
Hyperparameter Tuning: Beginners Tutorial

When creating a machine learning model, you will have choices to define your model architecture. We can design our model manually or can take the help of a machine to perform this exploration and select the optimal model architecture automatically. The parameters define the model architecture and these parameters are referred to as hyperparameters then the ideal model is searched and this process of searching is referred to as hyperparameter tuning.
Table of contents
In the previous blogs, we learned about how to evaluate and improve the machine learning model. And now we will see how to increase accuracy by tuning the model parameters. In this blog, we will be learning very interesting and very confusing terms parameters, and hyperparameters.
Best-suited Machine Learning courses for you
Learn Machine Learning with these high-rated online courses

What is the difference between parameter and hyperparameter?
To understand, hyperparameter we should be knowing what is a parameter.
The model parameters specify how to transform the input data into the desired output, the hyperparameters define how our model is actually structured.
Model parameters are learned during training when we optimize a loss function. Hyperparameters are parameters of a model that define the model’s architecture that does not change with your model training and also they are not learned as part of training.
Note: Hyperparameters are different for different models.
For understanding this let’s say you have a neural network in which the weights and biases are called parameters while training the neural network you need to specify the number of neurons in the hidden layer how many layers you want how many epochs you want to train it on all of these are called hyperparameters
| Parameter | Hyperparameter |
| 1. Parameters are the ones that the “model” uses to make predictions etc. | 1. Hyperparameters are the ones that help with the learning process. For example, a number of clusters in K-Means, shrinkage factor in Ridge Regression. |
| 2. Learned during training | 2. Have to specify manually |
| 3. For e.g. Weights and Biases | 3. For e.g. number of clusters in K-Means, Input features, number of hidden Nodes and LayersLearning Rate, activation Function, etc in Neural Network |
Let us quickly see some examples for different algorithms
- Linear Model: Degree of polynomials
- Decision Tree: Max depth, Min Leafs
- Random Forest: # Trees,#Features
- Neural Networks: # Layers,#Neurons
- Optimizer: Learning Rate, Momentum
Why hyperparameter tuning is required?
Normally people just implement the model and see the accuracy. And they don’t do hyperparameter tuning. In that case, your default values of all hyperparameters will be taken. But you have to ensure that the hyperparameter values should be suitable for the dataset we have? So we should tune our hyperparameter values accordingly in order to get good accuracy. Plus with the changing data, we have to tune our parameters also.
Scenario example: Imagine a situation that you have deployed the model in some company. And after some time you start getting complaints related to accuracy. The reason was a change in data. And with a change in data, you may have to change your model and have to hyper-tune the parameters. So you have to continuously check the performance of the model and modify the hyperparameters for better performance.
Note: If this tuning process is not carried out (e.g., default values are used), then machine learning algorithms may not perform as well.
Hyperparameter optimization definition
Hyperparameter optimization is the process of finding the right combination of hyperparameter values to achieve maximum performance on the data in a reasonable amount of time.
We know the importance of hyperparameter optimization till now. But now a question comes to mind ‘there are different parameters for the different algorithms do we have to remember the best value of all?’ The answer to this question is that you should have an understanding of the parameters. You can choose parameters according to your requirement and can assign the values. You can change the values accordingly to achieve good accuracy. This process is called hyperparameter optimization.
Hyperparameter tuning helps
- Find the optimal solution space(global Vs local minima)
- Find the right capacity for your solution(overfit and underfit)
- Identify ideal architecture
- Speed of convergence
- Generalize your model for production
Basic Hyperparameter Tuning Techniques
We have different techniques for doing hyperparameter tuning. But GridSearchCV and RandomizedCV are mostly used which we will discuss in this blog.
1. Manual Search
Changing the parameter value on the basis of gut feeling and experience
Manual search means selecting some hyperparameters for a model based on our gut feeling and experience. So the model is trained, and the model’s performance is checked. This process of changing the hyperparameter values is repeated with another set of values until optimal accuracy is received.
As human judgment is biased so this might not work well in every case, and it will vary with here human experience
2. GidsearchCV
Try all combination. So takes more computation time
We have many available parameters for any particular algorithm. We can search the best parameters from a grid of hyperparameters values by using GridSearchCV.
For example, if we want to set two hyperparameters A and B of the Random Forest Classifier model, with a different set of values. Then many versions of the model with all possible combinations of hyperparameters will be constructed by the GridSearchCV technique and will return the best one. Then it is obvious that if all the combinations are tried, then they have more computational cost. More execution time. This approach is the most straightforward leading to the most accurate predictions.

3. RandomizedSearchCV
Try random combination. So takes less computation time
The drawbacks of GridSearchCV are solved by RandomizedSearchCV, as it does not try all combinations instead goes only through a fixed number of hyperparameter settings. It moves within the grid in a random fashion within the ranges that you specify for hyperparameters for each training job it launches, to find the best set of hyperparameters. This approach obviously reduces unnecessary computation. Till the desired accuracy is not reached the searching process continues. The purpose of random search and grid search is the same but has proven to create better results than the latter. Though random search is more effective than grid search, it is still a computationally intensive method.
Smart hyperparameter tuning picks a few hyperparameter settings, evaluates the validation matrices, adjusts the hyperparameters, and re-evaluates the validation matrices. Examples of smart hyper-parameter are Spearmint (hyperparameter optimization using Gaussian processes) and Hyperopt (hyperparameter optimization using Tree-based estimators).
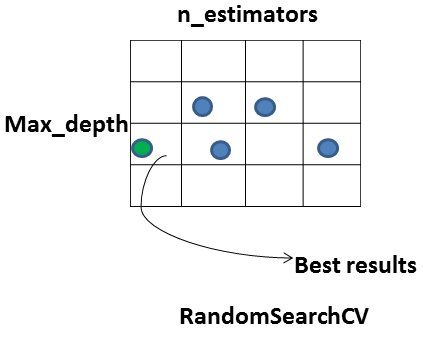
Note: These both techniques work best with small datasets
Working of GridSearchCV and RandomSearchCV
Let’s understand this with an example.
Suppose we have four areas A, B, C, and D each having population of 1 lack each. And you want to search for a person named John. If you apply a grid, it will check every area(sequentially or randomly). On the other hand, if you will execute RandomSearchCV, it will check by picking the areas randomly and start searching.RandomSearchCV will narrow down the results and tell that john could be on areas B and C. Now after getting the idea of the probable area you can apply GridSearchCV to thoroughly check all the combination in area B and C. So these two techniques works the same for finding the best parameters. So in my opinion executing RandomSearchCV first and then GridSearchCV will save time. The rest depends on the algorithm you are using.Still there is no hard and fast rule.
Difference between GridSearchCV and RandomSearchCV
| GridSearchCV | RandomSearchCV |
| 1. It takes a lot of time to fit (because it will try all the combinations) | 1. It is faster because all parameters are tried out |
| 2. Gives us the best hyper-parameters. | 2. It doesn’t guarantee the best parameters |
| 3. This is the most efficient method as there is the least possibility of missing out on an optimal solution for a model | 3. The performance is may slightly worse for the randomized search and is likely due to a noise effect |
Endnotes
It is always recommended to compare the performances of Tuned and Untuned Models. This will cost us more time but will surely give us the best results in terms of performance metrics. In the coming blog, we will study these techniques with python code.
If you liked this blog consider hitting the stars below for my motivation.

This is a collection of insightful articles from domain experts in the fields of Cloud Computing, DevOps, AWS, Data Science, Machine Learning, AI, and Natural Language Processing. The range of topics caters to upski... Read Full Bio