
XGBoost Algorithm in Machine Learning
The article goes through explaining XGBoost Algorithm in Machine Learning.

XGBoost (Extreme Gradient Boosting) is a powerful tool in machine learning that’s like having a team of experts make predictions together. Think of it like a group of friends helping you decide if a fruit is an apple or an orange based on its colour, size, and shape. Each friend focuses on a specific detail and gives their opinion. XGBoost combines all their opinions to make a super accurate guess. It’s great at many tasks, like guessing movie ratings based on reviews. Just like your friends learn from their mistakes, XGBoost learns and gets better at guessing with each round. Let’s understand.
Explore Online Machine Learning Courses
Contents
- Introduction to XGBoost
- Boosting algorithm: Ensemble Learning
- Types of Boosting Algorithms
- XGBoost Unique Features
- XGBoost Parameters
- Python Implementation of XGBoost Algorithm
XGBoost: An Intro
When it comes to a superfast Machine Learning algorithm that works on tree-based models and tries to reach the best in class accuracy by optimally using computational resources, XGBoost or Extreme Gradient Boosting becomes the most natural choice. Created by Tianqi Chen, the XGBoost algorithm has recently got so much popularity owing to its massive usage in most of the hackathons and Kaggle competitions.
In simple terms, XGBoost may be formally defined as a decision tree-based ensemble learning framework that uses Gradient Descent as the underlying objective function and comes with a lot of flexibility while delivering the desired results by optimally using computational power.

In this article today, we will try to break down in a step-by-step fashion how this sophisticated and advanced ML algorithm works in the real world.
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses

Boosting Algorithm: Ensemble Learning
First of all, XGBoost falls under the boosting suite of algorithms which in turn is part of the ensemble learning method. Now the natural question comes to mind, what is ensemble learning? As discussed in one of our previous articles, the ensemble means a group of musicians. Taking a cue from there, in the machine learning space, ensemble learning simply means learning achieved through a collective effort. In simple terms, ensemble learning means combining multiple models to make predictions work better rather than the outcome from an individual model.
Also read: Ensemble Learning – Boosting
Broadly speaking, there can be two types of ensemble learning.
- Bagging: Also known as Bootstrap Aggregation. This method creates random samples from the main data and then develops parallel models on each data set. The final prediction is done by combining outputs from each individual model. A classic example of a bagging algorithm is the Random Forest algorithm. The bagging process is a parallel process.
- Boosting: Boosting is a sequential process, where each subsequent model attempts to correct the errors of the previous model. The succeeding models are dependent on the previous model. The individual models may not perform well on the entire dataset, but they work well for some parts of the dataset. Thus, each model actually boosts the performance of the previous model and hence the name is appropriate.
Unlike Bagging which works and builds models parallel, boosting works in a sequential manner. Boosting the classifier first builds the base models (or decision trees) by giving equal weights to all the samples and then focuses on correctly classifying the misclassified samples by subsequently looking into them.
The boosting algorithms generally work on three sequential steps as stated below:
- An initial model is built as F1 to predict the target variable y by giving equal importance to all samples
- The predicted outcome of the model is say y1. Error or residuals are estimated as y-y1
- A new model h1 is then built considering the error (y-y1) as the dependent variable
- Finally, a combined model is built using both F1 and h1 to produce a boosted variant of F1 that will result in a reduced error.
These four steps are repeated iteratively until the residuals have been minimized to the desired possible level.
