
Confusion Matrix in Machine Learning
Are you tired of your AI models getting confused? Untangle their mysteries with the Confusion Matrix, your secret weapon for accuracy! Decode True Positives, False Negatives, and more to uncover hidden patterns and unleash the full potential of your machine-learning projects.

Table of Contents
- Why confusion matrix?
- Important Terms
- Model Performance – How to evaluate your model
- Confusion matrix python
- Endnotes
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses

What is Confusion Matrix and why it is needed?
The number of predictions (correct and incorrect) is summarized with a count value in a matrix, by each class.
A confusion matrix summarises correct and incorrect predictions and helps visualize the outcomes.
Confusion Matrix is a simple technique for checking the performance of a classification model for a given set of test data.
After this blog, you can answer the following questions:
- What is the confusion matrix and why do we need it?
- How to calculate Confusion Matrix for classification problems?
Let’s understand it step by step.
We make a machine learning model for classification and regression (prediction). So, after making the model, we check whether our model is performing well or not. In simple language, we want to check whether our newly built model is classifying/predicting correctly or not. For checking that we have to find the accuracy of the model. And confusion matrix(performance metric) that could be use.
Also, explore: Popular Machine Learning Courses.
Summarized points
- The confusion matrix tells about the correct and incorrect predictions.
- Helps us with performance metrics like precision, recall, and F1 score, in addition to accuracy.
The confusion matrix mainly deals with two values: Actual and Predicted values. Actual values are simply the values from our data. Predicted values are the values predicted by our Machine Learning model.
Let’s understand this with a confusion matrix example.
Also read: Machine Learning Online Courses & Certifications
Confusion matrix example
Problem statement: Prediction of Corona patients
Let us assume that our model is trying to predict Corona patients. That model performance is calculated by using this 2×2 matrix.

Fig 2×2 Confusion Matrix real example
Let’s understand TP, FP, FN, and TN regarding Coronavirus affected people analogy.
- True Positive:
-
-
- Interpretation: You predicted positive, and it’s true.
- You predicted that a person is Corona positive, and he actually is having Corona.
-
- True Negative:
-
- Interpretation: You predicted negative and it’s true.
- You predicted that person is Corona negative, and he actually does NOT have Corona.
- False Positive: (Type 1 Error)
-
- Interpretation: You predicted positive and it’s false.
- You predicted that that person is Corona positive but he actually was NOT having Corona.
-
- False Negative: (Type 2 Error)
-
- Interpretation: You predicted negative and it’s false.
- You predicted that person is Corona negative but actually he was Corona positive.
Other Important Terms using a Confusion Matrix
Let’s understand it by taking the above example into consideration.
- ROC Curve: Roc curve is a graph between the true positive rates against the false positive rate at various cut points. It also shows a trade-off between recall and specificity or the true negative rate.
- AUC (Area Under the Curve): AUC is the measure of the ability of a classifier to distinguish between positive and negative classes
- Precision: The precision metric checks the prediction accuracy of the positive class.
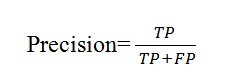
Fig Precision
For e.g Precision= 560/560+60 =>560/620 =>0.8
Here 0.8 means 80% precision. This means 80% of the positives were identified correctly.
You can see Precision ignores the negative class completely and takes only the positive class into account, so it is not very helpful alone. When the classifier perfectly classifies all the positive values, the Score is ‘1’ in that case.
- Accuracy: The accuracy in the confusion matrix tells about the correctly classified values. It tells us how accurately our classifiers are performing. It is the sum of all true values(TP and TN) divided by a total number of values.
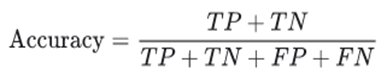
Fig Accuracy
For e.g Accuracy=560+330/560+330+60+50 =>890/1000 =>0.89 =>89% accuracy.
This means 89% of values(TP+TN) were correctly classified by the model.
- Recall/Sensitivity: Sensitivity computes the ratio of positive classes correctly detected, which means the number of correct results divided by the number of results.
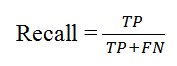
Fig Recall
For .eg. Recall=560/560+50 =>560/610 => 0.918
This means 91.8% of actual positive values were correctly classified.
- Specificity: Specificity is the proportion of actual negatives that were correctly predicted.
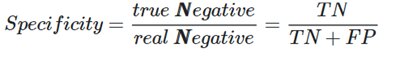
Fig Specificity
For e.g.: 330/330+60 => 330/390 =>0.84
This means 84 % of actual negative values were correctly classified.
- F1 Score: The F1 score is a harmonic mean of precision and recall.
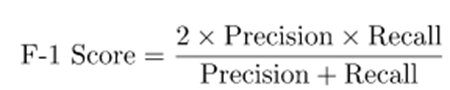
Fig F1 score
For e.g. F1 Score => 2 x 0.83×0.91/0.83+0.91 => 1.51/1.74 =>0.86
F1 Score shows the balance between precision and recall.
Model Performance – How to evaluate your model
Precision => How much positive identification was identified correctly?
Recall => What proportion of actual positives was identified correctly?
Let’s continue with the same analogy of Corona patients.
Precision recall Confusion Matrix
Suppose our model is detecting corona patients.

Scenario1:
- A patient is not suffering from corona but is declared corona positive by the model.
- This shows that our model has a high false-positive (fp) rate.
- When the false positive rate is more important for solving a classification problem, then precision is suggested.
Scenario2:
- The classification model could not detect the corona-positive patients and declare them fit to move freely.
- That situation shows our model has a high false-negative rate.
- When the false-negative rate is more important according to our classification problem, then recall is suggested.
F1 score Confusion Matrix
Achieving high precision and high recall is not possible at the same time. When that type of situation comes, when we need a high detection rate and both recall and precision are important, we should use the F1 score.
The next question is when not to use Accuracy.
There are two problems because of which why accuracy is not preferred sometimes:
- High accuracy can be achieved in the case of a multiclass classification problem, but that could be because the model has not neglected some of the classes.
- In case of a multiclass problem, you may achieve very good accuracy i.e. 90% or more, but this is not a good score if 90 records out of every 100 belong to one class.
So just using accuracy is not preferred.
Multi-class classification, as well as binary classification, is shown.
There is a column Type that has two classes Pet and Stray. In this, Pet appeared more than a stray. That means it is imbalanced data.
So now, if only Accuracy is insufficient to check our model, what’s the solution? In these types of scenarios, we should use the Confusion Matrix.
Confusion matrix python
Now let’s discuss briefly its implementation.
-
Importing Libraries and reading file
- Firstly we imported libraries like pandas, seaborn,matplotlib, and NumPy.then we uploaded ‘heart.csv’.It includes 303 rows × 14 columns.
2. Importing Logistic Regression model and train_test _Split
- After splitting the dataset we have to implement the machine learning model. In this example, Logistic regression is applied

- 3. Applying Logistic Regression model and fitting the model
4. Confusion Matrix

Endnotes
In this article, we covered
- Confusion Matrix with a real-life example.
- These are terms related to the Confusion Matrix (with calculations).
- Scenarios for using a confusion matrix.
- Implementing Confusion Matrix in Python.
I hope this article will help you. If you like it, please support me by liking and commenting on it. If you are interested in entering the data science field, you can find different study materials on this page.
Also read:

 Read Later
Read Later















