If you ever faced a Data Science interview you must have faced this question: What is overfitting and underfitting in Machine Learning?
This is a very important topic from an interview point of view. Or some of you working on machine learning models must have experienced the situations when your model gives very good accuracy on training data but gives bad accuracy on testing data.
Moreover, it can be quite frustrating when we are unable to find the solution to this anomalous behavior of the predictive model, we are working on. Let’s rectify that, shall we?
In this blog you will learn about:
Overfitting underfitting and a good fit model with relatable examples.
Reason of Overfitting underfitting and how to tackle it.
Overfitting refers to a scenario when the model tries to cover all the data points present in the given dataset. As a result, the model starts caching noise and inaccurate values present in the dataset and then reduces the efficiency and accuracy of the model.
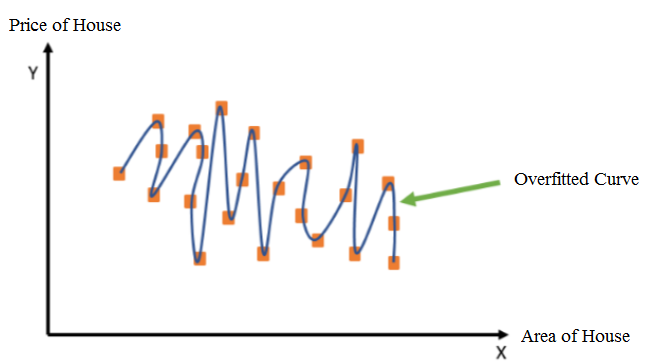
When a model performs very well for training data but gives a poor performance with test data (new data), it is known as overfitting. Performing very well means giving very good accuracies during training and less accuracy when checked on testing data. Overfitting happens when the model learns the detail and noise in the training data which ultimately leads to negative impacts on the performance of the model on new data. This is because the data model becomes more complex with the presence of noise in a data set. The noise here means irrelevant or meaningless data like outliers, missing values, and extra features. So model picks up noise or random fluctuations in the training data and learns them as concepts. The model fits all the data points so well that noise is interpreted as patterns in the data as shown in the figure.
Scenario example:
Example-1
Suppose a student is preparing for an exam and has studied all non-exam topics in books( which have no relevance with the exam). He then becomes overwhelmed with learning things that are irrelevant from an exam standpoint (noise). And he also learns things by heart. What happens then? He will do well in class. Even if you ask him exactly what he has practiced, he will not do well if you ask him an applied question in a test that requires him to apply his knowledge. It doesn’t work well with data.
Example-2
Suppose we have data regarding price of house with respect to area of house.The points shown in the diagram are data points. As you can see, the line is passing through different data points. The data points covered by this line are training data.This clearly shows that the model is overfitted.
Chances of Overfitting are more with nonparametric and nonlinear models that have more flexibility when learning a target function.
For example, decision trees(nonparametric algorithms) are very flexible and are subject to overfitting training data.
If your model performs perfectly well on your train set and fails badly on the test set or validation set in most cases that indicate that the model is overfitting. Practically if you see that your model performs extremely well at your training set, like > 90-95% accuracy, most probably you already facing overfitting …staying below 75–80% – underfitting.
If you want to know how to handle missing values and how to handle categorical data:
Underfitting is just the opposite of overfitting. In overfitting, the model was trying to learn everything(including noise data) and in underfitting, the machine learning model is not able to capture the underlying trend of the data.
In some cases when the overfitting scenario starts, the fed of training data should be stopped at an early stage, because of which the model may not learn enough from the training data. As the training data was not enough, the model may fail to find the best fit of the dominant trend in the data. Hence the accuracy is reduced and will produce unreliable predictions.
Scenario example: It is the same as you are giving less study material to the student. So he is not trained properly and will not be able to perform well in exams. Now, what is the solution? The solution is very simple, train the student well.
Underfitting can be easily detected by performance metrics. And it can be easily tackled by trying different machine learning algorithms.