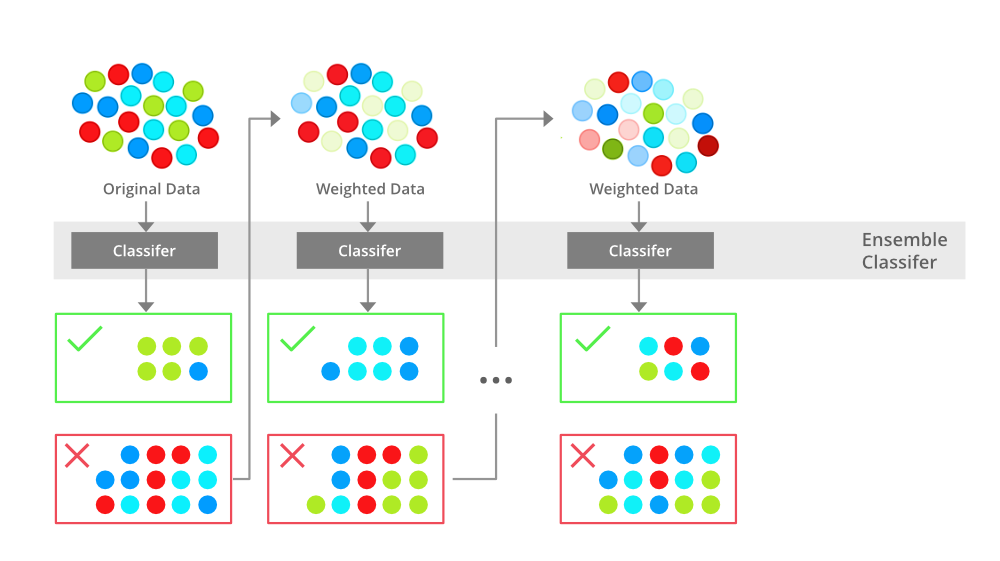
Types of Boosting Algorithms
In a broad sense, there are three major types of boosting algorithm that finds extensive usage in the ML world.
- Adaptive Boosting (Adaboost): It combines the group of weak learner bases to create a strong learner. In the first iteration, it gives equal weight to each data sample. If an incorrect prediction occurs, it gives high weight to that observation. Adaptive Boosting repeats this procedure in the next iteration phase and continues until the desired level of accuracy has been achieved.
- Gradient Boosting (GBM): This boosting algorithm works on the principle gradient descent algorithm. Gradient descent is the backbone of modern machine learning procedures which is defined as an iterative optimization process that helps find a local minimum/maximum of a given function. The given function is actually the loss function and Gradient Descent works in an evolving way to minimize the loss function by finding the optimal parameters for the machine learning problem at hand.
- Extreme Gradient Boosting (XG Boost): As the name suggests, we can think of this algorithm as the GBM with a booster steroid dosage that works most optimally, super-fast way by prudent use of software as well as hardware combinations. It is a scalable and distributed ML framework that works on the foundation of parallel processing of individual tree models used for classification and regression problems.
XGBoost and its Unique Features
XGBoost is a scalable and highly accurate implementation of gradient boosting that pushes the limits of computing power for boosted tree algorithms.
Some unique features of XGBoost:
- Regularization: XGBoost models are extremely complex and use different types of regularization like Lasso and Ridge etc to penalize the highly complex models
- Capability to handle sparse data: XGboost is capable of handling sparse data and hence missing value treatments are not necessary
- Block structures and parallel processing: Unlike many other machine learning algorithms, XGBost can concurrently use multiple cores of the CPU at the same time owing to its block structure in the system design. Because of this capability, XGBoost can work exceptionally faster and can converge well.
- Cache awareness and out-of-core computing: XGBoost has been designed keeping in mind the optimal use of hardware as well. Owing to this property, the algorithm works by allocating internal buffer memories at each step and hence uses the cache in the most efficient way. To add to this, the algorithm, while handling very large datasets in typical big data problems can compress the large data into small versions thus optimizing the disk space and computational speed. This property is termed as ‘out of core’ computation.
- Built-in cross-validation: XGBoots algorithm by its design has the ability to cross-validate models while developing. This reduces the chance of overfitting to a great extent and thus helps in maintaining the bias-variance trade-off.
- Tree pruning: XGBoost makes splits up to the max_depth specified and then starts pruning the tree backward and removing splits beyond which there is no positive gain. This process of backward tree pruning stops XGBoost from being a greedy algorithm and doesn’t result in overfit model.
XGBoost Parameters
A complex machine learning algorithm like XGBoost comes along with a lot of parameters and so the scopes of parameter tuning are also high.
There are broadly three different kinds of parameters
- General Parameters: For overall functioning like the type of model (classification/regression), displaying of the error message, and so on.
- Booster parameters: These are the main sets of parameters that guide individual trees at every step. Some of these booster parameters are listed below:
- Eta: Learning rate
- Max_depth: The maximum depth of the component decision tree
- Max_leaf_nodes: The maximum number of terminal nodes in the decision tree
- Subsample: fraction of observation which is to be selected for random sampling of each tree.
