
Data Cleaning In Data Mining – Stages, Usage, and Importance
In today's digital world, a massive amount of data is generated every second. We're talking about 9,000 tweets, 900 Instagram photos, 80,000 Google searches, and 3 million emails - all happening within the blink of an eye. Not all of this data is neat and ready to use. This is where data scientists come in. Their job is to sort through this data mess and clean it up, like tidying up a cluttered room. Data cleaning is like removing the dust and making everything neat and organized. Clean data is essential for accurate analysis and getting meaningful insights. Let us learn more about data cleaning in data mining.
A number of surveys conducted with data scientists suggest that around 80% of their work time is focused on obtaining, cleaning, and organizing the data, while only 3% of the time is dedicated to building machine learning or data science models.
To learn more about data mining, read – What is Data Mining
What is Data Cleaning in Data Mining?
Data cleaning is the detailed process of removing any incomplete, incorrect, or inconsistent detail from the data set. There is no single defined way to clean such data and the process differs from data to data. Usually, data scientists establish and follow a set of data cleaning steps that may have historically worked for them and obtain the correct results by removing the corrupted, incorrectly formatted, duplicate, or mislabeled data.

 Read Later
Read Later
Best-suited Data Mining courses for you
Learn Data Mining with these high-rated online courses

Stages of Data Cleaning in Data Mining
Data cleansing is to have a better organization of the data of the company or business, being able to take advantage of this information in an efficient way for the planning of strategies. Below are some of the different data cleaning processes in data mining –
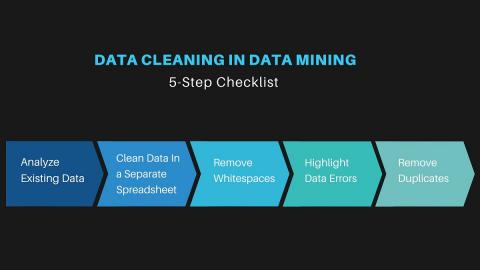
Analyze Existing Data
The first thing to do in a data cleansing is to analyze the existing data and determine the faults that need to be eliminated. This stage must combine a manual and an automatic process to ensure the process. In other words, in addition to making an exhaustive review of the data manually, it is important to use specialized programs to detect erroneous metadata or information problems.
Clean Data In A Separate Spreadsheet
Make a copy of your data set on a spreadsheet before you make any final changes. This is a preventive step in case your data set gets corrupted by any chance.
Remove Any Whitespaces from the Data
Whitespaces or extra spaces often lead to miscalculations, which is a very common issue when handling huge databases. One example to understand it better – “This is a Dog” and “This is a Dog” will be considered as different data. You can use the TRIM function to get rid of such undesired spaces.

Highlight Data Errors
It is possible that you don’t get an error-free data set considering the huge volumes. Values like #N/A, #VALUE, etc. appear often in raw data. Using the IFERROR operator and assigning a default value to the field in case of any errors in calculation can be a useful step in your data cleaning process.
Remove Duplicates
Duplicate entries are very common. You must go to “Conditional Formatting” on your MS Excel and choose ‘Remove Duplicates’ to remove any duplicate entries.
Use Data Cleansing Tools
Data Cleansing Tools can be very helpful if you are not confident of cleaning the data on your own or have no time to clean up all your data sets. You might need to invest in those tools, but it is worth the expenditure!
Must Explore – Data Mining Courses
Usage of Data Cleaning in Data Mining
Let’s understand what is the use of data cleaning in data mining.
Data Integration
Since it is difficult to ensure data quality in low-quality data, data integration has an important role to play to solve this problem. Data Integration is the process of combining data from different data sets into a single one. This process uses data cleansing tools to ensure that the embedded data set is standardized and formatted before it moves to the final destination.
Data Migration
Data migration is the process of moving one file from one system to another, one format to another, or one application to another. While the data is on move, it is important to maintain its quality, security, and consistency, to ensure that the resultant data has the correct format and structure without any delicacies at the destination.
Data Transformation
Before the data is uploaded to a destination, it needs to be transformed. This is only possible through data cleaning, which considers the system criteria of formatting, structuring, etc. Data transformation processes usually include using rules and filters before further analysis. Data transformation is integral to most data integration and management processes. Data cleansing tools help to clean the data using the built-in transformations of the systems.
Data Debugging in ETL Processes
Data cleansing is crucial in preparing data during extract, transform, and load (ETL) for reporting and analysis. Data cleansing ensures that only high-quality data is used for decision-making and analysis. For example, a retail company receives data from various sources, such as a CRM or ERP system, that contain misinformation or duplicate data. A good data debugging or debugging tool would detect inconsistencies in the data and rectify them. The purged data will be converted to a standard format and uploaded to a target database or data warehouse.


Importance of Data Cleaning in Data Mining
Data cleaning is mandatory to guarantee the business data's accuracy, integrity, and security. Based on the qualities or characteristics of data, these may vary in quality. Here are the main methods of data cleaning in data mining:
Accuracy
All the data that make up a database within the business must be highly accurate. One way to corroborate their accuracy is by comparing them with different sources. If the source is not found or has errors, the stored information will have the same problems.
Coherence
The data must be consistent with each other, so you can be sure that the information of an individual or body is the same in different forms of storage used.
Validity
The stored data must have certain regulations or established restrictions. Likewise, the information has to be verified to corroborate its authenticity.
Uniformity
The data that make up a database must have the same units or the same values. It is an essential aspect when carrying out the Data Cleansing process, since if it does not increase the complexity of the procedure.
Data Verification
The process must be verified at all times, both the appropriateness and the effectiveness of the procedure. Said verification is carried out through various insistence of the study, design, and validation stages since, many times the drawbacks are evident after the data is applied in a certain amount of changes.
Clean Data Backflow
After the elimination of quality problems, the already clean data must be replaced by those not located in the original source so that legacy applications obtain the benefits of these, obviating the need for actions of data cleaning afterwards.


Conclusion
Poor data can lead to poor business strategy and decision-making. This is because businesses are spending money on data cleaning and are inculcating a culture of quality data management. Regardless of the strategy you follow for data cleaning in data mining, a series of practices must be implemented as routine. Ideally, actions are proposed at 2 different levels, one that acts early by correcting data from the same source and preparing it for proper integration, and another that acts with data problems from different sources. To ensure a proper methodology, it is convenient that the ETL processes are defined, introducing them in a precise framework.

Rashmi is a postgraduate in Biotechnology with a flair for research-oriented work and has an experience of over 13 years in content creation and social media handling. She has a diversified writing portfolio and aim... Read Full Bio