So from this example, we can conclude that that model is not performing well on train data as well as test data.
Reasons for Underfitting
Uncleaned data(contains noise) used for training is not cleaned
High bias in the model.
Less training data
The model is too simple
Ways to Tackle Underfitting
Preprocessing the data to reduce noise in data
More training to the model
Increasing the number of features in the dataset
Increasing the model complexity
Reduce noise in the data
Now that you have understood what overfitting and underfitting are, let’s see what is a good fit model in this tutorial on overfitting and underfitting in machine learning.
What is a good fit model?
A good fit model is a balanced model, which is not suffering from underfitting and overfitting. This is a perfect model which gives good accuracy score during training and equally performs well during testing.
It is not easy to get a perfect model. You will not get the perfect fit model in one go. You have to try different models to finally get a good fit model. Plus you have to check the performance of a machine learning model over time with respect to the training data.
Points to remember
With training, the error for the model on the training and testing data is reduced.
But a model shouldn’t be trained too long also as it will learn the unnecessary details and the noise in the training set and which will lead to overfitting.
Training should be stopped at a point where the error starts to increase.
Summary
Overfitted model performance
Training testing
The accuracy score is good and high during training but it decreases during testing.
Underfitted model performance
Training
testing
The accuracy
the score is low during training as well as testing.
A good fit model performance
Training testing
The accuracy score is good during training as well as testing.
To find a good fit model, you need to look at the performance of a machine learning model over time with the training data. As the algorithm learns over time, the error for the model on the training data reduces, as well as the error on the test dataset. If you train the model for too long, the model may learn the unnecessary details and the noise in the training set and hence lead to overfitting. In order to achieve a good fit, you need to stop training at a point where the error starts to increase.
Let’s understand it with a real-life example. Assume you want the model to predict a ball.
Scenario 1: Now you have to train the model first and you trained the model with only one feature i.e Is_circle.This attribute is checking if the shown object is of a circle shape.
Now let’s suppose after training you showed orange to the model. As you told the model anything in the circle will be a ball. So it will predict orange as a ball.
Why do you think our model is predicting so wrong? This is because we trained it on fewer data(an under-fitted model).
Scenario 2: Now in order to avoid we have given more features like:
Sphere-This feature is checking if the object is of a spherical shape
Play-This feature is checking if one can play with it
Eat-This feature is checking if one cannot eat it.
radius=5 cm-This feature is checking if an object’s size is 5 cm or less than it.
Now we experimented by showing a basketball to the model.
We did not expect these results. Unlike the previous scenario, we provided more attributes this time. But what went wrong here? Here we provided more attributes/more knowledge to the model. The model checked all the features one by one. On checking the model found all the features are ok except one feature i.e radius=15 cm. We showed it a basketball whose radius is more than 5 cm. So model says the object shown is not a ball.
Sphere
Play
Eat
radius=5 cm-
Note: The model is trying to cover all the points including the specific value of radius given to it. So in this case the model is overfitted.
Endnotes
I hope you understood these concepts. I tried making my point clear by giving scenario-based/real-life examples. In this blog, you learned about overfitting underfitting, and a good fit model. And also the reasons for overfitting and underfitting and the ways to handle it.
If you like this blog, please hit the like button below and share it so that other data science aspirants also get benefit from it. If you want to learn machine learning with programming then you can follow my blogs on this link.
This is a collection of insightful articles from domain experts in the fields of Cloud Computing, DevOps, AWS, Data Science, Machine Learning, AI, and Natural Language Processing. The range of topics caters to upski Read Full Bio
Nice post. I learn something new and challenging on websites I stumbleupon on a daily basis. It will always be exciting to read content from other authors and practice something from other sites.
a Web Designing Training in Bangalore/a
a Web Designing Course in Bangalore /a
a Front End Development



 Read Later
Read Later