- colsample_bytree: Kind of the maximum number of features. Denotes the fraction of columns to be random samples for each tree.
- Learning task parameters: As the name indicates, these parameters define the optimization objective and the metric (RMSE, MAE, LogLoss, Error, AUC, etc) to be calculated at every step.
Python Implementation of XGBoost Algorithm
We will explore the XGBoost algorithm in Python using the sci-kit learn package.
For that reason, we would take the help of a dataset from the UCI Machine Learning repository. It’s called the “Pima Indians Diabetes Database “.
This dataset is from the National Institute of Diabetes, India. The objective of our XGBoost model would be to predict whether or not a patient has diabetes, based on certain diagnostic measurements such as BMI, insulin level, age, skin, blood pressure, and so on. The dependent variable is a 0/1 binary flag, where 0 stands for a non-diabetic patient and 1 means the patient has diabetes.
More details on the data: https://www.kaggle.com/datasets/uciml/pima-indians-diabetes-database
The first few rows of the data set look like the below:

The entire python code is provided below for quick reference. The code works in the following sequence.
- Reads the data set
- Identifies the independent variables and the dependent variable (diabetic flag:0/1)
- Splits the data into training testing using a 70-30 ratio
- Define the XGBoost model without any specific parameter tuning; i.e. leaving everything as default
- Train the algorithm on the training data set
- Apply the trained model to the testing data set
- Obtain the accuracy (which is 74% in this case)
Code:
\n \n \n <pre class="python" style="font-family:monospace">\n \n \n <span style="color: #808080;font-style: italic">\n \n \n ## Load required libraries:\n \n \n \n \n \n <span style="color: #ff7700;font-weight:bold">\n \n \n import pandas \n \n \n <span style="color: #ff7700;font-weight:bold">\n \n \n as pd\n \n \n \n \n \n <span style="color: #ff7700;font-weight:bold">\n import numpy \n <span style="color: #ff7700;font-weight:bold">\n as np \n \n <span style="color: #ff7700;font-weight:bold">\n from numpy \n <span style="color: #ff7700;font-weight:bold">\n import loadtxt \n \n <span style="color: #ff7700;font-weight:bold">\n from xgboost \n <span style="color: #ff7700;font-weight:bold">\n import XGBClassifier \n \n <span style="color: #ff7700;font-weight:bold">\n from sklearn. \n <span style="color: black">\n model_selection \n <span style="color: #ff7700;font-weight:bold">\n import train_test_split \n \n <span style="color: #ff7700;font-weight:bold">\n from sklearn. \n <span style="color: black">\n metrics \n <span style="color: #ff7700;font-weight:bold">\n import accuracy_score \n \n <span style="color: #ff7700;font-weight:bold">\n import \n <span style="color: #dc143c">\n warnings \n \n <span style="color: #dc143c">\n warnings. \n <span style="color: black">\n filterwarnings \n <span style="color: black">\n ( \n <span style="color: #483d8b">\n "ignore" \n <span style="color: black">\n ) \n \n \n <span style="color: #808080;font-style: italic">\n ## Read diabetes data : \n pima \n <span style="color: #66cc66">\n = pd. \n <span style="color: black">\n read_csv \n <span style="color: black">\n ( \n <span style="color: #483d8b">\n "diabetes.csv" \n <span style="color: #66cc66">\n , header \n <span style="color: #66cc66">\n = \n <span style="color: #ff4500">\n 0 \n <span style="color: #66cc66">\n , names \n <span style="color: #66cc66">\n =col_names \n <span style="color: black">\n ) \n pima. \n <span style="color: black">\n head \n <span style="color: black">\n ( \n <span style="color: black">\n ) \n \n \n <span style="color: #808080;font-style: italic">\n # split data into X and y \n X \n <span style="color: #66cc66">\n = pima. \n <span style="color: black">\n iloc \n <span style="color: black">\n [: \n <span style="color: #66cc66">\n , \n <span style="color: #ff4500">\n 0: \n <span style="color: #ff4500">\n 8 \n <span style="color: black">\n ] \n Y \n <span style="color: #66cc66">\n = pima. \n <span style="color: black">\n iloc \n <span style="color: black">\n [: \n <span style="color: #66cc66">\n , \n <span style="color: #ff4500">\n 8 \n <span style="color: