text import CountVectorizertext = ["very delicious food.", "not delicious food.", "very very delicious food."]countvectorizer = CountVectorizer()X = countvectorizer.fit_transform(text)result = X.toarray()print(result)
Output

Now, we have three inputs corresponding to our three sentences.
I1 = [1, 1, 0, 1], I2 = [1, 1, 1, 0], I3 = [1, 1, 0, 2]
Step-2: Create three vectors (Key, Query, and Value) from each input vector.
The value of these vectors (Key, Query, and value) is obtained by multiplying the input values with the set of weights. These weights are usually smaller in number and are initialized using a random approximation.
weight_key = [[1, 0, 0], [0, 1, 0], [0, 0, 1], [1, 1, 1]]
weight_query = [[0, 0, 1], [0, 1, 0], [0, 0, 1], [1, 1, 1]]
weight_value = [[1, 1, 1], [0, 1, 0], [0, 0, 1], [1, 0, 0]]
Note:
- These initialization are done before training.
- Dimensions of Query and Key must be the same.
- Dimension of Value can be different from Query and Keys.
Now, find the values of key, query, and value by using matrix multiplication of input value and corresponding weight_query, weight_key, and weight_value.
key = [[1, 1, 0, 1], [1, 1, 1, 0] [1, 1, 0, 2]] x [[1, 0, 0], [0, 1, 0], [0, 0, 1], [1, 1, 1]] = [[2, 2, 1], [1, 1, 1], [3, 3, 2]]
=> key = [[2, 2, 1], [1, 1, 1], [3, 3, 2]]
query = [[1, 1, 0, 1], [1, 1, 1, 0] [1, 1, 0, 2]] x [[0, 0, 1], [0, 1, 0], [0, 0, 1], [1, 1, 1]] = [[1, 2, 2], [1, 1, 1], [2, 3, 3]]
=> query = [[1, 2, 2], [1, 1, 1], [2, 3, 3]]
value = [[1, 1, 0, 1], [1, 1, 1, 0] [1, 1, 0, 2]] x [[1, 1, 1], [0, 1, 0], [0, 0, 1], [1, 0, 0]] = [[2, 2, 1], [1, 2, 2], [3, 2, 1]]
value = [[2, 2, 1], [1, 2, 2], [3, 2, 1]]
Step -3 : Calculate the Attention Scores
The attention score for each input will be calculated separately.
Attention Score = Dot Product of Input Query with all Keys (including itself)
Here, we will show only for input-1
=> Attention Score (for input-1) =[1, 2, 2] x [[2, 1, 3], [2, 1, 3], [1, 1, 2]] = [8, 5, 13]
=> Attention Score (for input-1) = [8, 5, 13]
similarly find the attention score for all the inputs (input-2, and input-3).
Step-4: Calculate Softmax Score using Attention Score
The softmax function (or normalized exponential function) converts a vector of n-real numbers into a probability distribution of n possible outcomes. It is nothing but a generalization of the logistic function to multiple dimensions.
The SoftMax value is calculated using
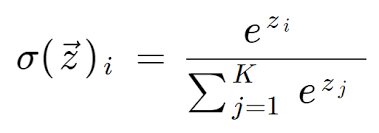
for i = 1, 2, 3, ….K
Step -5: Multiply the Softmax Score with the Values of each input and then sum all the output to get the output
What are the limitations of Transformers?
Although transformers have shown significant improvement in Natural Language Processing (NLP), but it has some limitations.
Here, are some limitations of Transformers:
| Limitations | Descriptions |
| Contextual Understanding | Although transformers are good at understanding the context of a sentence, they have a limited understanding of the overall context. They cannot understand the entire document or conversation in which the sentence is used. |
| Multi-Task Learning | It struggles to perform well on tasks requiring a broad knowledge range or multiple domains. |
| Computationally Expensive | The training of transformer models requires a lot of computing power, which can be costly and time-consuming. |
| Commonsense Reasoning | Transformers can struggle with tasks that require commonsense reasoning or general knowledge outside of the specific task domain. |
| Difficulty with Rare Words | Transformers rely on a pre-trained vocabulary, so they may struggle with rare or unknown words that are not in the vocabulary. |
Conclusion
In this article, we have briefly discussed what transformer is, the architecture of transformer, the working mechanism of encoder and decoder. In the later part we have briefly discussed what is self-attention and its working mechanism with the help of an example.
Hope you will like the article.
Happy Learning!!















FAQs
What is a Transformer?
Transformers are a special type of neural network that was first introduced in 2017 by Vaswani et al. in the Research Paper "Attention is All You Need". And after that, these transformer models became the foundation of many state-of-the-art NLP models. Unlike the traditional Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM), transformers use self-attention that processes the input sequence in parallel, resulting in better scalability and faster training time.
What are the three main components of Transformers?
Transformer has three main components: Encoder, Decoder, and Positional Encoding.
What is Encoder?
Encoder processes input sequences and consists of identical layers. Each layer contains Self-Attention and Feed-Forward Neural Networks.
What is Decoder?
A decoder generates the output sequence, and similar to the encoder, it is also composed of identical layers. Each layer contains Multi-Head Self Attention, Encoder-Decoder Attention, and Feed-Forward Neural Networks.
What is Self-Attention?
Both attention and self-attention are the mechanisms that allow the transformer model to attend to different parts of the input and output sequences when making predictions. Self-attention allows a transformer model to attend to different parts of the same input sequence.