black">\n ] \n \n \n <span style="color: #808080;font-style: italic">\n # split data into train and test sets \n seed \n <span style="color: #66cc66">\n = \n <span style="color: #ff4500">\n 7 \n test_size \n <span style="color: #66cc66">\n = \n <span style="color: #ff4500">\n 0.33 \n X_train \n <span style="color: #66cc66">\n , X_test \n <span style="color: #66cc66">\n , y_train \n <span style="color: #66cc66">\n , y_test \n <span style="color: #66cc66">\n = train_test_split \n <span style="color: black">\n (X \n <span style="color: #66cc66">\n , Y \n <span style="color: #66cc66">\n , test_size \n <span style="color: #66cc66">\n =test_size \n <span style="color: #66cc66">\n , random_state \n <span style="color: #66cc66">\n =seed \n <span style="color: black">\n ) \n \n \n \n <span style="color: #808080;font-style: italic">\n # fit model no training data \n model \n <span style="color: #66cc66">\n = XGBClassifier \n <span style="color: black">\n ( \n <span style="color: black">\n ) \n model. \n <span style="color: black">\n fit \n <span style="color: black">\n (X_train \n <span style="color: #66cc66">\n , y_train \n <span style="color: black">\n ) \n \n \n <span style="color: #808080;font-style: italic">\n # make predictions for test data \n y_pred \n <span style="color: #66cc66">\n = model. \n <span style="color: black">\n predict \n <span style="color: black">\n (X_test \n <span style="color: black">\n ) \n predictions \n <span style="color: #66cc66">\n = \n <span style="color: black">\n [ \n <span style="color: #008000">\n round \n <span style="color: black">\n (value \n <span style="color: black">\n ) \n <span style="color: #ff7700;font-weight:bold">\n for value \n <span style="color: #ff7700;font-weight:bold">\n in y_pred \n <span style="color: black">\n ] \n \n \n <span style="color: #808080;font-style: italic">\n # evaluate predictions \n accuracy \n <span style="color: #66cc66">\n = accuracy_score \n <span style="color: black">\n (y_test \n <span style="color: #66cc66">\n , predictions \n <span style="color: black">\n ) \n \n <span style="color: #ff7700;font-weight:bold">\n print \n <span style="color: black">\n ( \n <span style="color: #483d8b">\n "Accuracy: %.2f%%" % \n <span style="color: black">\n (accuracy * \n <span style="color: #ff4500">\n 100.0 \n <span style="color: black">\n ) \n <span style="color: black">\n ) \n </span style="color: black"> \n </span style="color: black"> \n </span style="color: #ff4500"> \n </span style="color: black"> \n </span style="color: #483d8b"> \n </span style="color: black"> \n </span style="color: #ff7700;font-weight:bold"> \n </span style="color: black"> \n </span style="color: #66cc66"> \n </span style="color: black"> \n </span style="color: #66cc66"> \n </span style="color: #808080;font-style: italic"> \n </span style="color: black"> \n </span style="color: #ff7700;font-weight:bold"> \n </span style="color: #ff7700;font-weight:bold"> \n </span style="color: black"> \n </span style="color: black"> \n </span style="color: #008000"> \n </span style="color: black"> \n </span style="color: #66cc66"> \n </span style="color: black"> \n </span style="color: black"> \n </span style="color: black"> \n </span style="color: #66cc66"> \n </span style="color: #808080;font-style: italic"> \n </span style="color: black"> \n </span style="color: #66cc66"> \n </span style="color: black"> \n </span style="color: black"> \n </span style="color: black"> \n </span style="color: black"> \n </span style="color: #66cc66"> \n </span style="color: #808080;font-style: italic"> \n </span style="color: black"> \n </span style="color: #66cc66"> \n </span style="color: #66cc66"> \n </span style="color: #66cc66"> \n </span style="color: #66cc66"> \n </span style="color: #66cc66"> \n </span style="color: black"> \n </span style="color: #66cc66"> \n </span style="color: #66cc66"> \n </span style="color: #66cc66"> \n </span style="color: #66cc66"> \n </span style="color: #ff4500"> \n </span style="color: #66cc66"> \n </span style="color: #ff4500"> \n </span style="color: #66cc66"> \n </span style="color: #808080;font-style: italic"> \n </span style="color: black"> \n </span style="color: #ff4500"> \n </span style="color: #66cc66"> \n </span style="color: black"> \n </span style="color: black"> \n </span style="color: #66cc66"> \n </span style="color: black"> \n </span style="color: #ff4500"> \n </span style="color: #ff4500"> \n </span style="color: #66cc66"> \n </span style="color: black"> \n </span style="color: black"> \n </span style="color: #66cc66"> \n </span style="color: #808080;font-style: italic"> \n </span style="color: black"> \n </span style="color: black"> \n </span style="color: black"> \n </span style="color: black"> \n </span style="color: #66cc66"> \n </span style="color: #66cc66"> \n </span style="color: #ff4500"> \n </span style="color: #66cc66"> \n </span style="color: #66cc66"> \n </span style="color: #483d8b"> \n </span style="color: black"> \n </span style="color: black"> \n </span style="color: #66cc66"> \n </span style="color: #808080;font-style: italic"> \n </span style="color: black"> \n </span style="color: #483d8b"> \n </span style="color: black"> \n </span style="color: black"> \n </span style="color: #dc143c"> \n </span style="color: #dc143c"> \n </span style="color: #ff7700;font-weight:bold"> \n </span style="color: #ff7700;font-weight:bold"> \n </span style="color: black"> \n </span style="color: #ff7700;font-weight:bold"> \n </span style="color: #ff7700;font-weight:bold"> \n </span style="color: black"> \n </span style="color: #ff7700;font-weight:bold"> \n </span style="color: #ff7700;font-weight:bold"> \n </span style="color: #ff7700;font-weight:bold"> \n </span style="color: #ff7700;font-weight:bold"> \n </span style="color: #ff7700;font-weight:bold"> \n </span style="color: #ff7700;font-weight:bold"> \n </span style="color: #ff7700;font-weight:bold">\n \n \n </span style="color: #ff7700;font-weight:bold">\n \n \n </span style="color: #ff7700;font-weight:bold">\n \n \n </span style="color: #808080;font-style: italic">\n \n \n </pre class="python" style="font-family:monospace">

For More, avail: Top Machine Learning Courses and Certifications
Endnotes:
We have discussed the overall concept of the XGBoost algorithm here in this article. We have tried to understand the complex mechanics and model development principle behind this algorithm in a step-by-step fashion. Needless to say, as stated earlier as well, XGBoost is one of the most used and talked about algorithms in ML space owing to its very flexible nature and capability to handle large datasets with super-efficient computational power. Like all machine learning procedures, XGBoost may also suffer from over or under-predictability. Proper underlying data treatment and effective model hyperparameter tuning may help to avoid the chances of over and underfitting and may result in the optimal functioning of the model.
Top Trending Tech Articles:Career Opportunities after BTech Online Python Compiler What is Coding Queue Data Structure Top Programming Language Trending DevOps Tools Highest Paid IT Jobs Most In Demand IT Skills Networking Interview Questions Features of Java Basic Linux Commands Amazon Interview Questions
FAQs
What is XGBoost and what does it stand for?
XGBoost stands for Extreme Gradient Boosting. It's a machine learning algorithm known for its predictive accuracy and versatility.
How does XGBoost work?
XGBoost works by combining the predictions of multiple simple models (usually decision trees) to create a more accurate and powerful model. It learns from the mistakes of these individual models and improves its predictions over time.
What makes XGBoost different from other algorithms?
XGBoost uses a technique called gradient boosting that helps it make better predictions by focusing on the mistakes made by previous models in the ensemble.
What types of problems can XGBoost solve?
XGBoost can handle various types of problems, including classification (e.g., spam detection), regression (e.g., predicting prices), and ranking (e.g., recommendation systems).
Is XGBoost suitable for large datasets?
Yes, XGBoost is designed to handle large datasets efficiently. It's optimized for both speed and memory usage.

This is a collection of insightful articles from domain experts in the fields of Cloud Computing, DevOps, AWS, Data Science, Machine Learning, AI, and Natural Language Processing. The range of topics caters to upski... Read Full Bio